
本文以MaxCompute离线同步写入ClickHouse场景为例,为您介绍ClickHouse离线同步在数据源配置、网络联通、同步任务配置方面的最佳实践。
背景信息
云数据库ClickHouse是面向联机分析处理的列式数据库。数据集成支持从ClickHouse同步数据到其他目标端,也支持从其他目标端同步数据到ClickHouse。本文以MaxCompute离线同步写入ClickHouse为例,为您介绍ClickHouse离线同步的完整流程。
使用限制
- ClickHouse离线同步仅支持阿里云ClickHouse。
- ClickHouse离线同步仅支持使用独享数据集成资源组。
获取ClickHouse集群信息
进入ClickHouse产品控制台。找到您要进行数据同步的ClickHouse集群,在集群信息页面获取ClickHouse集群的外网地址、内网地址、HTTP端口号、VPC ID、Vswitch ID、可用区。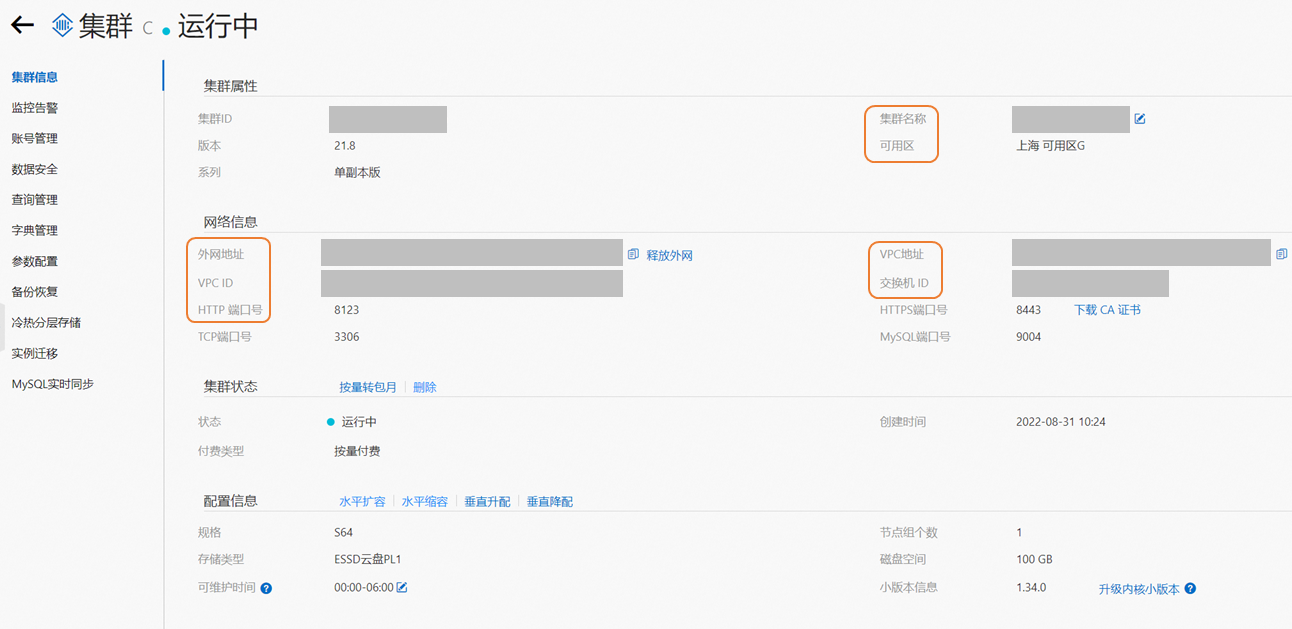

准备独享数据集成资源组并与ClickHouse网络连通
在进行数据同步前,需要完成您的独享数据集成资源组和ClickHouse集群的配置网络连通。
- 如果您的独享数据集成资源组和ClickHouse属于同一地域,可使用同地域VPC内网联通独享资源组和ClickHouse。实现网络联通需要执行:
- 在DataWorks侧新增专有网络绑定和自定义路由。
- 在ClickHouse侧添加数据库白名单。
- 如果您的独享数据集成资源组和ClickHouse属于不同地域,可使用公网联通独享资源组和ClickHouse。实现网络联通需要执行:在ClickHouse侧添加数据库白名单。
步骤1 新增专有网络绑定和自定义路由
说明 如果您使用公网联通独享资源组和ClickHouse,可跳过此步骤。
- 新增专有网络绑定。进入DataWorks管控台资源组列表页面,找到您要联通的独享数据集成资源组,单击资源组右侧的网络设置,进入资源组网络设置页面,根据界面提示新增绑定专有网络。关键配置信息如下。
- 专有网络:请选择ClickHouse所在的专有网络。
- 可用区、交换机:优先选择ClickHouse所在的可用区和交换机;如果ClickHouse所在的可用区不可选择,则选择其他任意可用区和交换机。
- 安全组:可以选择您名下任意自建安全组,但所选择的安全组需满足以下条件:
- 在安全组产品控制台查看安全组,访问规则的入方向允许放行ClickHouse集群HTTP端口(通常为8123)。
- 安全组的授权对象网段包含上一步所选择的交换机网段。
- 添加自定义路由。说明 如果您在上述步骤中选择了ClickHouse所在的可用区和交换机,可跳过此步骤。如果您选择了其他可用区和交换机,则需要参考以下指导进行自定义路由的操作。
