
本方案旨在帮助大模型开发者快速上手灵骏智算平台,实现大语言模型(Qwen-7B、Qwen-14B和Qwen-72B)的高效分布式训练、三阶段指令微调、模型离线推理和在线服务部署等完整的开发流程。以Qwen-7B模型为例,为您详细介绍该方案的开发流程。
前提条件
本方案以Qwen-7B v1.1.4版本的模型为例,在开始执行操作前,请确认您已经完成以下准备工作:
-
已开通PAI(DSW、DLC、EAS)并创建了默认的工作空间。具体操作,请参见开通PAI并创建默认工作空间。
-
已购买灵骏智算资源并创建资源配额。不同的模型参数量支持的资源规格列表如下,请根据您实际使用的模型参数量选择合适的资源,关于灵骏智算资源的节点规格详情,请参见灵骏Serverless版机型定价详情。具体操作,请参见新建资源组并购买灵骏智算资源和新增灵骏智算资源资源配额。
模型参数量
全参数训练资源
推理资源(最低)
Megatron训练模型切片
7B
8*gu7xf、gu7ef
1*V100-32G、1*A10-22G
TP1、PP1
14B
8*gu7xf、gu7ef
2*V100-32G、2*A10-22G
TP2、PP1
72B
(4*8)*gu7xf、gu7ef
6*V100-32G、2*gu7xf
TP8、PP2
-
已创建阿里云文件存储(通用型NAS)类型的数据集,用于存储训练所需的文件和结果文件。默认挂载路径配置为
/mnt/data/nas。具体操作,请参见创建及管理数据集。 -
已创建DSW实例,其中关键参数配置如下。具体操作,请参见创建及管理DSW实例。
-
资源组:选择已创建的灵骏智算资源的资源配额,并配置以下参数:
-
CPU(核数):90。
-
内存(GB):1024。
-
共享内存(GB):1024。
-
GPU(卡数):至少为8。
-
-
存储配置:单击共享数据集,选择已创建的数据集。
-
选择镜像:在镜像URL页签,配置镜像为
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pytorch-training:1.12-ubuntu20.04-py3.10-cuda11.3-megatron-patch-llm。
-
-
如果使用RAM用户完成以下相关操作,需要为RAM用户授予DSW、DLC或EAS的操作权限。具体操作,请参见云产品依赖与授权:DSW、云产品依赖与授权:DLC或云产品依赖与授权:EAS。
使用限制
仅支持在华北6(乌兰察布)地域使用该最佳实践。
步骤一:准备通义千问模型
本案例提供了以下三种下载模型的方式,您可以根据需要选择其中一种。具体操作步骤如下:
-
进入PAI-DSW开发环境。
-
登录PAI控制台。
-
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
-
在页面左上方,选择使用服务的地域:华北6(乌兰察布)。
-
在左侧导航栏,选择模型开发与训练 > 交互式建模(DSW)。
-
单击目标实例操作列下的打开。
-
-
在顶部菜单栏单击Terminal,在该页签中单击创建terminal。
-
下载通义千问模型。
从ModelScope社区下载模型
-
在Terminal中执行以下命令安装ModelScope。
-
执行以下命令进入Python环境。
-
以Qwen-7B模型为例,下载模型文件的代码示例如下。如果您需要下载Qwen-14B或Qwen-72B模型文件,请单击下述表格中相应的模型链接,并查看相应的代码。
-
按
Ctrl+D,退出Python环境。 -
执行以下命令将已下载的通义千问模型移动到对应文件夹中。
pip install modelscope单击此处查看回显信息,结果中出现的WARNING信息可以忽略。
Looking in indexes: https://mirrors.cloud.aliyuncs.com/pypi/simple Collecting modelscope Downloading https://mirrors.cloud.aliyuncs.com/pypi/packages/ac/05/75b5d750608d7354dc3dd023dca7101e5f3b4645cb3e5b816536d472a058/modelscope-1.9.5-py3-none-any.whl (5.4 MB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 5.4/5.4 MB 104.7 MB/s eta 0:00:00 Requirement already satisfied: pyyaml in /opt/conda/lib/python3.8/site-packages (from modelscope) (5.4.1) Requirement already satisfied: pandas in /opt/conda/lib/python3.8/site-packages (from modelscope) (1.5.3) Requirement already satisfied: addict in /opt/conda/lib/python3.8/site-packages (from modelscope) (2.4.0) Requirement already satisfied: numpy in /opt/conda/lib/python3.8/site-packages (from modelscope) (1.22.2) Collecting simplejson>=3.3.0 Downloading https://mirrors.cloud.aliyuncs.com/pypi/packages/33/5f/b9506e323ea89737b34c97a6eda9d22ad6b771190df93f6eb72657a3b996/simplejson-3.19.2-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl (136 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 136.6/136.6 kB 70.2 MB/s eta 0:00:00 Collecting gast>=0.2.2 Downloading