
本文为您介绍如何配置相同区域下不同的MaxCompute项目,以及如何实现数据迁移。
前提条件
请您首先完成教程《搭建互联网在线运营分析平台》的全部步骤,详情请参见业务场景与开发流程。
背景信息
本文使用的被迁移的原始项目为教程《搭建互联网在线运营分析平台》中的bigdata_DOC项目,您需要再创建一个迁移目标项目,用于存放原始项目的表、资源、配置和数据。
操作步骤
- 创建迁移目标项目
本文的MaxCompute项目即DataWorks的工作空间。- 登录DataWorks控制台,单击左侧导航栏中的工作空间列表。
- 选择区域为华东1(杭州),单击创建工作空间。
- 填写创建工作空间对话框中的基本配置,单击下一步。
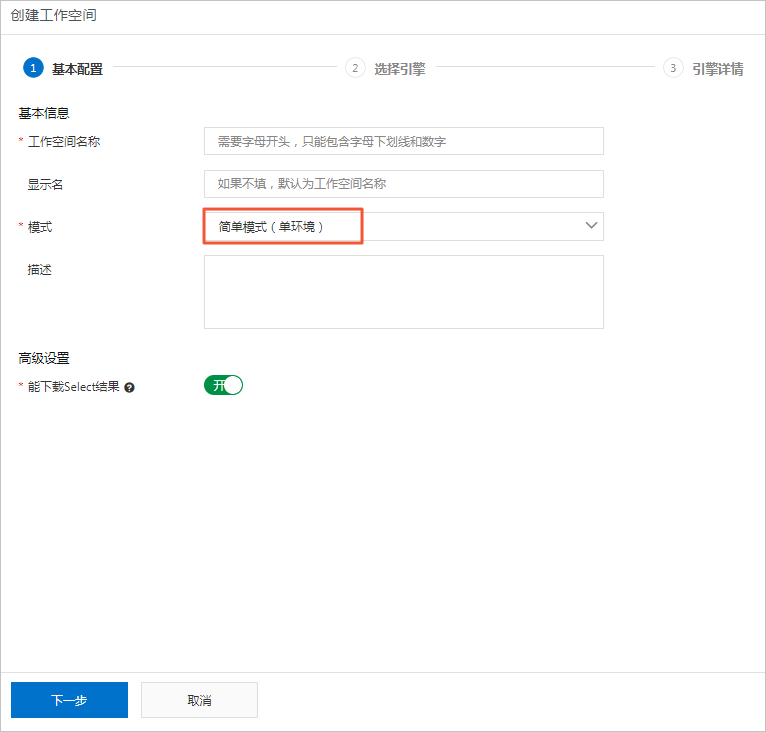

分类 参数 描述 基本信息 工作空间名称 工作空间名称的长度需要在3~28个字符,以字母开头,且只能包含字母、下划线(_)和数字。 显示名 显示名不能超过23个字符,只能字母、中文开头,仅包含中文、字母、下划线(_)和数字。 模式 DataWorks的工作空间分为简单模式和标准模式: - 简单模式:指一个DataWorks工作空间对应一个引擎项目,无法设置开发和生产环境,只能进行简单的数据开发,无法对数据开发流程以及表权限进行强控制。
- 标准模式:指一个DataWorks工作空间对应两个引擎项目,可以设置开发和生产两种环境,提升代码开发规范,并能够对表权限进行严格控制,禁止随意操作生产环境的表,保证生产表的数据安全。
详情请参见必读:简单模式和标准模式的区别。
