
若您要使用DataWorks进行MaxCompute任务的开发、管理,需先将您的MaxCompute项目创建为DataWorks的MaxCompute数据源。创建完成后,可在DataWorks的各功能模块使用该数据源连接MaxCompute项目,进行相应的数据同步、数据开发、数据分析等操作。
前提条件
-
已购买MaxCompute项目,详情请参见开通MaxCompute。
说明
建议购买MaxCompute项目的地域与创建MaxCompute数据源的DataWorks工作空间地域一致。若地域不一致,则只能创建为跨地域的数据源,此类数据源无法在DataWorks的数据开发(DataStudio)模块绑定,即无法用于数据开发或周期性调度任务,仅可进行数据同步任务。
-
已购买所需DataWorks资源组并完成资源组配置。
MaxCompute数据源创建完成后,可用于进行数据同步、计算任务开发与调度、生成API提供数据服务等应用场景,各场景需分别使用DataWorks的数据集成资源组、调度资源组、数据服务资源组。
您需根据应用场景提前准备对应的资源组并完成配置,在创建MaxCompute数据源时确保与对应资源组间网络连通。各资源组的介绍与配置引导,请参见DataWorks资源组概述。
使用限制
-
仅当MaxCompute项目和DataWorks工作空间同地域、同账号时,基于该MaxCompute项目创建的MaxCompute数据源才可被绑定为计算引擎。
-
跨账号创建数据源仅支持通过RAM角色访问的方式执行,并且该类数据源不能用于数据开发和调度。详情请参见场景:跨账号创建MaxCompute数据源。
-
数据集成 > 数据源界面仅支持创建生产数据源,创建完成后需在管理中心 > 数据源界面进行管理。
说明
数据集成 > 数据源界面,支持创建的数据源类型是管理中心 > 数据源的子集,具体请以实际界面为准。
-
仅运维和空间管理员角色可创建数据源。授权用户拥有该类角色,详情请参见添加空间成员并管理成员角色权限。
说明
除上述空间角色权限外,创建MaxCompute数据源时还会存在其他MaxCompute侧权限控制,您需根据界面提示进行授权。详情请参见下文权限说明章节。
权限说明
-
使用RAM用户或角色创建数据源:
-
通过新建MaxCompute项目创建数据源,需拥有MaxCompute的odps:CreateProject权限。数据源创建完成后,该RAM用户或角色将被MaxCompute项目添加为Super_Administrator。
说明
标准模式工作空间区分开发及生产环境,对应的MaxCompute开发及生产项目需分别添加RAM用户或角色为Super_Administrator。