- 进入DataWorks管控台资源组列表页面,找到您要联通的独享数据集成资源组,单击资源组右侧的网络设置,进入资源组网络设置页面。
- 在专有网络绑定页签下,找到刚才绑定的专有网络记录,单击右侧的自定义路由,根据界面提示新增路由。关键配置信息如下。
- 目的VPC:选择ClickHouse所在的地域和专有网络。
- 目的Switch实例:选择ClickHouse所在的交换机。
步骤2 添加数据库白名单
- 进入ClickHouse产品控制台。找到您要进行数据同步的ClickHouse集群,在数据安全页面,单击添加分组白名单按钮。
- 填写白名单网段,单击确认按钮。
- 如果您使用VPC内网联通独享资源组和ClickHouse,则白名单内填写的网段为独享资源组上专有网络绑定时选择的交换机所在网段。您可以在独享资源组列表页面单击网络设置按钮,在专有网络绑定页面找到交换机所在网段。

- 如果您使用公网联通独享资源组和ClickHouse,则白名单为独享资源组的EIP地址。您可以在独享资源组列表页面单击查看信息按钮,获得EIP地址。

- 如果您使用VPC内网联通独享资源组和ClickHouse,则白名单内填写的网段为独享资源组上专有网络绑定时选择的交换机所在网段。您可以在独享资源组列表页面单击网络设置按钮,在专有网络绑定页面找到交换机所在网段。
添加数据源
新建MaxCompute数据源
可通过绑定MaxCompute引擎自动添加MaxCompute数据源,或者手动添加MaxCompute数据源,操作详情请参见绑定MaxCompute引擎或配置MaxCompute数据源。
新建ClickHouse数据源
在DataWorks数据源管理页面,单击新建数据源,根据界面提示新建ClickHouse数据源。配置要点如下。
- JDBC URL:格式为
jdbc:clickhouse://:/,其中::需替换为您ClickHouse集群的内网地址或外网地址。- 如果您选择使用VPC内网联通独享资源组和ClickHouse,则此处填写ClickHouse内网地址。
- 如果您选择使用公网联通独享资源组和ClickHouse,则此处填写ClickHouse外网地址。
:需替换为您ClickHouse集群的HTTP端口号(通常为8123)。:需替换为您要同步的ClickHouse库名。
- 用户名、密码:为对应ClickHouse库有访问权限的用户名和密码。
- 测试连通性:选择您已经完成与ClickHouse网络联通的独享数据集成资源组,确保连通状态为可连通。说明 完成上述步骤中的网络连通后,仅可实现ClickHouse与对应独享数据集成资源组的网络联通。如您期望完成ClickHouse与数据服务资源组、调度资源组的网络联通,需分别进行网络连通的配置与连通测试。