描述 对创建的工作空间进行简单描述。 高级设置 能下载select结果 控制数据开发中查询的数据结果是否能够下载,如果关闭无法下载select的数据查询结果。此参数在工作空间创建完成后可以在工作空间配置页面进行修改,详情可参考文档:创建并管理工作空间。 由于原始项目bigdata_DOC为简单模式,为方便起见,本文中DataWorks工作空间模式也为简单模式(单环境)。
工作空间名称全局唯一,建议您使用易于区分的名称,本例中使用的名称为clone_test_doc。
- 选择计算引擎服务为MaxCompute、按量付费,单击下一步。
- 配置引擎详情,单击创建工作空间。
分类 参数 描述 MaxCompute 实例显示名称 实例显示名称不能超过27个字符,仅支持字母、中文开头,仅包含中文、字母、下划线和数字。 MaxCompute项目名称 默认与DataWorks工作空间的名称一致。 MaxCompute访问身份 开发环境的MaxCompute访问身份默认为任务负责人,不可以修改。 生产环境的MaxCompute访问身份包括阿里云主账号和阿里云子账号。
Quota组切换 Quota用来实现计算资源和磁盘配额。
- 跨项目克隆
您可以通过跨项目克隆功能将原始项目bigdata_DOC的节点配置和资源复制到当前项目,详情请参见跨项目克隆实践。
说明- 跨项目克隆无法复制表结构与数据。
- 跨项目克隆无法复制组合节点,需要您手动创建。
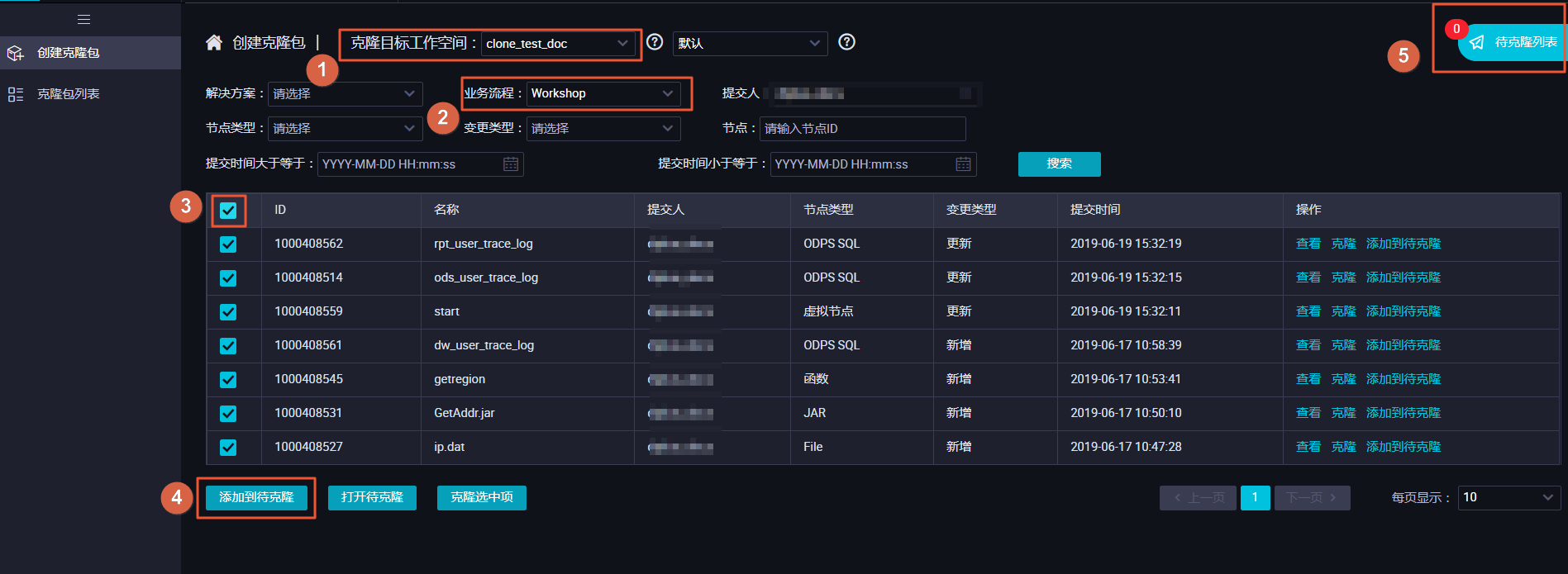
- 单击原始项目bigdata_DOC右上角的跨项目克隆,跳转至相应的克隆页面。

