
通过端到端的文字识别训练算法组件获得的训练模型,能够检测识别任意角度、任意形状的文字。本文介绍端到端的文字识别训练算法组件的配置方法及使用示例。
前提条件
已开通OSS并完成授权,详情请参见开通OSS服务和PAI访问云产品授权:OSS。
使用限制
仅PAI-Designer提供该算法组件。
算法简介
端到端文字识别算法是PAI团队自研的OCR算法,该算法能够检测识别任意角度、任意形状的文字,并且提供基于阿里巴巴的大数据进行训练的预训练模型,您只需要提供几百到1000张图片即可完成对应场景的文字检测识别。
端到端的文字识别训练组件位于组件库音视觉算法文件夹下的离线训练模型子文件夹。
可视化配置组件
- 输入桩
输入桩(从左到右) 限制数据类型 建议上游组件 是否必选 训练数据 OSS 数据转tfrecord 否。 如果没有通过输入桩配置该参数,也可以在字段设置页签的训练数据文件oss路径参数中配置。
评估数据 OSS 数据转tfrecord 否。 如果没有通过输入桩配置该参数,也可以在字段设置页签的评估数据oss路径参数中配置。
- 组件参数
页签 参数 是否必选 描述 默认值 字段设置 训练所用oss目录 是 存储训练模型的OSS目录,例如 oss://pai-online-shanghai.oss-cn-shanghai-internal.aliyuncs.com/test/test_video_cls。无 训练数据文件oss路径 否 如果没有通过输入桩配置算法组件的训练数据,则需要配置该参数,表示tfrecord格式的训练数据文件所在的OSS路径,支持通配符,例如 oss://a/train*.tfrecord。如果同时通过输入桩和该参数配置了算法组件的训练数据,则优先使用输入桩配置的输入。
无 评估数据oss路径 否 如果没有通过输入桩配置算法组件的评估数据,则需要配置该参数,表示tfrecord格式的评估数据文件所在的OSS路径,支持通配符,例如
oss://a/test*.tfrecord。如果同时通过输入桩和该参数配置了算法组件的评估数据,则优先使用输入桩配置的输入。
无 是否使用预训练的模型 否 建议使用预训练模型,以提高训练模型的精度。 是 预训练模型oss路径 否 如果有自己的预训练模型,则将该参数配置为自己预训练模型的OSS路径。如果没有配置该参数,则使用PAI提供的默认预训练模型。 无 参数设置 检测模型使用的backbone 否 识别模型的网络名称,系统支持如下主流的识别模型: - resnet_v1_50
- resnet_v1_101
resnet_v1_50 检测类别数目 否 分类类别的数量。 从数据集中分析得到 anchor尺度 否 anchor框的大小,与Resize后的输入图片在一个尺度,因此设置大小时参考输入图片Resize后的大小。 该参数目前只支持填写一个值,表示分辨率最高Layer的anchor大小,一共有5个Layer,后面每个Layer的anchor大小为前一Layer的2倍。例如32, 64, 128, 256, 512。
24 anchor宽高比 是 anchor宽高比,多个值之间使用空格分隔。 0.2 0.5 1 2 5 是否预测文字行朝向 否 选中是否预测文字行朝向复选框时,表示对文字行朝向进行预测,反之不进行预测。 是 是否训练文字行朝向预测 否 选中是否训练文字行朝向预测复选框时,表示对文字行朝向进行训练,反之不进行训练。如果标注数据时您标注了文字方向,就可以选择对其进行训练。 是 文字行朝向预测方式 否 系统支持以下预测方式: - normal:贪婪预测文字行方向。
- unified:预测时将所有文字行朝向进行投票,得到统一的文字行方向。
- smart_unified:预测时,去除高大于宽两倍的文字行朝向,将剩余文字行朝向进行投票,得到统一的文字行方向。
normal 文字行特征抽取器类型 否 系统支持以下类型: - fixed_height:表示固定高度特征提取。
- fixed_size:表示固定宽高特征提取。
- fixed_height_pyramid:表示固定高度金字塔。
