
本文为您介绍影响数据同步速度的因素、如何通过调整同步任务的并发配置来实现同步速度最大化、作业的限速选项,以及数据同步过慢的场景。
文档概述
- 同步速度受同步任务本身配置、数据库、网络等多方面影响,详情请参见:数据同步速度的影响因素。
- 同步任务整体速度慢可能出现在同步过程的各个阶段,本文以现象入手,为您提供各个阶段运行慢的解决方案,详情请参见:数据同步慢的场景及解决方案。
- 在数据库性能限制的情况下,同步速度并非越快越高,考虑到速度过高可能对数据库造成过大的压力从而影响生产,数据集成支持了限速选项,您可根据业务合理配置该值。详情请参见:限制同步速度。
数据同步速度的影响因素
数据同步速度受来源与目标端数据库环境及同步任务配置等因素影响,其中源端和目的端数据库的性能、负载和网络情况主要由您自己关注并进行调优。影响数据同步速度的因素如下:
| 因素 | 说明 |
|---|---|
| 来源端数据源 |
|
| 离线同步任务使用的调度资源组 | 离线同步任务将有调度资源下发至数据集成任务执行资源上执行,调度资源使用情况同样会影响整体数据集成同步效率。关于离线任务下发机制,详情请参见:任务下发机制。 |
| 离线同步任务配置 |
|
| 目的端数据源 |
|
数据同步慢的场景及解决方案
说明 离线同步任务日志详情请参见:离线同步日志分析。
| 数据同步慢的场景 | 现象 | 可能原因 | 解决方案 |
|---|---|---|---|
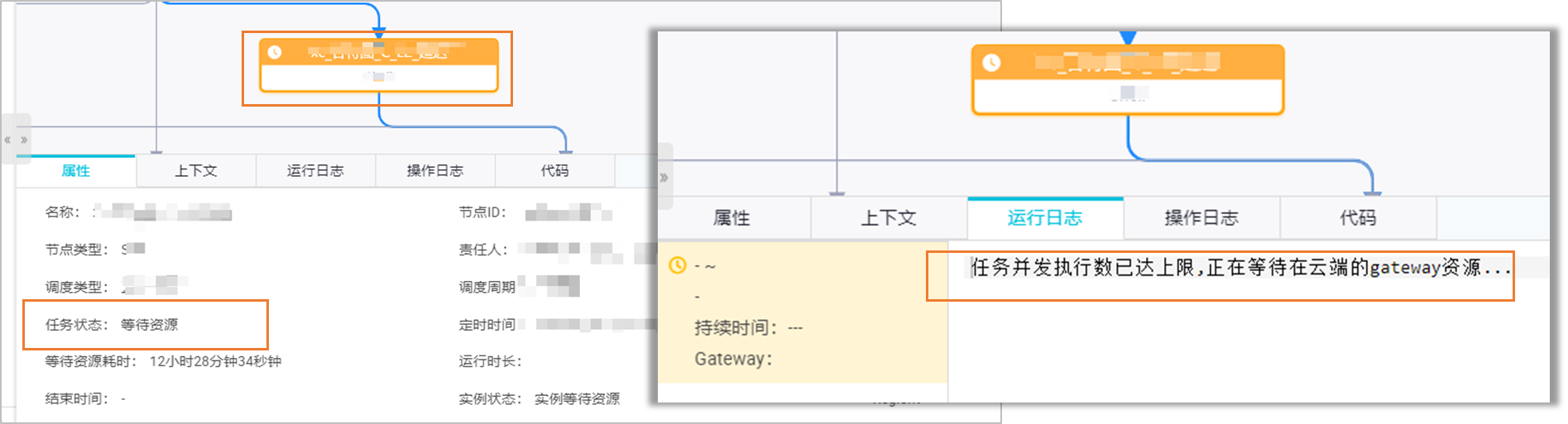
| 等待调度资源 |
|
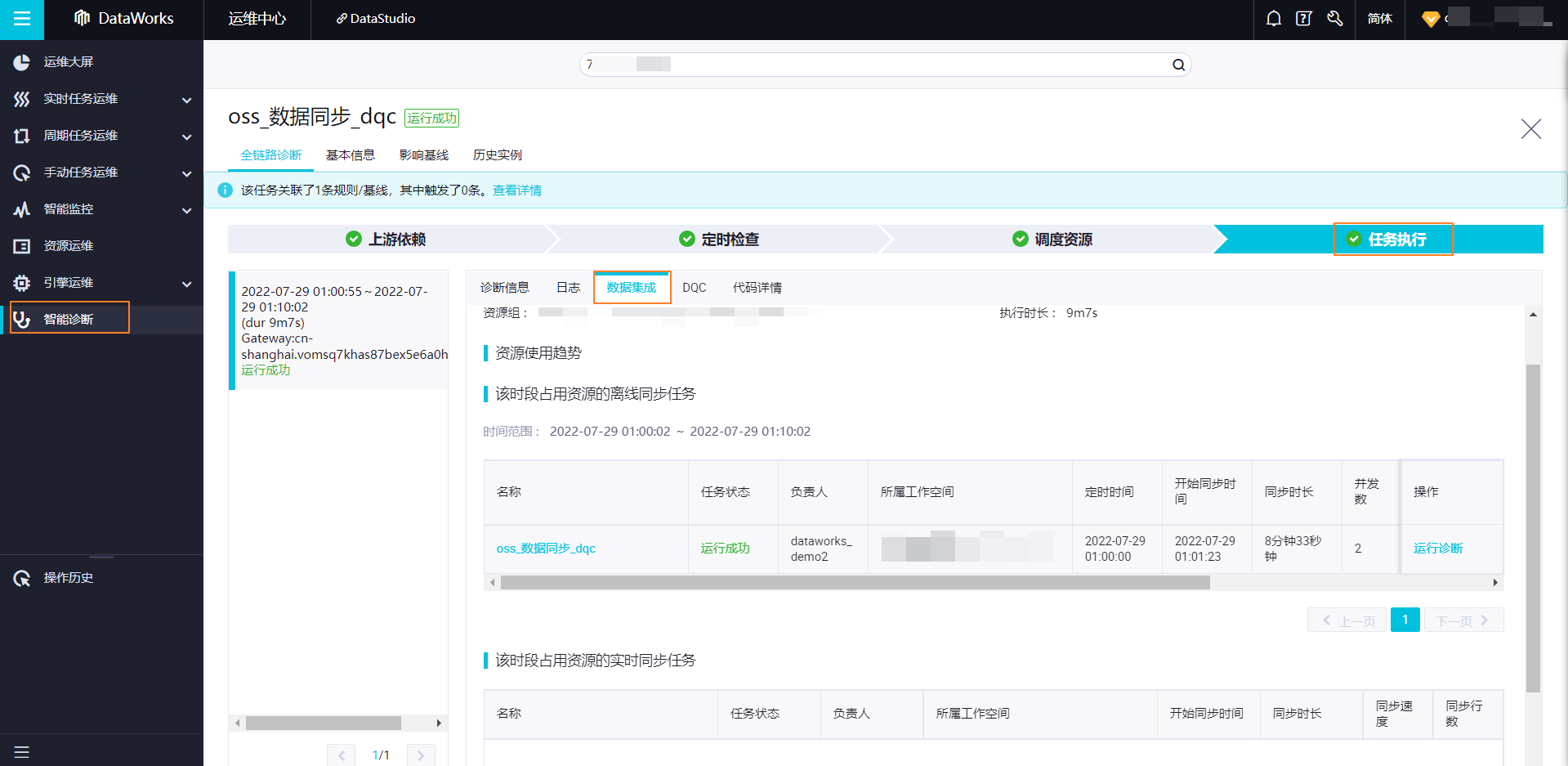
离线任务由调度资源组下发至引擎执行,因此,当离线任务调度资源组执行任务数到达上限,则需要等待资源组上执行的任务执行结束,释放资源。 | 您可以在运行诊断页面查看当前任务等待资源时,哪些任务占用资源。说明 若使用公共调度资源组,建议迁移到独享资源组上执行。 |
| 等待执行资源 | 同步任务日志显示wait。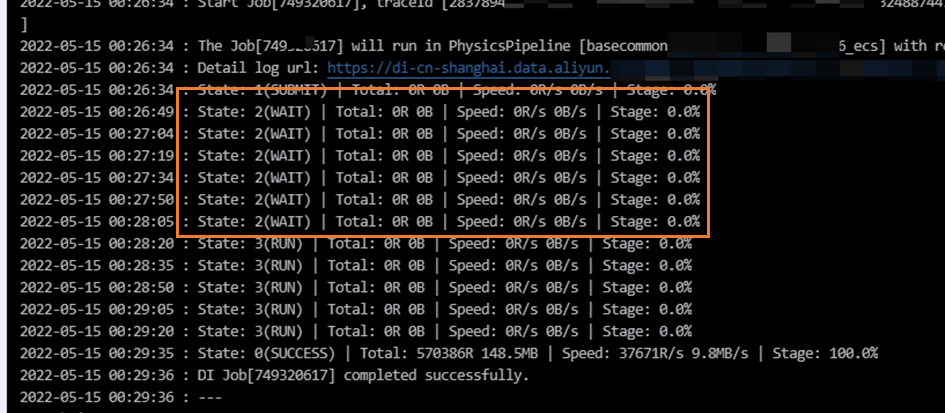  |
当前数据集成任务执行资源组剩余资源不够当前任务执行。
例如,资源组最大支持8个并发同时执行,若当前存在3个并发为3的任务,其中2个任务同时执行,那么机器剩余的并发为2,此时另一个并发为3的任务将由于资源组剩余资源不够,导致当前任务进入等待状态,日志显示wait。 |
检查资源组下是否有其他任务运行占用了大量资源,您可以通过以下方案解决此类问题:说明