- 选择克隆目标工作空间为clone_test_doc,业务流程为您需要克隆的业务流程Workshop,勾选所有节点,单击添加到待克隆后单击右侧的待克隆列表。
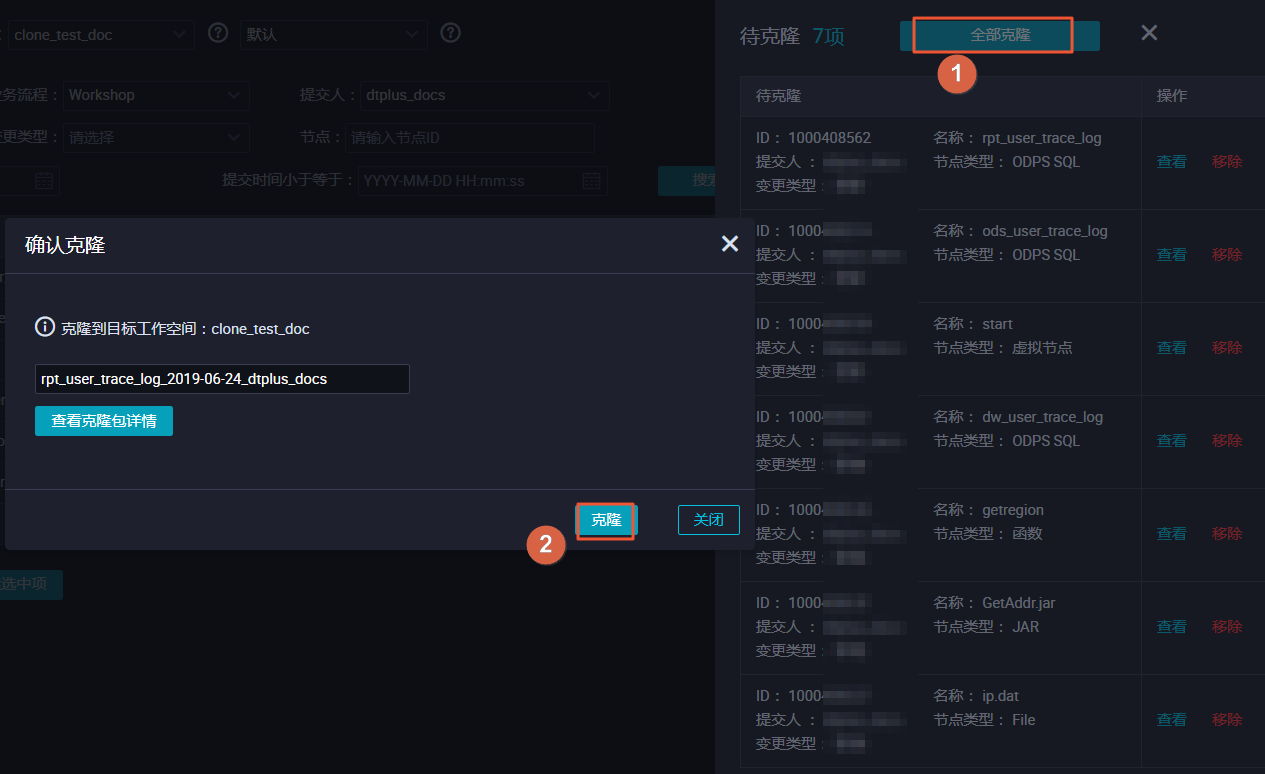
- 单击全部克隆,将选中的节点克隆至工作空间clone_test_DOC。
- 切换至您新建的项目,检查节点是否已完成克隆。
- 新建数据表
跨项目克隆功能无法克隆您的表结构,因此您需要手动新建表。- 对于非分区表,建议使用如下语句迁移表结构。
create table table_name as select * from 源库MaxCompute项目.表名 ; - 对于分区表,建议使用如下语句迁移表结构。
create table table_name partitioned by (分区列 string);
新建表后请将表提交到生产环境。更多建表信息,请参见新建数据表。
- 对于非分区表,建议使用如下语句迁移表结构。
- 数据同步
跨项目克隆功能无法复制原始项目的数据到新项目,因此您需要手动同步数据,本文中仅同步表rpt_user_trace_log的数据。- 新建数据源。
- 在数据集成页面,单击左侧导航栏上的数据源。
- 在数据源管理页面,单击右上角新增数据源,并选择MaxCompute(ODPS)。
- 填写您的数据源名称、ODPS项目名称、AccessKey ID、AccessKey Secret等信息,单击完成,详情请参见配置MaxCompute数据源。
- 创建数据同步任务。