-
通过已有MaxCompute项目创建数据源,需拥有MaxCompute的odps:ListProjects权限,以及目标MaxCompute项目的Super_Administrator权限。
-
-
设置生产数据源的默认访问身份为RAM用户或角色:
如需将默认访问身份设置为其他阿里云账号或角色(即非当前登录账号的其他身份),需拥有RAM的AdministratorAccess权限,且数据源创建完成后,该账号或角色将会被MaxCompute生产项目添加为Role_Project_Scheduler角色。配置默认访问身份,详情请参见下文的创建数据源章节。
数据源创建入口
-
进入数据源页面。
-
登录DataWorks控制台,单击左侧导航栏的管理中心,在下拉框中选择对应工作空间后单击进入管理中心。
-
进入工作空间管理中心页面后,单击左侧导航栏的数据源,进入数据源页面。
-
-
单击新增数据源,选择MaxCompute,根据界面指引创建数据源。
您也可进入数据集成界面创建,但该页面仅支持创建生产数据源,且创建完成后需在管理中心 > 数据源进行管理。数据集成页面支持创建的数据源类型,具体请以实际界面为准。
创建数据源
DataWorks支持通过如下两种方式创建新版数据源。
说明
标准模式工作空间,需分别创建开发环境数据源和生产环境数据源。工作空间模式,详情请参见必读:简单模式和标准模式的区别。
方式一:通过已有MaxCompute项目创建数据源
若您已有MaxCompute项目,则可将已有MaxCompute项目添加为当前工作空间的数据源。
通过该方式新建数据源,需拥有MaxCompute的odps:ListProjects权限,以及目标MaxCompute项目的Super_Administrator权限。
创建数据源配置如下。
-
配置基础信息。


参数
说明
数据源名称
定义数据源在DataWorks的名称,名称必须唯一。
认证方式
新建的数据源仅支持通过阿里云账号及阿里云RAM角色身份进行认证。
说明
历史存量使用AccessID及AccessKey创建的数据源,建议后续修改时通过阿里云账号及阿里云RAM角色身份进行认证。
所属云账号
定义添加哪个账号下的MaxCompute项目作为当前工作空间的数据源。
-
当前阿里云主账号:添加当前阿里云主账号下的MaxCompute项目作为当前工作空间的数据源。
-
其他阿里云主账号:添加其他阿里云主账号下的MaxCompute项目作为当前工作空间的数据源。
请根据选择的账号类型,参照下文配置其他配置项。
地域
MaxCompute项目所在地域。
说明
