
数据集成的离线同步功能为您提供数据读取(Reader)和写入插件(Writer),方便您通过定义来源与去向数据源,并结合DataWorks调度参数使用,将源端数据库中全量或增量数据的同步至目标数据库中。本文为您介绍离线同步的相关能力。
使用限制
DataWorks的离线同步暂不支持跨时区同步数据。如果数据同步任务中的数据源与使用的DataWorks资源组不在同一个时区,则会导致同步的数据有误。
费用说明
- 数据集成同步任务运行会占用数据集成任务执行资源,DataWorks会根据您使用的资源进行收费,此外,离线同步任务通过调度系统下发至对应资源组运行时,还会产生调度相关费用。详情请参见资源费用明细:数据集成。说明
- 调度费用详情请参见资源费用明细:任务调度。
- 关于任务下发机制,详情请参见DataWorks资源组概述。
- 如果数据集成同步任务使用的数据源配置了公网地址,则执行同步任务时将产生公网流量费用。费用说明请参见公网流量计费说明。
功能概述
离线同步支持的能力如下图所示: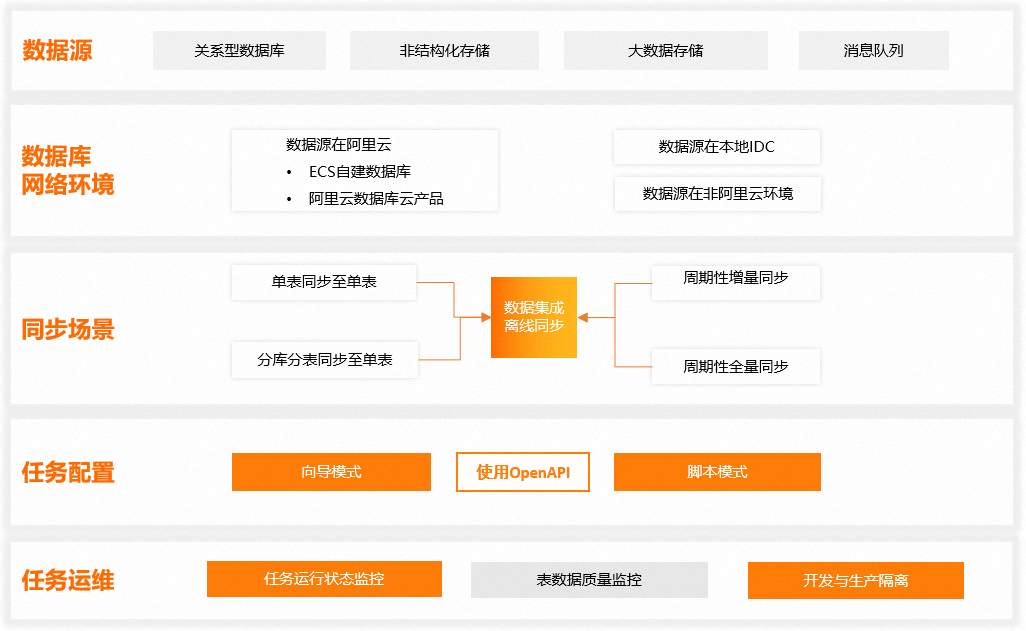

| 功能 | 描述 |
|---|---|
| 异构数据源间的数据同步 | 数据集成目前支持40+数据源类型,包括关系型数据库、非结构化存储、大数据存储、消息队列间的数据同步。您可以通过定义来源与去向数据源,并通过数据集成提供的数据抽取插件(Reader)、数据写入插件(Writer),实现任意结构化、半结构化数据源之间数据传输。详情请参见:支持的数据源与读写能力。 |
| 复杂网络环境下的数据同步 | 离线同步支持云数据库,本地IDC、ECS自建数据库或非阿里云数据库等环境下的数据同步。您可以根据数据库所在网络环境,选择合适的网络解决方案来实现数据源与资源组的网络连通。在配置同步任务前,您需要确保数据集成资源组与您将同步的数据来源端与目标端网络环境已经连通,对应数据库环境与网络连通配置详情请参见:配置资源组与网络连通。 |