- 在数据开发页面右键单击您克隆的业务流程Workshop下的数据集成,选择新建 > 离线同步。
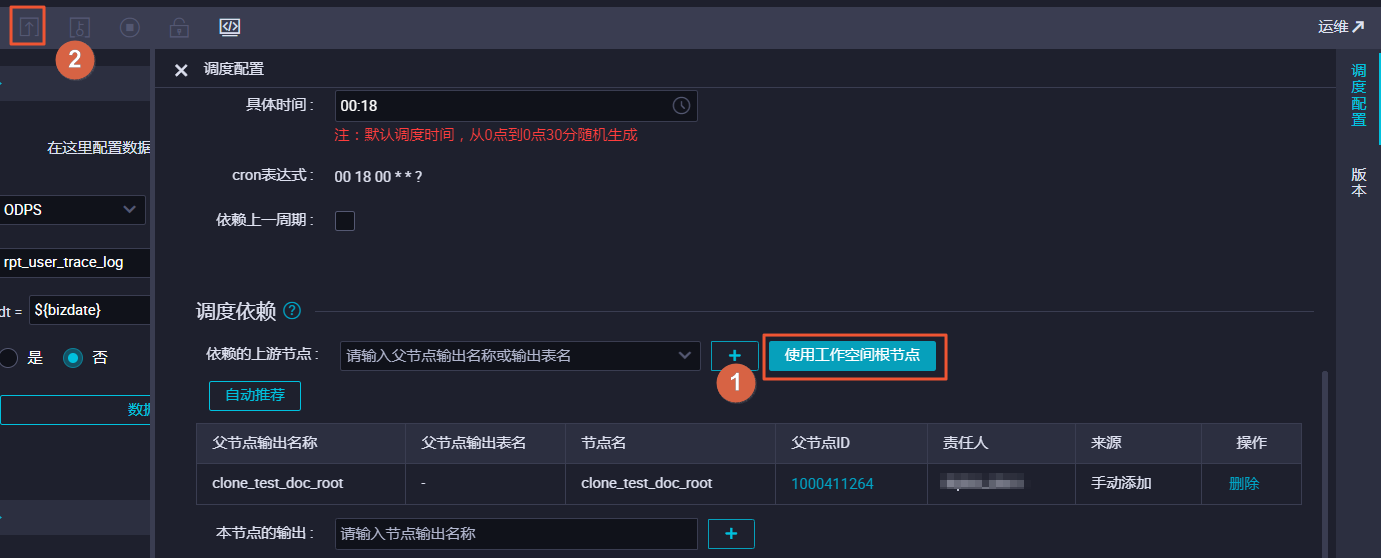
- 编辑您新建的数据同步任务节点,填写参数如下图所示。其中数据源bigdata_DOC是您的原始项目,数据源odps_first代表您当前的新建项目,表名是您需要同步数据的表rpt_user_trace_log。完成后单击调度配置。

- 单击使用工作空间根节点后,提交数据同步任务。
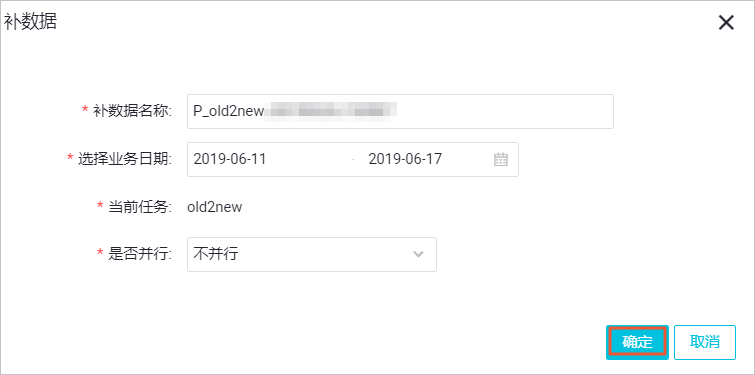
- 补数据
- 单击左上角的图标,选择全部产品 > 运维中心。
- 单击左侧导航栏中的周期任务运维 > 周期任务。
- 右键单击您的数据同步任务,选择补数据 > 当前节点。
- 本例中,需要补数据的日期分区为2019年6月11日到17日,您可以直接选择业务日期,进行多个分区的数据同步。完成设置后,单击确定。
- 在周期任务运维 > 补数据实例页面,您可以查看补数据实例任务运行状态,显示运行成功则说明完成数据同步。
- 验证结果
您可以在业务流程 > 数据开发中新建ODPS SQL类型节点,执行如下语句查看数据是否完成同步。select * from rpt_user_trace_log where dt BETWEEN '20190611' and '20190617';
- 新建数据源。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/170932.html