fixed_height 文字行的宽高比 否 根据文字行特征抽取器类型的不同,文字行宽高比的含义如下: - 当文字行特征抽取器类型为fixed_size时,表示特征被Resize后的宽高比。
- 当文字行特征抽取器类型为fixed_height时,表示特征Resize的最大宽高比约束。
- 当文字行特征抽取器类型为fixed_height_pyramid时,表示固定高度缩放,但是特征使用多级金字塔特征。
40.0 识别分支的训练batch_size 否 文本行识别模型部分训练的批大小。 160 识别分支中的norm类型 否 表示不同的归一化方式,支持以下取值: - batch_norm
- group_norm
group_norm 编码器中的cnn类型 否 系统支持以下类型,您需要结合模型使用的backbone进行选择: - conv5_encoder:使用Resnet结构时选择该类型。
- senet5_encoder:使用Se-Resnet结构时选择该类型。
senet5_encoder 编码器层数 否 通常指RNN或Attention层数,CNN不计算在内。 2 编码器中RNN的类型 否 系统支持以下RNN类型: - bi:双向rnn encoder
- uni:单向rnn encoder
uni 编码器中隐藏层神经元数目 否 编码器中隐藏层的神经元数量。 512 编码器中rnn cell类型 否 编码器中RNN Cell类型,支持以下取值: - basic_lstm:lstm
- layer_norm_basic_lstm:lstm加layernorm
- gru
- nas
basic_lstm 解码器类型 否 解码器类型,支持以下取值: - attention::attention decoder
- ctc:ctc decoder
attention 解码器层数 否 解码器的层数。 2 解码器中隐藏层神经元数目 否 解码器中隐藏层的神经元数目。 512 解码器中的rnn cell类型 否 解码器中RNN Cell类型,支持以下取值: - basic_lstm:lstm
- layer_norm_basic_lstm:lstm加layernorm
- gru
- nas
basic_lstm 字典的embedding大小 否 字典的Embedding大小。 64 beam_width 否 Beam Search中的Beam Width。 0 length_penalty_weight 否 Beam Search中的Length Penalty,用于避免短序列倾向。 0.0 解码器中的attention类型 否 解码器中的Attention类型,支持以下取值: - luong
- scaled_luong
- bahdanau
- normed_bahdanau
normed_bahdanau 图片缩放后的最短边大小 是 图片缩放后的最短边大小,单位为像素。 800 图片缩放后的最长边大小 是 图片缩放后的最长边大小,单位为像素。 1200 优化方法 是 模型训练的优化方法,支持以下取值: - momentum:指sgd
- adam
adam 初始学习率 是 初始的学习率。 0.0001 学习率调整策略 否 系统支持以下调整策略: - exponential_decay:指数衰减,详细请参见exponential_decay。
- polynomial_decay:多项式衰减,详情请参见polynomial_decay。其中num_steps自动设置为总的训练迭代次数,end_learning_rate为initial_learning_rate的千分之一。
- manual_step:人工指定各阶段的学习率,建议进阶用户使用。通过decay_epochs指定需要调整学习率的迭代轮数,通过learning_rates指定对应迭代轮数使用的学习率。
exponential_decay decay_epoches 否 当学习率调整策略使用exponential_decay或manual_step时,需要配置该参数。
如果学习率调整策略使用exponential_decay,则该参数对应