若选择的MaxCompute项目与当前工作空间不在同一地域,则将MaxCompute项目添加为数据源后,该数据源不支持绑定为工作空间的计算引擎,即不支持在数据开发(DataStudio)、运维中心使用,仅用于数据集成模块进行数据同步。
其他配置(使用当前阿里云主账号)
当所属云账号选择当前阿里云主账号时,您需配置如下参数:
-
MaxCompute项目名称:选择需将指定地域下哪一个MaxCompute项目添加为当前工作空间的数据源。
说明
若无法选择目标MaxCompute项目,则请授予当前登录账号该项目的Super_Administrator权限。授权详情请参见权限说明。
-
默认访问身份:定义在当前工作空间下,用什么身份访问该数据源。
-
开发环境:当前仅支持使用执行者身份访问。
-
生产环境:支持使用阿里云主账号、阿里云RAM用户(即子账号)、阿里云RAM角色访问。
说明
-
仅阿里云主账号及拥有AdministratorAccess角色权限的用户或角色可选择所有身份访问。
-
设置生产数据源的默认访问身份为RAM用户或角色:
如需将默认访问身份设置为其他阿里云账号或角色(即非当前登录账号的其他身份),需拥有RAM的AdministratorAccess权限,且数据源创建完成后,该账号或角色将会被MaxCompute生产项目添加为Role_Project_Scheduler角色。配置默认访问身份,详情请参见下文的创建数据源章节。
-
-
其他配置(使用其他阿里云主账号)
当所属云账号选择其他阿里云主账号时,您需配置如下参数:
-
对方阿里云主账号UID:需添加的MaxCompute项目所属的云账号UID。
-
对方MaxCompute项目:需将对方账号下哪一个MaxCompute项目作为当前工作空间的MaxCompute数据源。
-
对方RAM角色:访问该MaxCompute项目的RAM角色。该角色需满足如下条件:
-
对方阿里云主账号中已创建RAM角色。
-
对方阿里云主账号的RAM角色已授权当前账号DataWorks服务访问。
-
所选择的MaxCompute项目中已添加该角色。
-
说明
-
跨账号添加数据源的相关操作,详情请参见场景:跨账号创建MaxCompute数据源。
-
若选择的MaxCompute项目与DataWorks工作空间不在同一个阿里云主账号下,则将MaxCompute项目添加为数据源后,该数据源不支持绑定为工作空间的计算引擎,即不支持在数据开发(DataStudio)、运维中心使用,仅用于数据集成模块进行数据同步。
Endpoint
指定DataWorks通过该数据源访问MaxCompute项目的Endpoint地址。包括访问MaxCompute服务的Endpoint地址,以及上传、下载本地或云数据源数据的Tunnel服务地址。支持以下两种配置:
-
自动适配:DataWorks根据实际情况自动适配,建议选择该项。
说明
若MaxCompute项目与DataWorks服务所在地域不一致,即存在跨地域访问场景,自动适配情况下,数据集成默认使用公网访问地址读取和下载数据。
-
自定义配置:自定义情况下,您需手动配置MaxCompute Endpoint及Tunnel Endpoint,不同地域,Endpoint不同。详情请参见Endpoint。
说明
原绑定MaxCompute引擎自动创建的MaxCompute数据源暂不支持修改Tunnel Endpoint。
-
-
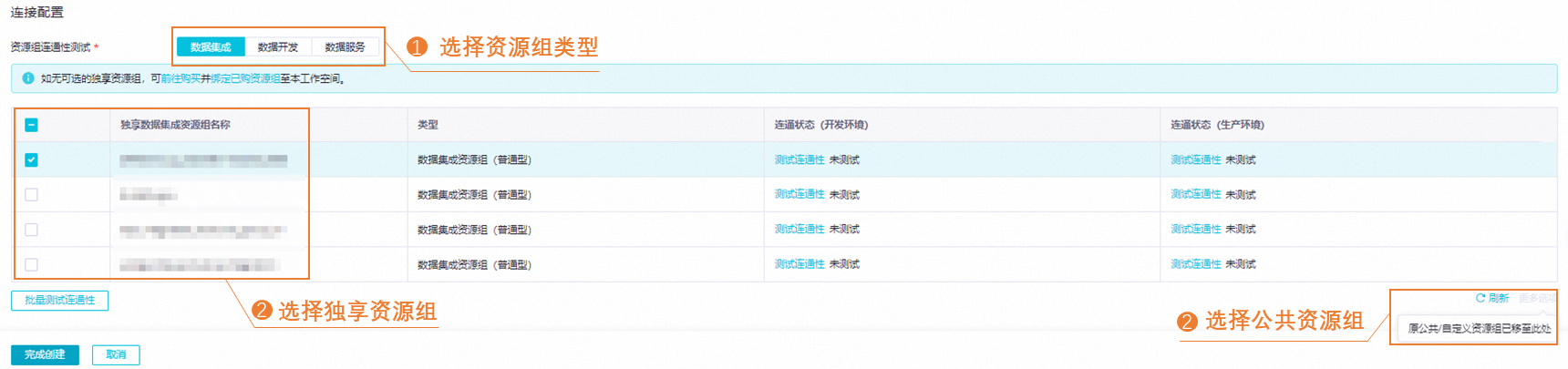
测试资源组连通性。
DataWorks提供租户共享的公共资源组和用户独享的独享资源组。公共资源组在任务运行高峰期可能出现等待资源的情况,独享资源组提供专有的计算资源来保障任务定时被调度运行。另外,根据使用场景不同,资源组分为数据集成、开发调度、数据服务三种类型。各类资源组的介绍,详情请参见DataWorks资源组概述。
您需根据数据源后续的用途,在对应资源组类型页签下,测试所需资源组的连通性。若资源组与数据源无法连通,则相应数据源任务将无法正常执行。
说明
数据源创建成功后平台会进行访问身份授权,即将访问身份账号添加至MaxCompute项目中,并为该身份映射MaxCompute对应的权限。在授权完成前,连通性测试可能会产生连通无权限报错,该场景下,保存数据源后,您需稍作等待。
方式二:通过新建MaxCompute项目创建数据源
若您没有可用MaxCompute项目,则可新建MaxCompute项目并将其添加为当前工作空间的数据源。
通过该方式新建数据源,需拥有MaxCompute的odps:CreateProject权限。若使用RAM用户或角色创建数据源,数据源创建完成后,该RAM用户或角色将被MaxCompute项目添加为Super_Administrator。
说明
通过该方式创建的数据源,会默认将工作空间内存量和新增用户均加入至MaxCompute开发项目。同时,用户所拥有的角色会映射相应预设MaxCompute角色。详情请参见附录:空间级预设角色与MaxCompute引擎权限的映射关系。
创建数据源配置如下。
-
配置基础信息。
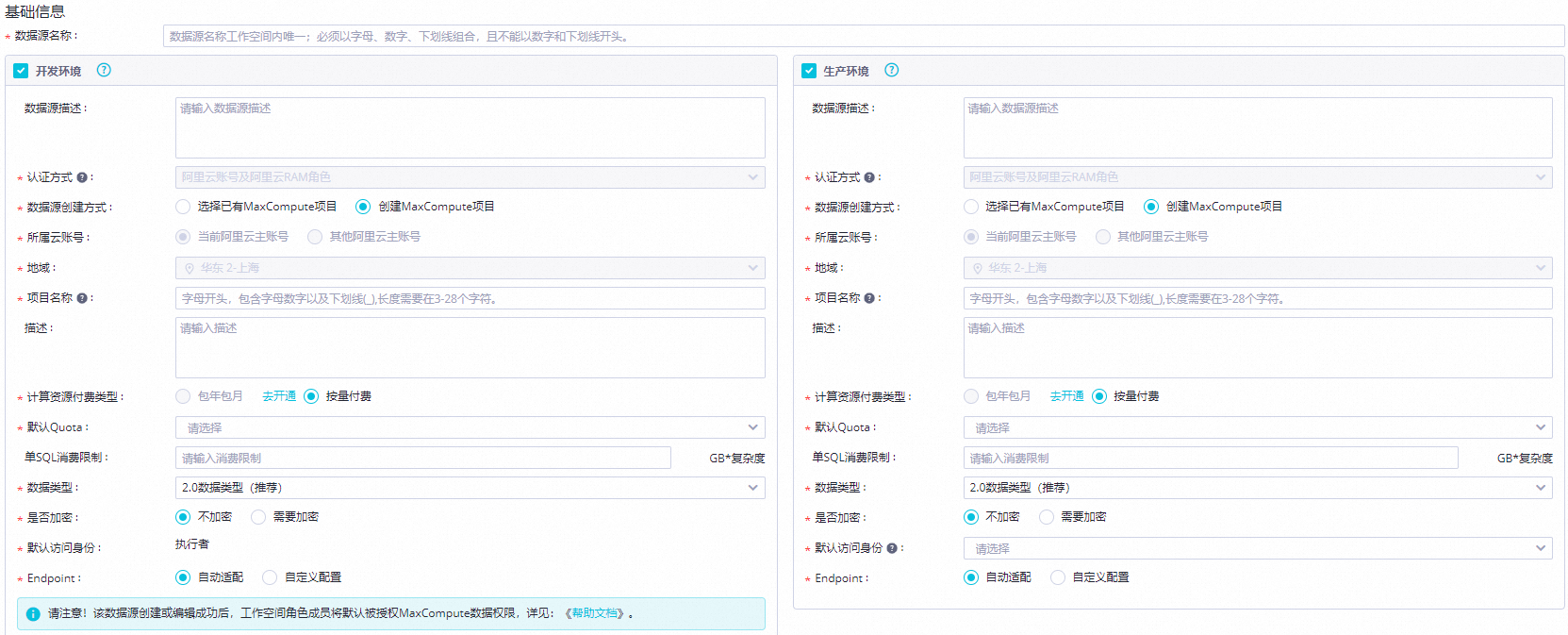
参数
说明
数据源名称
定义数据源在DataWorks的名称,名称必须唯一。
认证方式
新建的数据源仅支持通过阿里云账号及阿里云RAM角色身份进行认证。
所属云账号
仅支持通过当前阿里云主账号创建数据源。
地域