| 数据同步场景 | 离线同步支持单表同步至目标端单表、分库分表同步至目标端单表两类同步场景。同时,结合DataWorks调度参数,实现增量数据和全量数据周期性写入到目标表对应分区功能。离线同步任务使用调度参数,再结合运维中心补数据功能,可实现基于一套任务配置,批量将历史数据同步至目标数据库或数据仓库指定表或表指定分区。调度参数说明请参见:调度参数支持的格式。说明
|
| 离线同步任务配置 | 您可以通过以下方式配置数据集成离线同步任务。
说明 任务配置相关能力说明请参见:离线同步任务配置相关能力。 |
| 离线同步任务运维 |
|
离线同步任务配置相关能力

| 支持的能力 | 说明 |
|---|---|
| 全量或增量数据同步 | 离线同步任务可以通过配置数据过滤并结合调度参数使用,来决定同步全量数据还是增量数据。不同插件增量同步配置方式不同,关于增量数据同步配置详情请参见:场景:配置增量数据离线同步任务。 |
| 定义字段映射关系并为目标表字段赋值 | 在同步任务配置过程中,您可通过字段映射,来定义源端字段与目标端字段的读取和写入关系,源端字段将会根据字段映射关系写入目标端对应类型的字段中。
|
| 作业速率上限控制 |
|
| 分布式执行任务 |
部分数据源支持分布式执行任务,分布式执行模式可以将您的任务切片分散到多台执行节点上并发执行,进而做到同步速度随执行集群规模做水平扩展,突破单机执行瓶颈。如果您对于同步性能有比较高的诉求可以使用分布式模式。 另外分布式模式也可以使用机器的碎片资源,对资源利用率友好。 说明 具体数据源是否支持分布式执行,详情请参见各插件文档及实际产品界面。 |