tf.train.exponential_decay中的decay_steps,详情请参见exponential_decay。系统会自动根据训练数据总数把decay_epochs转换为decay_steps,通常配置为总Epoch数的1/2。例如配置为10。如果学习率调整策略使用manual_step,则该参数表示需要调整学习率的迭代轮数。例如16 18表示在16 Epoch和18 Epoch对学习率进行调整。通常这两个值取总Epoch的8/10和9/10。
40 decay_factor 否 用exponential_decay时,需要配置该参数,表示学习率迭代过程的衰减比率。此时该参数同 tf.train.exponential_decay中的decay_factor,详情请参见exponential_decay。0.5 staircase 否 仅学习率调整策略使用exponential_decay时,需要配置该参数。如果选中该复选框,则按照离散间隔进行学习率衰减,否则按照连续间隔进行学习率衰减。该参数同 tf.train.exponential_decay中的staircase,详情请参见exponential_decay。是 训练batch_size 是 训练的批大小,即单次模型迭代或训练过程中使用的样本数量。 1 评估batch_size 是 评估的批大小,即单次模型迭代或训练过程中使用的样本数量。 1 总的训练迭代epoch轮数 是 总的训练迭代轮数。 20 评估数据条目数 否 用于评估的数据条数,需要您根据评估集大小确定,故无默认值。 无 评估过程可视化显示的样本数目 否 评估过程可视化显示的样本数量。 5 保存checkpoint的频率 否 保存模型文件的频率。取值1表示对所有训练数据都进行一次迭代。 1 执行调优 读取训练数据线程数 否 读取训练数据的线程数。 4 单机或分布式 否 组件的运行模式,支持以下取值 - 单机
表示运行引擎为单机MaxCompute。此时,您还需要配置是否使用GPU,取值100表示1张GPU卡。如果不使用GPU,则需要将是否使用GPU配置为0。
- 分布式表示运行引擎为分布式MaxCompute。此时您还需要配置以下参数:
- worker个数:并发的worker数量。
- CPU Core个数:每个Worker的CPU数目,取值100表示1核。
- memory大小:每个Worker的内存大小,单位为MB。
单机 - 输出桩
输出桩(从左到右) 数据类型 下游组件 输出模型 OSS路径。该路径是您在字段设置页签的训练所用oss目录参数配置的OSS路径,训练生成的模型存储在该路径下。 通用图像预测
计算引擎
端到端的文字识别训练算法组件仅支持MaxCompute引擎。
示例
您可以使用端到端的文字识别训练算法组件构建如下工作流。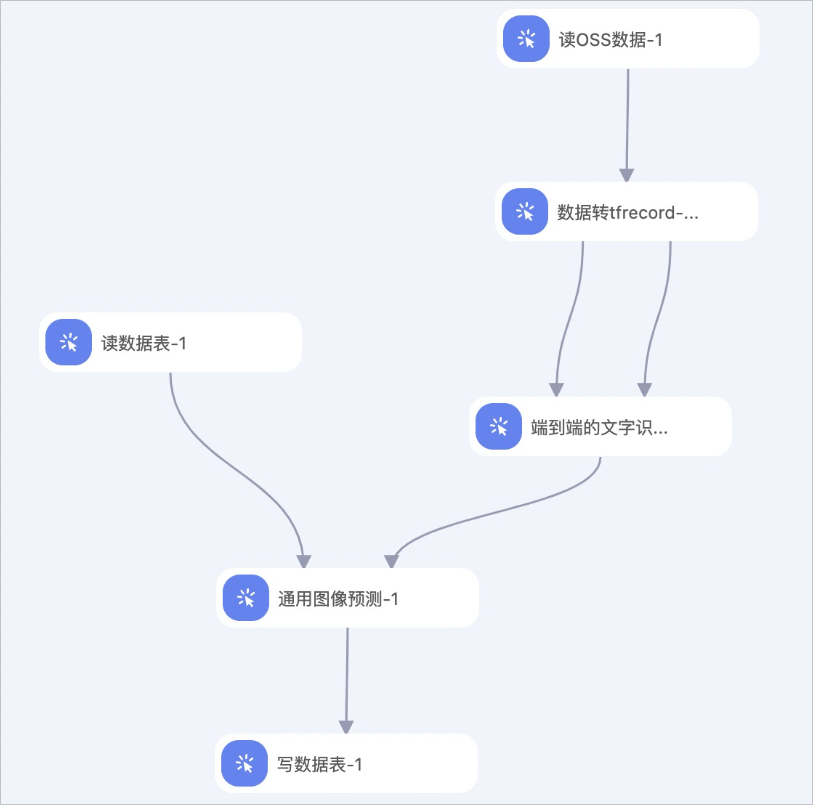
 本示例中,您需要按照以下流程配置组件:
本示例中,您需要按照以下流程配置组件:
- 通过PAI提供的智能标注模块进行图片标注,详情请参见处理标注任务。
- 使用读OSS数据组件读取标注结果文件xxx.manifest,即配置读OSS数据组件的OSS数据路径参数为标注结果数据集的OSS路径。例如
oss://pai-online-shanghai.oss-cn-shanghai.aliyuncs.com/ev_demo/xxx.manifest。 - 通过数据转tfrecord组件将数据集拆分为tfrecord格式的训练数据和评估数据,详情请参见数据转tfrecord。
- 将训练数据和评估数据接入端到端的文字识别训练算法组件,并配置具体参数,详情请参见上文的可视化配置组件。
- 通过MaxCompute客户端的Tunnel命令将预测的输入数据集上传至MaxCompute,再将读数据表组件的表名参数配置为该MaxCompute表。关于MaxCompute客户端的安装及配置请参见使用客户端(odpscmd)连接,关于Tunnel命令详情请参见Tunnel命令。
- 通过通用图像预测组件进行离线推理,详情请参见通用图像预测。
- 将预测的结果写入数据表中,详情请参见写数据表。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/163447.html