|
| 同步任务运行速度过慢 | 同步任务日志显示run,但速度为0。此类情况任务并非未执行,如果长时间处于该状态,建议单击Detail log查看详细执行情况。 若Detail log中显示WaitReaderTime参数值大,表示等待从源端返回数据时间较长。 若Detail log中显示WaitReaderTime参数值大,表示等待从源端返回数据时间较长。 |
说明 无法保障公网环境下的数据同步速度。 |
|
| 同步任务日志显示run,但速度为0。此类情况任务并非未执行,如果长时间处于该状态,建议单击Detail log查看详细执行情况。若Detail log中显示WaitWriterTime参数值大,表示写入目标端时间较长。 |
说明 无法保障公网环境下的数据同步速度。 | ||
日志显示run,有速度,但同步过程速度慢。 |
说明 无法保障公网环境下的数据同步速度。 |
|

限制同步速度
数据集成同步任务默认不限速,任务将在所配置的并发数的限制上以最高能达到的速度进行同步。另一方面,考虑到速度过高可能对数据库造成过大的压力从而影响生产,数据集成同时提供了限速选项,您可以按照实际情况调优配置(建议选择限速之后,最高速度上限不应超过30 MB/s)。脚本模式通过如下示例代码配置限速,代表1 MB/s的传输带宽。
"setting": {
"speed": {
"throttle": true // 是否限流。
"mbps": 1, // 具体速率值。
}
}- throttle包括true和false:
- 当throttle设置为true时,表示限速,您必须设置mbps具体的数据值。如果没有设置mbps,程序运行将会出错或者速率异常。
- 当throttle设置为false时,表示不限速,则mbps的配置无意义。
- 流量度量值是数据集成本身的度量值,不代表实际网卡流量。通常,网卡流量往往是通道流量膨胀的1至2倍,实际流量膨胀取决于具体的数据存储系统传输序列化情况。
- 半结构化的单个文件没有切分键的概念,多个文件可以设置作业速率上限来提高同步的速度,但作业速率上限和文件的个数有关。 例如,有n个文件,作业速率上限最多设置为n MB/s:
- 如果设置n+1 MB/s,还是以n MB/s速度同步。
- 如果设置为n-1 MB/s,则以n-1 MB/s速度同步。
- 关系型数据库设置作业速率上限和切分键后,才能根据作业速率上限将表进行切分。关系型数据库通常只支持数值型作为切分键,但Oracle数据库支持以数值型和字符串类型作为切分键。