| 脏数据个数控制 | 数据集成默认允许脏数据产生,支持您对同步过程中产生的脏数据个数设置阈值,并定义其影响:
说明 脏数据是对于业务没有意义,格式非法或者同步过程中出现问题的数据。单条数据写入目标数据源过程中发生了异常,则此条数据为脏数据。 因此只要是写入失败的数据均被归类于脏数据。例如,源端是VARCHAR类型的数据写到INT类型的目标列中,导致因为转换不合理而无法写入的数据。您可以在同步任务配置时,控制同步过程中是否允许脏数据产生,并且支持控制脏数据条数,即当脏数据超过指定条数时,任务失败退出。 |
数据集成使用调度参数的相关说明
离线同步
数据集成离线同步任务中,可以使用调度参数来指定同步源表及目标表的数据路径以及数据范围,调度参数的配置方式与其他类型任务一致,没有特殊限制。
在同步任务运行时,任务中配置的占位符参数都会被替换为调度参数表达式所表达的实际值,然后再执行数据同步。
示例:创建一个离线同步任务,每天从源MySQL订单表中同步前一天新产生的订单数据到MaxCompute目标表的当天分区,原表订单的创建时间字段为gmd_created, 目标odps表的分区字段为ds,可以将任务配置如下:
同步任务配置: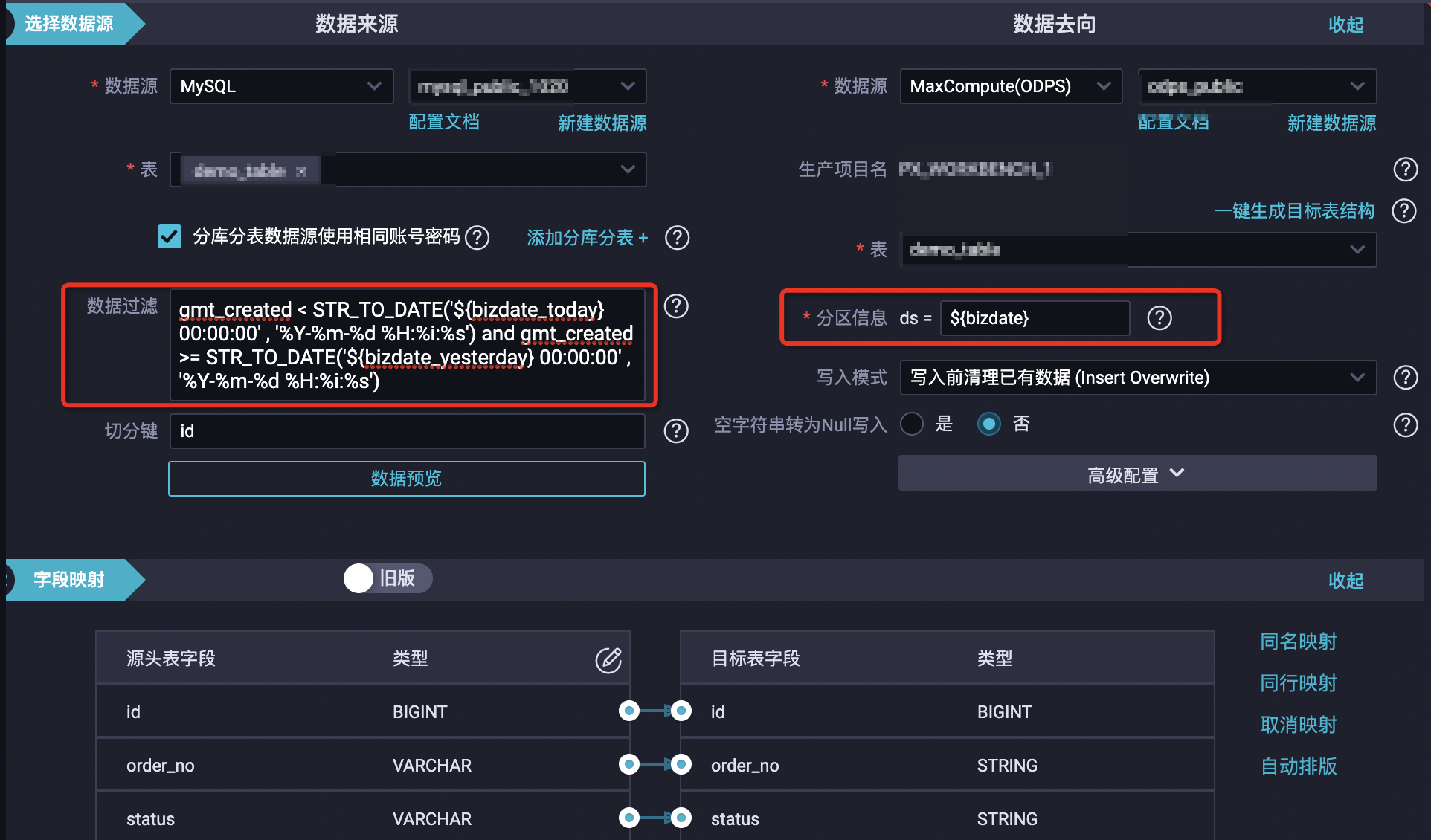 调度参数配置:订单表每天的增量数据,通过配置where过滤条件的方式进行筛选:
调度参数配置:订单表每天的增量数据,通过配置where过滤条件的方式进行筛选:
- bizdate_yesterday为表示增量订单的归属日期(定时任务的前一日日期),调度参数表达式为${yyyy-mm-dd}。
- bizdate_today表示增量订单的截止日期(定时任务的当日日期),调度参数表达式为$[yyyy-mm-dd]。