https://mirrors.cloud.aliyuncs.com/pypi/packages/fa/39/5aae571e5a5f4de9c3445dae08a530498e5c53b0e74410eeeb0991c79047/gast-0.5.4-py3-none-any.whl (19 kB) Requirement already satisfied: Pillow>=6.2.0 in /opt/conda/lib/python3.8/site-packages (from modelscope) (9.3.0) Requirement already satisfied: oss2 in /opt/conda/lib/python3.8/site-packages (from modelscope) (2.17.0) Requirement already satisfied: filelock>=3.3.0 in /opt/conda/lib/python3.8/site-packages (from modelscope) (3.11.0) Requirement already satisfied: urllib3>=1.26 in /opt/conda/lib/python3.8/site-packages (from modelscope) (1.26.12) Requirement already satisfied: datasets=2.8.0 in /opt/conda/lib/python3.8/site-packages (from modelscope) (2.11.0) Requirement already satisfied: attrs in /opt/conda/lib/python3.8/site-packages (from modelscope) (22.2.0) Requirement already satisfied: scipy in /opt/conda/lib/python3.8/site-packages (from modelscope) (1.9.3) Requirement already satisfied: yapf in /opt/conda/lib/python3.8/site-packages (from modelscope) (0.32.0) Requirement already satisfied: pyarrow!=9.0.0,>=6.0.0 in /opt/conda/lib/python3.8/site-packages (from modelscope) (11.0.0) Requirement already satisfied: setuptools in /opt/conda/lib/python3.8/site-packages (from modelscope) (65.5.0) Requirement already satisfied: requests>=2.25 in /opt/conda/lib/python3.8/site-packages (from modelscope) (2.28.1) Requirement already satisfied: einops in /opt/conda/lib/python3.8/site-packages (from modelscope) (0.6.0) Requirement already satisfied: python-dateutil>=2.1 in /opt/conda/lib/python3.8/site-packages (from modelscope) (2.8.2) Collecting sortedcontainers>=1.5.9 Downloading https://mirrors.cloud.aliyuncs.com/pypi/packages/32/46/9cb0e58b2deb7f82b84065f37f3bffeb12413f947f9388e4cac22c4621ce/sortedcontainers-2.4.0-py2.py3-none-any.whl (29 kB) Requirement already satisfied: tqdm>=4.64.0 in /opt/conda/lib/python3.8/site-packages (from modelscope) (4.65.0) Requirement already satisfied: dill=0.3.0 in /opt/conda/lib/python3.8/site-packages (from datasets=2.8.0->modelscope) (0.3.6) Requirement already satisfied: multiprocess in /opt/conda/lib/python3.8/site-packages (from datasets=2.8.0->modelscope) (0.70.14) Requirement already satisfied: aiohttp in /opt/conda/lib/python3.8/site-packages (from datasets=2.8.0->modelscope) (3.8.4) Requirement already satisfied: responses<0.19 in /opt/conda/lib/python3.8/site-packages (from datasets=2.8.0->modelscope) (0.18.0) Requirement already satisfied: huggingface-hub=0.11.0 in /opt/conda/lib/python3.8/site-packages (from datasets=2.8.0->modelscope) (0.16.4) Requirement already satisfied: fsspec[http]>=2021.11.1 in /opt/conda/lib/python3.8/site-packages (from datasets=2.8.0->modelscope) (2023.4.0) Requirement already