常见问题
- 数据同步任务where条件没有索引,导致全表扫描同步变慢。
- BatchSize或maxfilesize参数控制一次性批量提交的记录数大小,该值可以减少数据同步与数据库网络交互次数,并提升吞吐量。但如果该值设置过大,会导致数据同步运行进程OOM异常。出现上述报错后,请参见:离线同步常见问题。
附录:查看实际并发
在数据同步任务的详情日志页面,查找形式为JobContainer – Job set Channel-Number to 2 channels.的日志,此处的channels即为任务实际运行的并发度。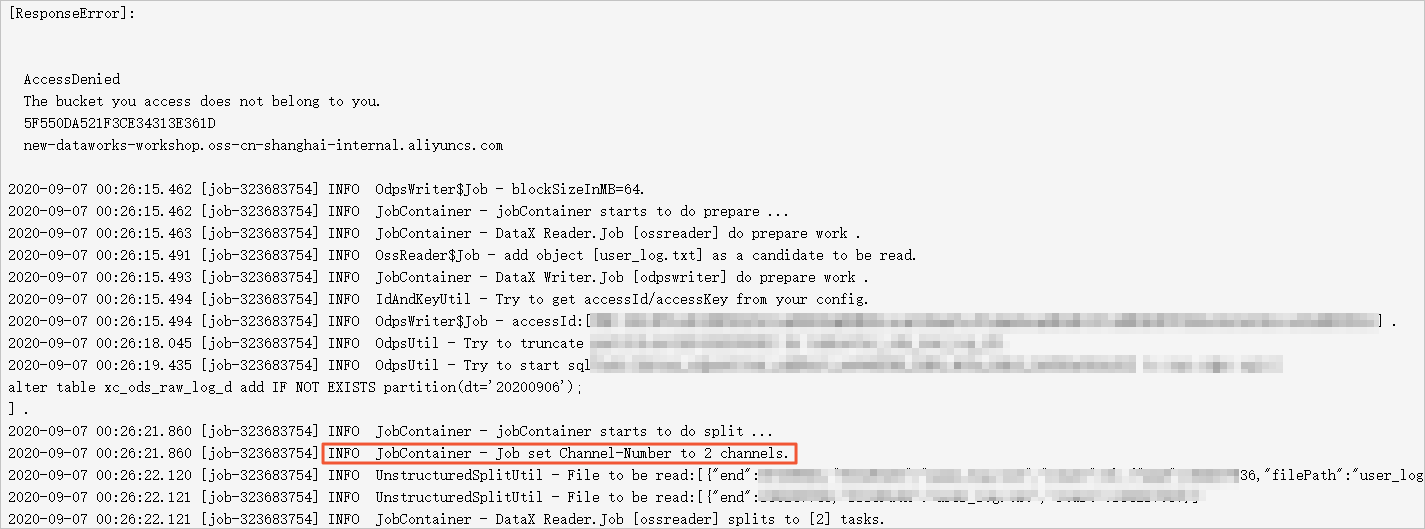
附录:并发度和资源的占用关系
在独享资源组中,占用关系包括并发度和CPU、内存的占用关系:
- 并发度和CPU的占用关系
在独享资源组中,并发度和CPU的占用关系为1:0.5,即拥有一台4 vCPU 8 GiB规格的ECS机器,其独享资源组的并发额度为8。最多能够同时运行8个并发度为1的离线同步任务,或4个并发度为2的离线同步任务。
当新提交至独享资源组的任务所需要的并发度大于独享资源组剩余的并发度额度时,新提交的任务将等待独享资源组中正在运行的任务结束,直至剩余的并发度额度满足新提交任务的并发度需求。说明 如果新提交任务设置的并发度超过独享资源组的最大并发额度,例如,向一台拥有4 vCPU 8 GiB规格的ECS机器的独享资源组提交一个并发度设置为10的任务,该任务将永远处于等待资源的状态。由于资源组根据任务被提交的先后顺序分配资源,后续提交的任务也将无法运行。
- 并发度和内存的占用关系在独享资源组中,单个任务的并发度和内存的占用关系为Min{768+(并发数-1)*256,8029} MB。但是,您可以在任务中通过设置,覆盖其对应关系。如果是脚本模式,请在JSON结构的配置文本中,通过JSON路径$.setting.jvmOption进行设置。
 您需要确保所有正在运行的任务使用内存的总和,比独享资源组中所有机器的内存总量小1 GB以上,任务才能平稳运行。如果未满足该条件,会因为Linux系统的OOM Killer机制强制停止任务的运行。说明 如果您未使用脚本模式加大任务的内存,则只需要考虑独享资源组并发度的额度对任务提交的限制。
您需要确保所有正在运行的任务使用内存的总和,比独享资源组中所有机器的内存总量小1 GB以上,任务才能平稳运行。如果未满足该条件,会因为Linux系统的OOM Killer机制强制停止任务的运行。说明 如果您未使用脚本模式加大任务的内存,则只需要考虑独享资源组并发度的额度对任务提交的限制。