- bizdate_today和bizdate_yesterday为调度参数名字,可以自行指定,在实际执行时 bizdate_today和bizdate_yesterday都会被替换为调度参数所表达的时间。
目标MaxCompute表分区名称也以调度参数的方式指定,$bizdate表示业务日期,定时任务执行时,任务配置的分区表达式会替换为调度参数所表达的业务日期。调度参数表达式的详细配置说明请参考文档:配置并使用调度参数。以上的例子在运行时任务代码配置的占位符参数被替换如下(图示业务日期选择为20221116):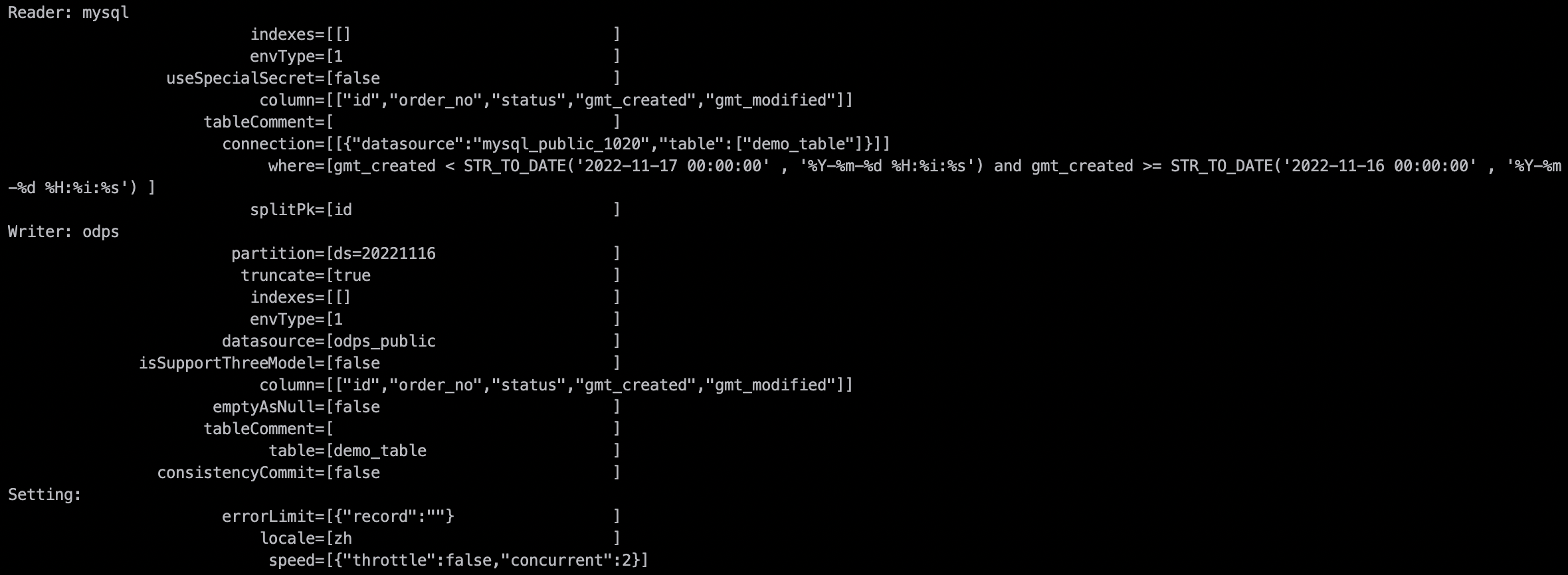 说明 任务配置中如果配置了占位符,一定要设置其对应的调度参数。
说明 任务配置中如果配置了占位符,一定要设置其对应的调度参数。
整库离线同步
对于整库离线同步,仅支持使用如下调度参数:
bizdate=${yyyymmdd} year=$[yyyy] month=$[mm] day=$[dd] hour=$[hh24]
任务配置时,变量需定义为${bizdate}, ${year},${month}, ${hour}, ${day}, ${hour}
示例:整库离线同步至MaxCompute(一次性全量周期性增量)天增量筛选的where条件可以配置成:STR_TO_DATE('${bizdate}', '%Y%m%d') <= columnName AND columnName < DATE_ADD(STR_TO_DATE('${bizdate}', '%Y%m%d'), interval 1 day)如下图所示:
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/167061.html