新建离线同步任务
在数据开发(DataStudio)页面的某个业务流程下,新建一个离线同步节点,根据界面提示配置节点的路径、名称等信息,操作详情请参见通过向导模式配置离线同步任务。
配置数据来源:MaxCompute侧参数
配置离线同步节点的数据来源相关参数。本实践将MaxCompute数据增量同步至ClickHouse,数据来源为MaxCompute表,配置要点如下所示。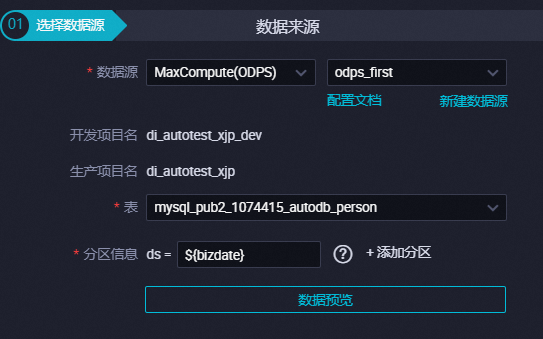
| 配置项 | 配置要点 |
|---|---|
| 数据源 | 选择上述新建的MaxCompute数据源或DataWorks工作空间绑定MaxCompute引擎后自动生成的数据源。如果您使用的是标准类型的DataWorks工作空间,会分别显示开发和生产项目的名称。 |
| 表 | 选择待同步的MaxCompute表。如果您使用的是标准类型的DataWorks工作空间,请确保在MaxCompute的开发环境和生产环境中存在同名且表结构一致的MaxCompute表。说明 如果:
|
| 分区信息 | 您可以填入分区列的取值。
|
其他参数保持默认即可。
配置数据去向:ClickHouse侧参数
本实践将数据同步至ClickHouse,数据去向是ClickHouse。配置要点如下。
| 配置项 | 配置要点 |
|---|---|
| 数据源 | 选择上述新建的ClickHouse数据源。 |
| 表 | 选择待同步的Clickhouse表。建议对于要进行数据同步的表,ClickHouse数据源开发和生产环境保证具有相同的表结构。说明 此处会展示ClickHouse数据源开发环境地的表列表和表结构,如果您的ClickHouse数据源开发和生产环境的表定义不同,则可能出现任务在开发环境配置正常但提交生产运行后报错表不存在、列不存在的问题。 |
| 导入前准备语句、导入后完成语句 | 您可以在执行数据同步任务的前后按需执行SQL语句。比如在按天进行数据同步前清理对应天分区的数据,保证本次数据写入前对应分区是无数据的。 |
| 批量插入字节大小、批量插入条数 | 数据同步写入ClickHouse时采用攒批写入方式,此处是攒批的字节数上限、条数上限。如果读取到的数据达到攒批的字节数上限或条数上限,则认为攒够一批,每攒够一批则写入一批数据到ClickHouse。
批量插入字节大小建议值为16777216(16MB),批量插入条数建议按照您单条记录的大小调整为一个较大值,从而依靠批量插入字节大小触发批次写入。 例如单条记录大小为1KB,批量插入字节大小设置为16777216(16MB),批量插入条数设置为20000(大于16MB/1KB=16384),则会通过批量插入字节大小触发写入,每达到16MB写入一次。 |