satisfied: packaging in /opt/conda/lib/python3.8/site-packages (from datasets=2.8.0->modelscope) (21.3) Requirement already satisfied: xxhash in /opt/conda/lib/python3.8/site-packages (from datasets=2.8.0->modelscope) (3.2.0) Requirement already satisfied: six>=1.5 in /opt/conda/lib/python3.8/site-packages (from python-dateutil>=2.1->modelscope) (1.16.0) Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.8/site-packages (from requests>=2.25->modelscope) (2022.9.24) Requirement already satisfied: charset-normalizer=2 in /opt/conda/lib/python3.8/site-packages (from requests>=2.25->modelscope) (2.0.4) Requirement already satisfied: idna=2.5 in /opt/conda/lib/python3.8/site-packages (from requests>=2.25->modelscope) (3.4) Requirement already satisfied: aliyun-python-sdk-kms>=2.4.1 in /opt/conda/lib/python3.8/site-packages (from oss2->modelscope) (2.16.0) Requirement already satisfied: aliyun-python-sdk-core>=2.13.12 in /opt/conda/lib/python3.8/site-packages (from oss2->modelscope) (2.13.36) Requirement already satisfied: crcmod>=1.7 in /opt/conda/lib/python3.8/site-packages (from oss2->modelscope) (1.7) Requirement already satisfied: pycryptodome>=3.4.7 in /opt/conda/lib/python3.8/site-packages (from oss2->modelscope) (3.15.0) Requirement already satisfied: pytz>=2020.1 in /opt/conda/lib/python3.8/site-packages (from pandas->modelscope) (2022.7.1) Requirement already satisfied: cryptography>=2.6.0 in /opt/conda/lib/python3.8/site-packages (from aliyun-python-sdk-core>=2.13.12->oss2->modelscope) (38.0.3) Requirement already satisfied: jmespath=0.9.3 in /opt/conda/lib/python3.8/site-packages (from aliyun-python-sdk-core>=2.13.12->oss2->modelscope) (0.10.0) Requirement already satisfied: async-timeout=4.0.0a3 in /opt/conda/lib/python3.8/site-packages (from aiohttp->datasets=2.8.0->modelscope) (4.0.2) Requirement already satisfied: yarl=1.0 in /opt/conda/lib/python3.8/site-packages (from aiohttp->datasets=2.8.0->modelscope) (1.8.2) Requirement already satisfied: frozenlist>=1.1.1 in /opt/conda/lib/python3.8/site-packages (from aiohttp->datasets=2.8.0->modelscope) (1.3.3) Requirement already satisfied: multidict=4.5 in /opt/conda/lib/python3.8/site-packages (from aiohttp->datasets=2.8.0->modelscope) (6.0.4) Requirement already satisfied: aiosignal>=1.1.2 in /opt/conda/lib/python3.8/site-packages (from aiohttp->datasets=2.8.0->modelscope) (1.3.1) Requirement already satisfied: typing-extensions>=3.7.4.3 in /opt/conda/lib/python3.8/site-packages (from huggingface-hub=0.11.0->datasets=2.8.0->modelscope) (4.4.0) Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /opt/conda/lib/python3.8/site-packages (from packaging->datasets=2.8.0->modelscope) (3.0.9) Requirement already satisfied: cffi>=1.12 in /opt/conda/lib/python3.8/site-packages (from cryptography>=2.6.0->aliyun-python-sdk-core>=2.13.12->oss2->modelscope) (1.15.1) Requirement already satisfied: pycparser in /opt/conda/lib/python3.8/site-packages (from cffi>=1.12->cryptography>=2.6.0->aliyun-python-sdk-core>=2.13.12->oss2->modelscope) (2.21) Installing collected packages: sortedcontainers, simplejson, gast, modelscope Successfully installed gast-0.5.4 modelscope-1.9.5 simplejson-3.19.2 sortedcontainers-2.4.0 WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venvpython# ### Loading Model and Tokenizer from modelscope.hub.snapshot_download import snapshot_download model_dir = snapshot_download('qwen/Qwen-7B', 'v1.1.4') # model_dir = snapshot_download('qwen/Qwen-14B', 'v1.0.4') # model_dir = snapshot_download('qwen/Qwen-72B') # 获取下载路径 print(model_dir) # /root/.cache/modelscope/hub/qwen/Qwen-7B模型类型
模型链接
模型名称
版本
Qwen-7B
ModelScope魔搭社区
qwen/Qwen-7B
v1.1.4
Qwen-7B-chat
ModelScope魔搭社区
qwen/Qwen-7B-Chat
Qwen-14B
ModelScope魔搭社区
qwen/Qwen-14B
v1.0.4
Qwen-14B-chat
ModelScope魔搭社区
qwen/Qwen-14B-Chat
Qwen-72B
ModelScope魔搭社区
qwen/Qwen-72B
master
Qwen-72B-chat
ModelScope魔搭社区
qwen/Qwen-72B-Chat
# mkdir -p /mnt/workspace/qwen-ckpts/${后缀为hf的ckpt文件夹} mkdir -p /mnt/workspace/qwen-ckpts/qwen-7b-hf # cp -r ${在此处填写已下载的模型路径}/* /mnt/workspace/qwen-ckpts/${后缀为hf的ckpt文件夹} cp -r /root/.cache/modelscope/hub/qwen/Qwen-7B/* /mnt/workspace/qwen-ckpts/qwen-7b-hf从Huggingface社区下载模型
在DSW的Terminal中执行以下命令下载模型文件。本方案以下载Qwen-7B模型为例,如果您需要下载Qwen-14B或Qwen-72B的模型文件,请参照下方代码进行修改。
mkdir /mnt/workspace/qwen-ckpts cd /mnt/workspace/qwen-ckpts git clone https://huggingface.co/Qwen/Qwen-7B # git clone https://huggingface.co/Qwen/Qwen-7B-Chat # git clone https://huggingface.co/Qwen/Qwen-14B # git clone https://huggingface.co/Qwen/Qwen-14B-Chat # git clone https://huggingface.co/Qwen/Qwen-72B # git clone https://huggingface.co/Qwen/Qwen-72B-Chat从阿里云对象存储OSS下载模型
您可以使用wget命令直接从OSS系统下载预先放置的Qwen-7B模型。
mkdir /mnt/workspace/qwen-ckpts cd /mnt/workspace/qwen-ckpts wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-ckpts/qwen-7b-hf.tgz tar zxvf qwen-7b-hf.tgz -
步骤二:准备预训练数据
建议您在DSW实例中准备预训练数据。本案例以WuDaoCorpora2.0数据集(该数据集仅供研究使用)为例,介绍Megatron训练数据的预处理流程。您可以直接下载PAI已准备好的小规模样本数据,也可以按照以下操作步骤自行准备预训练数据。
使用PAI处理好的小规模样本数据
为了方便您试用该案例,PAI也提供了已经处理好的小规模样本数据,您可以在DSW的Terminal中执行以下命令下载样本数据。
mkdir /mnt/workspace/qwen-datasets/
cd /mnt/workspace/qwen-datasets
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/alpaca_zh-qwen-train.json
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/alpaca_zh-qwen-valid.json
mkdir -p /mnt/workspace/qwen-datasets/wudao
cd /mnt/workspace/qwen-datasets/wudao
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/wudao_qwenbpe_content_document.bin