仅支持在当前工作空间所在地域创建数据源。
项目名称
创建的MaxCompute项目命称。建议按如下规范命名:
-
生产环境:project_name
-
开发环境:project_name_dev
计算资源付费类型
定义MaxCompute项目按照哪种付费方式进行计费,包括按量付费和包年包月。 关于MaxCompute计费模式详情请参见计费项与计费方式概述。
说明
标准模式下不支持添加开发者版本的实例。
默认Quota
定义MaxCompute项目使用的计算资源池。关于Quota相关说明详情请参见配额。
单SQL消费限制
用于设置单个SQL语句的消费阈值,预防单个SQL语句产生高额费用。
数据类型
定义MaxCompute项目使用哪一类数据类型。包括2.0数据类型(推荐)、1.0数据类型(面向已有使用1.0数据类型用户)和Hive兼容类型(面向Hive迁移用户),详情请参见:数据类型版本说明。
是否加密
根据实际情况选择当前MaxCompute项目是否需要通过密钥管理服务KMS(Key Management Service)对数据进行存储加密,详情请参见存储加密。
默认访问身份
定义在当前工作空间下,用什么身份访问该数据源。
-
开发环境:当前仅支持使用执行者身份访问。
-
生产环境:支持使用阿里云主账号、阿里云RAM用户(即子账号)、阿里云RAM角色访问。
说明
-
仅阿里云主账号及拥有AdministratorAccess角色权限的用户或角色可选择所有身份访问。
-
设置生产数据源的默认访问身份为RAM用户或角色:
如需将默认访问身份设置为其他阿里云账号或角色(即非当前登录账号的其他身份),需拥有RAM的AdministratorAccess权限,且数据源创建完成后,该账号或角色将会被MaxCompute生产项目添加为Role_Project_Scheduler角色。配置默认访问身份,详情请参见下文的创建数据源章节。
-
Endpoint
指定DataWorks通过该数据源访问MaxCompute项目的Endpoint地址。包括访问MaxCompute服务的Endpoint地址,以及上传、下载本地或云数据源数据的Tunnel服务地址。支持以下两种配置:
-
自动适配:DataWorks根据实际情况自动适配,建议选择该项。
说明
若MaxCompute项目与DataWorks服务所在地域不一致,即存在跨地域访问场景,自动适配情况下,数据集成默认使用公网访问地址读取和下载数据。
-
自定义配置:自定义情况下,您需手动配置MaxCompute Endpoint及Tunnel Endpoint,不同地域,Endpoint不同。详情请参见Endpoint。
说明