| 批量写入ClickHouse异常时 | 批量写入ClickHouse异常时,可以选择异常处理策略:
|
配置字段映射
选择数据来源和数据去向后,需要指定读取端和写入端列的映射关系。您可以选择同名映射、同行映射、取消映射或自动排版。
配置通道控制
设置任务同步并发数,可容忍的脏数据条数等。
调整内存参数
如果您在并发调大后同步速率增长不明显,可以尝试手工调整同步任务内存参数。调整方式如下。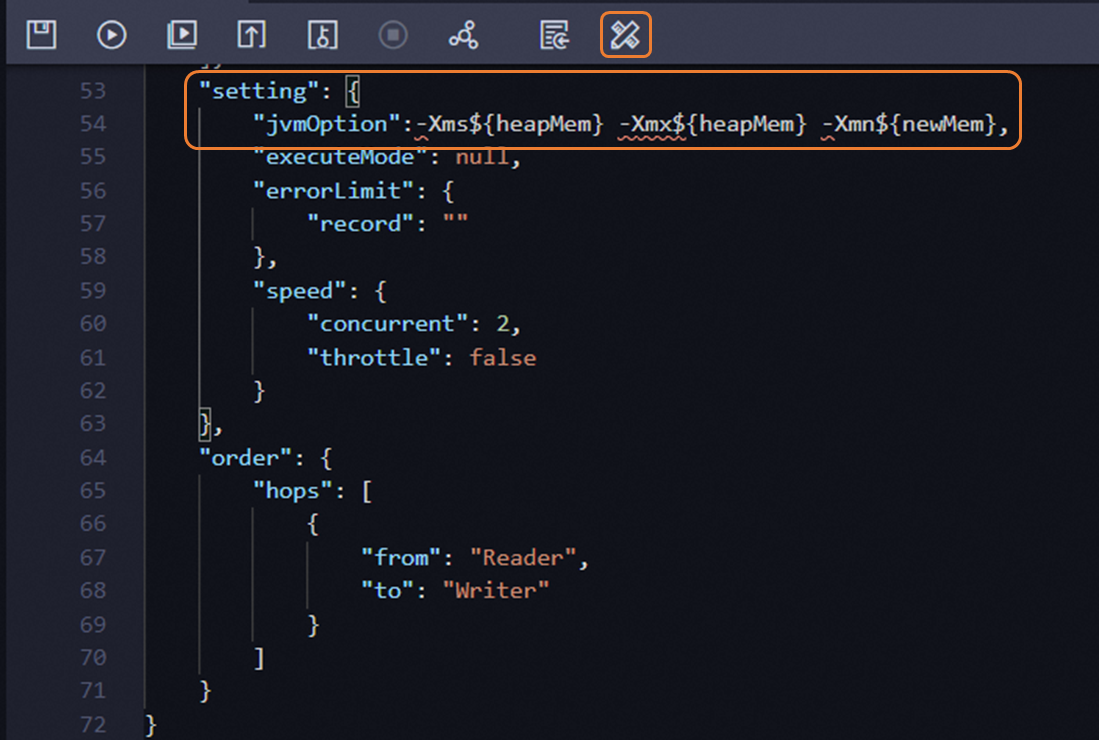
- 转换任务为脚本模式。
- 在脚本JSON段中增加
setting.jvmOption参数,参数形如-Xms${heapMem} -Xmx${heapMem} -Xmn${newMem}。
向导模式下系统计算的${heapMem}的取值为768MB+(并发数-1)*256 MB。建议您在脚本模式中将${heapMem}设置为更大值,并将${newMem}设置为${heapMem}的三分之一。如并发数为8时,向导模式默认计算的${heapMem}为2560MB,脚本模式中可设置更大值,如设置jvmOption为-Xms3072m -Xmx3072m -Xmn1024m。
调度配置
单击右侧的调度配置,本实践示例涉及的调度配置要点如下。通用的调度配置指导及全量调度相关参数的介绍请参见调度配置。
- 重跑属性。
可根据业务需求设置不同的重跑策略,设置失败可重跑策略可以有效降低因为网络抖动等偶发问题导致的任务失败。
- 配置调度依赖。
可根据业务需求设置不同的调度依赖。您可以通过设置依赖上一周期的本节点,保证本节点多个调度周期的任务实例是依次执行完成的,避免多任务实例同时调度运行。
数据集成资源组配置
选择在创建数据源时,与ClickHouse数据源、MaxCompute数据源都完成连通性检查的数据集成资源组。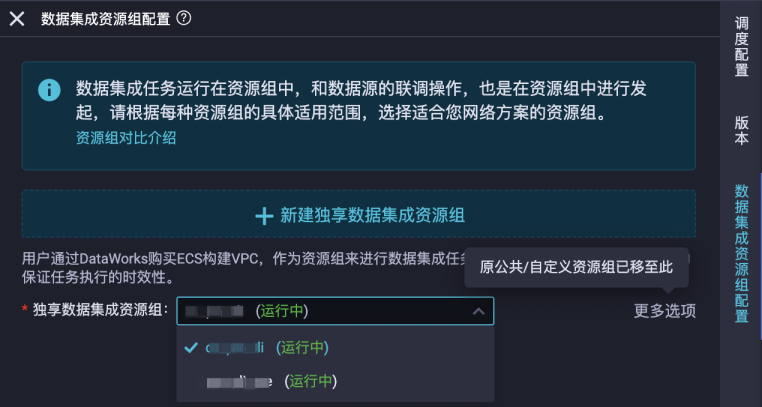
试运行与提交执行任务
试运行
单击顶部的 运行或带参运行,可以试运行并查看同步结果是否符合预期。
运行或带参运行,可以试运行并查看同步结果是否符合预期。
- 带参运行可以针对任务配置中使用的调度系统参数进行替换。
- 如果是标准项目,此时会在开发环境运行同步任务,源端使用MaxCompute的开发项目开发表,目标端使用ClickHouse的开发环境JDBC URL和库表。
提交和发布任务
试运行没有问题后,您可以保存离线节点的配置,并提交发布至运维中心,后续离线同步任务将会周期性(分钟或小时或天)将Kafka的数据写入MaxCompute的表中。提交发布的操作请参见发布任务。
发布成功后,您可以在运维中心查看周期调度运行结果、进行补数据等操作。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/172068.html