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-datasets/wudao_qwenbpe_content_document.idx自行处理数据
-
下载WuDaoCorpora2.0开源数据集到
/mnt/workspace/qwen-datasets工作目录下。本案例将解压后的文件夹命名为wudao_200g。PAI提供了部分样例数据作为示例,您可以在DSW的Terminal中执行以下命令下载并解压数据集。
mkdir /mnt/workspace/qwen-datasets cd /mnt/workspace/qwen-datasets wget https://atp-modelzoo.oss-cn-hangzhou.aliyuncs.com/release/datasets/WuDaoCorpus2.0_base_sample.tgz tar zxvf WuDaoCorpus2.0_base_sample.tgz mv WuDaoCorpus2.0_base_sample wudao_200g -
在Terminal中执行以下命令,对Wudao数据执行数据集清洗并进行文件格式转换,最终生成汇总的merged_wudao_cleaned.json文件。
#! /bin/bash set -ex # 请在此处设置原始数据所在路径。 data_dir=/mnt/workspace/qwen-datasets/wudao_200g # 开始数据清洗流程。 dataset_dir=$(dirname $data_dir) mkdir -p ${dataset_dir}/cleaned_wudao_dataset cd ${dataset_dir}/cleaned_wudao_dataset wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/llama2-codes/preprocess_wudao2.py # 此处与上一节不同,增加了key参数设为text。 python preprocess_wudao2.py -i ${data_dir} -o ${dataset_dir}/cleaned_wudao_dataset -k text -p 32 # 合并清洗后的数据。 mkdir ${dataset_dir}/wudao cd ${dataset_dir}/wudao find ${dataset_dir}/cleaned_wudao_dataset -name "*.json" -exec cat {} + > ${dataset_dir}/wudao/merged_wudao_cleaned.json rm -rf ${dataset_dir}/cleaned_wudao_dataset命令执行完成后,
qwen-datasets目录的文件结构如下,新增了一个wudao文件夹。qwen-datasets ├── wudao_200g └── wudao └── merged_wudao_cleaned.json -
在Terminal中执行以下命令,利用生成的merged_wudao_cleaned.json文件将数据拆分成若干组并进行压缩,以便于后续实现多线程处理。
apt-get update apt-get install zstd # 此处设置分块数为10,如数据处理慢可设置稍大。 NUM_PIECE=10 # 对merged_wudao_cleaned.json文件进行处理。 mkdir -p ${dataset_dir}/cleaned_zst/ # 查询数据总长度,对数据进行拆分。 NUM=$(sed -n '$=' ${dataset_dir}/wudao/merged_wudao_cleaned.json) echo "total line of dataset is $NUM, data will be split into $NUM_PIECE pieces for processing" NUM=`expr $NUM / $NUM_PIECE` echo "each group is processing $NUM sample" split_dir=${dataset_dir}/split mkdir $split_dir split -l $NUM --numeric-suffixes --additional-suffix=.jsonl ${dataset_dir}/wudao/merged_wudao_cleaned.json $split_dir/ # 数据压缩。 o_path=${dataset_dir}/cleaned_zst/ mkdir -p $o_path files=$(ls $split_dir/*.jsonl) for filename in $files do f=$(basename $filename) zstd -z $filename -o $o_path/$f.zst & done rm -rf $split_dir rm ${dataset_dir}/wudao/merged_wudao_cleaned.json命令执行完成后,
qwen-datasets目录的文件结构如下。新增了一个cleaned_zst文件夹,每个子文件夹里有10个压缩文件。qwen-datasets ├── wudao_200g ├── wudao └── cleaned_zst ├── 00.jsonl.zst │ ... └── 09.jsonl.zst -
制作MMAP格式的预训练数据集。
MMAP数据是一种预先执行tokenize的数据格式,可以减少训练微调过程中等待数据读入的时间,尤其在处理大规模数据时优势更为突出。具体操作步骤如下:
-
在DSW的Terminal中执行以下命令,将Megatron格式的模型训练工具源代码PAI-Megatron-Patch拷贝至DSW的工作目录
/mnt/workspace/下。cd /mnt/workspace/ # 方式一:通过开源网站获取训练代码。 git clone --recurse-submodules https://github.com/alibaba/Pai-Megatron-Patch.git # 方式二:通过wget方式获取训练代码,需要执行tar zxvf Pai-Megatron-Patch.tgz进行解压。 wget https://atp-modelzoo.oss-cn-hangzhou.aliyuncs.com/release/models/Pai-Megatron-Patch.tgz -