原绑定MaxCompute引擎自动创建的MaxCompute数据源暂不支持修改Tunnel Endpoint。
-
-
测试资源组连通性。
DataWorks提供租户共享的公共资源组和用户独享的独享资源组。公共资源组在任务运行高峰期可能出现等待资源的情况,独享资源组提供专有的计算资源来保障任务定时被调度运行。另外,根据使用场景不同,资源组分为数据集成、开发调度、数据服务三种类型。各类资源组的介绍,详情请参见DataWorks资源组概述。
您需根据数据源后续的用途,在对应资源组类型页签下,测试所需资源组的连通性。若资源组与数据源无法连通,则相应数据源任务将无法正常执行。
数据源创建完成后,您可根据需要执行如下后续操作:
-
管理数据源:进入数据源管理页面执行编辑、删除等管理操作。
-
绑定计算引擎:您可将创建的数据源绑定为工作空间的计算引擎,进行数据开发。
-
数据集成概述:根据需要选择合适同步场景,执行相关数据同步操作。
后续操作:绑定计算引擎
引擎绑定操作
数据源创建完成后,您需进入管理中心,按如下步骤将创建的数据源绑定为工作空间的引擎,执行后续开发操作。
说明
-
仅当MaxCompute项目和DataWorks工作空间同地域、同账号时,基于该MaxCompute项目创建的MaxCompute数据源才可被绑定为计算引擎。
-
跨账号创建的数据源,不支持绑定为计算引擎。
-
同一个MaxCompute项目可被绑定为多个DataWorks工作空间的计算引擎。
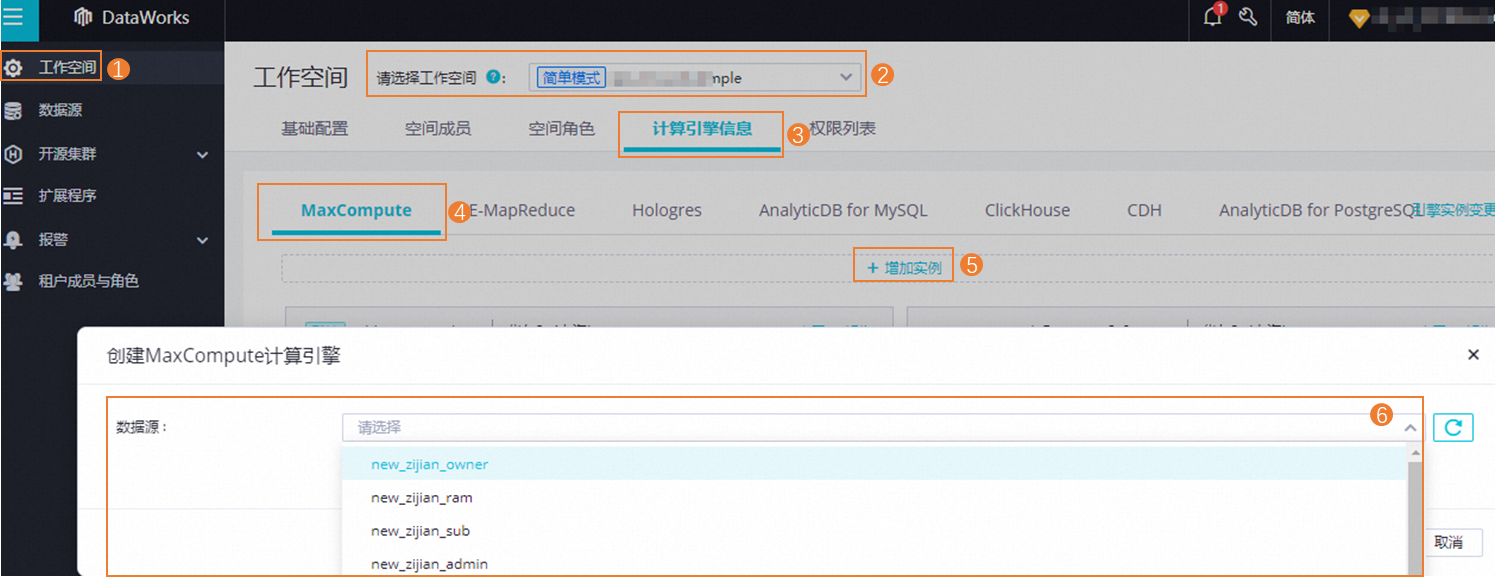
-
编辑计算引擎:不再支持直接编辑计算引擎,如需编辑可直接通过编辑引用的数据源来实现。
-
解绑计算引擎:空间管理员可直接解绑计算引擎,不会导致引用的数据源被删除。
引擎绑定对生产数据的影响
当数据源被作为计算引擎时,对生产数据的影响如下。
说明
简单模式工作空间无法做到细粒度权限控制,以下内容为标准模式工作空间下的说明。
|
影响 |
说明 |
相关文档 |
|
对生产数据资源归属影响 |
当前工作空间下的生产数据均归属于您在绑定引擎(即创建数据源)时,所指定的生产环境默认访问身份。默认为阿里云主账号,且默认RAM用户无法直接操作生产数据。 |
|
|
对生产数据访问控制影响 |
除RAM用户被指定为生产环境的默认访问身份这一场景外,其他场景下,RAM用户被添加为工作空间成员后,默认无生产环境操作权限,操作及访问生产表需在安全中心申请权限。 |
绑定MaxCompute引擎后,便可基于该引擎进行数据开发。详情请参见数据开发概述。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/171696.html