附录:同步速度
不同数据源的并发读写速度会有很大的差异。下文为您介绍典型数据源在独享资源组中,单并发的同步速度:
- 不同数据源的Writer插件对应的单并发平均速度
Writer 单并发平均速度(KB/s) AnalyticDB for PostgreSQL 147.8 AnalyticDB for MySQL 181.3 ClickHouse 5259.3 DataHub 45.8 DRDS 93.1 Elasticsearch 74.0 FTP 565.6 GDB 17.1 HBase 2395.0 hbase20xsql 37.8 HDFS 1301.3 Hive 1960.4 HybridDB for MySQL 323.0 HybridDB for PostgreSQL 116.0 Kafka 0.9 LogHub 788.5 MongoDB 51.6 MySQL 54.9 ODPS 660.6 Oracle 66.7 OSS 3718.4 OTS 138.5 PolarDB 45.6 PostgreSQL 168.4 Redis 7846.7 SQLServer 8.3 Stream 116.1 TSDB 2.3 Vertica 272.0 - 不同数据源的Reader插件对应的单并发平均速度
Reader 单并发平均速度(KB/s) AnalyticDB for PostgreSQL 220.3 AnalyticDB for MySQL 248.6 DRDS 146.4 Elasticsearch 215.8 FTP 279.4 HBase 1605.6 hbase20xsql 465.3 HDFS 2202.9 Hologres 741.0 HybridDB for MySQL 111.3 HybridDB for PostgreSQL 496.9 Kafka 3117.2 LogHub 1014.1 MongoDB 361.3 MySQL 459.5 ODPS 207.2 Oracle 133.5 OSS 665.3 OTS 229.3 OTSStream 661.7 PolarDB 238.2 PostgreSQL 165.6 RDBMS 845.6 SQLServer 143.7 Stream 85.0 Vertica 454.3
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/169371.html