在Terminal中执行以下命令将数据转换成MMAP格式。
命令执行成功后,在
/mnt/workspace/qwen-datasets/wudao目录下生成.bin和.idx文件。# 安装Qwen依赖的tokenizer库包。 pip install tiktoken # 请在此处设置数据集路径和工作路径。 export dataset_dir=/mnt/workspace/qwen-datasets export WORK_DIR=/mnt/workspace # 分别为训练集、验证集生成mmap格式预训练数据集。 cd ${WORK_DIR}/Pai-Megatron-Patch/toolkits/pretrain_data_preprocessing bash run_make_pretraining_dataset.sh \ ../../Megatron-LM-23.04 \ ${WORK_DIR}/Pai-Megatron-Patch/ \ ${dataset_dir}/cleaned_zst/ \ qwenbpe \ ${dataset_dir}/wudao/ \ ${WORK_DIR}/qwen-ckpts/qwen-7b-hf rm -rf ${dataset_dir}/cleaned_zst其中运行run_make_pretraining_dataset.sh输入的六个启动参数说明如下:
参数
描述
MEGATRON_PATH=$1
设置开源Megatron的代码路径。
MEGATRON_PATCH_PATH=$2
设置Megatron Patch的代码路径。
input_data_dir=$3
打包后的Wudao数据集的文件夹路径。
tokenizer=$4
指定分词器的类型为qwenbpe。
output_data_dir=$5
指定输出的
.bin和.idx文件的保存路径。load_dir=$6
生成的tokenizer_config.json文件的路径。
脚本执行完成后,
qwen-datasets目录的文件结构如下。qwen-datasets ├── wudao_200g └── wudao ├── wudao_qwenbpe_content_document.bin └── wudao_qwenbpe_content_document.idx
-
步骤三:Megatron训练
您可以按照以下流程进行Megatron训练。
模型格式转换
将Huggingface格式的模型文件转换为Megatron格式。
下载转换好的Megatron模型
为方便您试用该案例,PAI提供了已经转换好格式的模型。您可以在Terminal中执行以下命令下载模型。
cd /mnt/workspace/
mkdir qwen-ckpts
cd qwen-ckpts
wget https://atp-modelzoo-wlcb-pai.oss-cn-wulanchabu.aliyuncs.com/release/models/pai-megatron-patch/qwen-ckpts/qwen-7b-hf-to-mg-tp1-pp1.tgz
tar -zxf qwen-7b-hf-to-mg-tp1-pp1.tgz
mv qwen-7b-hf-to-mg-tp1-pp1 qwen-7b-hf-to-megatron-tp1-pp1自行将Huggingface格式的模型转换成Megatron格式
在Terminal中执行以下命令,使用PAI提供的模型转换工具,将Huggingface格式的模型文件转换为Megatron格式:
# 转换模型。
cd /mnt/workspace/Pai-Megatron-Patch/toolkits/model_checkpoints_convertor/qwen
sh model_convertor.sh \
../../../Megatron-LM-main \
/mnt/workspace/qwen-ckpts/qwen-7b-hf \
/mnt/workspace/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \
1 \
1 \
qwen-7b \
0 \
false其中运行model_convertor.sh需要传入的参数说明如下:
|
参数 |
描述 |
|
MEGATRON_PATH=$1 |
设置开源Megatron的代码路径。 |
|
SOURCE_CKPT_PATH=$2 |
Huggingface格式的模型文件路径。 |
|
TARGET_CKPT_PATH=$3 |
转换为Megatron格式模型后保存的路径。 |
|
TP=$4 |
张量切片数量,与训练保持一致。不同参数量下的切片数量不同,在转换模型时需进行针对性修改:
|
|
PP=$5 |
流水切片数量,与训练保持一致。不同参数量下的切片数量不同,在转换模型时需进行针对性修改:
|
|
MN=$6 |
模型名称:qwen-7b、qwen-14b或qwen-72b。 |
|
EXTRA_VOCAB_SIZE=$7 |
额外词表大小。 |
|
mg2hf=$8 |
是否为Megatron格式转Huggingface格式。 |
预训练模型
您可以在DSW单机环境中训练模型,也可以在DLC环境中提交多机多卡分布式训练任务,训练过程大约持续2个小时。任务执行成功后,模型文件将输出到/mnt/workspace/output_megatron_qwen/目录下。
DSW单机预训练模型
以Qwen-7B模型为例,在Terminal中运行的代码示例如下:
export WORK_DIR=/mnt/workspace
cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen
sh run_pretrain_megatron_qwen.sh \
dsw \
${WORK_DIR}/Pai-Megatron-Patch \
7B \
1 \
8 \
1e-5 \
1e-6 \
2048 \
2048 \
85 \
fp16 \
1 \
1 \
sel \
true \
false \
false \
false \
100000 \
${WORK_DIR}/qwen-datasets/wudao/wudao_qwenbpe_content_document \
${WORK_DIR}/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \
100000000 \
10000 \
${WORK_DIR}/output_megatron_qwen/ 其中运行run_pretrain_megatron_qwen.sh需要传入的参数说明如下:
|
参数 |
描述 |
|
ENV=$1 |
配置运行环境:
|
|
MEGATRON_PATH=$2 |
设置开源Megatron的代码路径。 |
|
MODEL_SIZE=$3 |
模型结构参数量级:7B、14B或72B。 |
|
BATCH_SIZE=$4 |
每卡训练一次迭代样本数:4或8。 |
|
GLOBAL_BATCH_SIZE=$5 |
全局Batch Size。 |
|
LR=$6 |
学习率:1e-5或5e-5。 |
|
MIN_LR=$7 |
最小学习率:1e-6或5e-6。 |
|
SEQ_LEN=$8 |
序列长度。 |
|
PAD_LEN=${9} |
Padding长度。 |
|
EXTRA_VOCAB_SIZE=${10} |
词表扩充大小:
|
|
PR=${11} |
训练精度:fp16或bf16。 |
|
TP=${12} |
模型并行度。 |
|
PP=${13} |
流水并行度。 |
|
AC=${14} |
激活检查点模式:
|
|
DO=${15} |
是否使用Megatron版Zero-1降显存优化器:
|
|
FL=${16} |
是否打开Flash Attention:
|
|
SP=${17} |
是否使用序列并行:
|
|
TE=${18} |
是否开启Transformer-engine加速技术,需H800显卡。 |
|
SAVE_INTERVAL=${19} |
保存CheckPoint文件的间隔。 |
|
DATASET_PATH=${20} |
训练数据集路径。 |
|
PRETRAIN_CHECKPOINT_PATH=${21} |
预训练模型路径。 |
|
TRAIN_TOKENS=${22} |
训练Tokens。 |
|
WARMUP_TOKENS=${23} |
预热Token数。 |
|
OUTPUT_BASEPATH=${24} |
训练输出模型文件的路径。 |
DLC分布式预训练模型
在单机开发调试完成后,您可以在DLC环境中配置多机多卡的分布式任务。具体操作步骤如下:
-
进入新建任务页面。
-
登录PAI控制台。
-
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
-
在工作空间页面的左侧导航栏选择模型开发与训练 > 分布式训练(DLC),在分布式训练任务页面中单击新建任务,进入新建任务页面。
-
-
在新建任务页面,配置以下关键参数,其他参数取默认配置即可。更多详细内容,请参见提交任务(通过控制台)。
参数
描述
资源组
本方案选择已创建的灵骏智算资源的资源配额。
任务名称
自定义任务名称。本方案配置为:test_qwen_dlc。
节点镜像
选中镜像地址并在文本框中输入:
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/pytorch-training:1.12-ubuntu20.04-py3.10-cuda11.3-megatron-patch-llm。任务类型
选择PyTorch。
数据集配置
选择已创建的NAS类型数据集,挂载路径配置为
/mnt/workspace/。执行命令
配置以下命令,其中run_pretrain_megatron_qwen.sh脚本输入的启动参数与DSW单机预训练模型一致。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen sh run_pretrain_megatron_qwen.sh \ dlc \ ${WORK_DIR}/PAI-Megatron-Patch \ 7B \ 1 \ 8 \ 1e-5 \ 1e-6 \ 2048 \ 2048 \ 85 \ fp16 \ 1 \ 1 \ sel \ true \ false \ false \ false \ 100000 \ ${WORK_DIR}/qwen-datasets/wudao/wudao_qwenbpe_content_document \ ${WORK_DIR}/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \ 100000000 \ 10000 \ ${WORK_DIR}/output_megatron_qwen/任务资源配置
在Worker节点配置页签配置以下参数:
-
节点数量:2,如果需要多机训练,配置节点数量为需要的机器数即可。
-
CPU(核数):90
说明
CPU核数不能大于96。
-
内存(GB):1024
-
共享内存(GB):1024
-
GPU(卡数):8
-
-
单击提交,页面自动跳转到分布式训练任务页面。您可以单击任务名称,在任务详情页面查看任务执行状态。当状态变为已成功时,表明训练任务执行成功。
有监督微调模型
您可以在DSW单机环境中训练模型,也可以在DLC环境中提交多机多卡分布式任务,训练过程大约持续2个小时。任务执行成功后,模型文件将输出到/mnt/workspace/output_megatron_qwen/目录下。
-
在微调模型前,请前往步骤二:准备预训练数据章节,在使用PAI处理好的小规模样本数据页签中,按照代码下载JSON文件。
-
微调模型。
DSW单机微调模型
以Qwen-7B模型为例,在Terminal中运行的代码示例如下:
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen sh run_finetune_megatron_qwen_withGA.sh \ dsw \ ${WORK_DIR}/Pai-Megatron-Patch \ 7B \ 1 \ 96 \ 1e-5 \ 1e-6 \ 2048 \ 2048 \ 85 \ bf16 \ 1 \ 1 \ sel \ true \ false \ false \ false \ 1000 \ ${WORK_DIR}/qwen-datasets/alpaca_zh-qwen-train.json \ ${WORK_DIR}/qwen-datasets/alpaca_zh-qwen-valid.json \ ${WORK_DIR}/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \ 2000 \ 10 \ ${WORK_DIR}/output_megatron_qwen/其中运行run_finetune_megatron_qwen_withGA.sh需要传入的参数说明如下:
参数
描述
ENV=$1
运行环境:
-
dlc
-
dsw
MEGATRON_PATH=$2
设置开源Megatron的代码路径。
MODEL_SIZE=$3
模型结构参数量级:7B、14B或72B。
BATCH_SIZE=$4
每卡训练一次迭代样本数:1、2、4、8。
GLOBAL_BATCH_SIZE=$5
微调总迭代样本数:64、96、128。
LR=$6
学习率:1e-5、5e-5。
MIN_LR=$7
最小学习率:1e-6、5e-6。
SEQ_LEN=$8
序列长度。
PAD_LEN=$9
Padding序列长度。
EXTRA_VOCAB_SIZE=${10}
词表扩充大小:
-
Qwen-7B:85。
-
Qwen-14B:213。
-
Qwen-72B:213。
PR=${11}
训练精度:fp16、bf16。
TP=${12}
模型并行度。
PP=${13}
流水并行度。
AC=${14}
激活检查点模式:full或sel。
DO=${15}
是否使用Megatron版Zero-1降显存优化器:
-
true
-
false
FL=${16}
是否打开Flash Attention:
-
true
-
false
SP=${17}
是否使用序列并行:
-
true
-
false
TE=${18}
是否开启Transformer-engine加速技术,需H800显卡。
SAVE_INTERVAL=${19}
保存模型的步数。
DATASET_PATH=${20}
训练数据集路径。
VALID_DATASET_PATH=${21}
验证数据集路径。
PRETRAIN_CHECKPOINT_PATH=${22}
预训练模型路径。
TRAIN_ITERS=${23}
训练迭代轮次。
LR_WARMUP_ITERS=${24}
学习率增加值最大的步数。
OUTPUT_BASEPATH=${25}
训练输出模型文件的路径。
DLC分布式微调模型
在DSW单机环境调试完成后,您可以在DLC环境中配置多机多卡分布式任务。提交DLC训练任务时,执行命令配置如下,其他参数配置详情,请参见步骤2:预训练模型。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen sh run_finetune_megatron_qwen_withGA.sh \ dlc \ ${WORK_DIR}/Pai-Megatron-Patch \ 7B \ 1 \ 96 \ 1e-5 \ 1e-6 \ 2048 \ 2048 \ 85 \ bf16 \ 1 \ 1 \ sel \ true \ false \ false \ false \ 1000 \ ${WORK_DIR}/qwen-datasets/alpaca_zh-qwen-train.json \ ${WORK_DIR}/qwen-datasets/alpaca_zh-qwen-valid.json \ ${WORK_DIR}/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 \ 2000 \ 10 \ ${WORK_DIR}/output_megatron_qwen/其中运行run_finetune_megatron_qwen_withGA.sh需要传入的参数与DSW单机微调模型相同。
-
步骤四:离线推理模型
在模型训练完成后,您可以使用Megatron推理链路进行离线推理,以评估模型效果。具体操作步骤如下:
-
下载测试样本pred_input.jsonl,并上传到DSW的
/mnt/workspace目录下。具体操作,请参见上传下载数据文件。说明
推理的数据组织形式需要与微调时保持一致。
-
将训练前模型路径下的所有JSON文件和tokenizer.model文件拷贝到训练生成的模型路径(位于
{OUTPUT_BASEPATH }/checkpoint的下一级目录下,与latest_checkpointed_iteration.txt同级)。说明
命令中的路径需替换为您的实际路径。
cd /mnt/workspace/qwen-ckpts/qwen-7b-hf-to-megatron-tp1-pp1 cp *.json /mnt/workspace/output_megatron_qwen/checkpoint/dswXXX/ cp tokenizer.model /mnt/workspace/output_megatron_qwen/checkpoint/dswXXX/ -
在Terminal中执行以下命令完成模型离线推理,推理结果输出到
/mnt/workspace/qwen_pred.txt文件,您可以根据推理结果来评估模型效果。说明
执行命令前,您需要将run_text_generation_megatron_qwen.sh脚本中的参数CUDA_VISIBLE_DEVICES设置为0;参数GPUS_PER_NODE设置为1。
export WORK_DIR=/mnt/workspace cd ${WORK_DIR}/Pai-Megatron-Patch/examples/qwen bash run_text_generation_megatron_qwen.sh \ dsw \ ${WORK_DIR}/PAI-Megatron-Patch \ /mnt/workspace/output_megatron_qwen/checkpoint/dswXXX \ 7B \ 1 \ 1 \ 1024 \ 1024 \ 85 \ fp16 \ 10 \ 512 \ 512 \ ${WORK_DIR}/pred_input.jsonl \ ${WORK_DIR}/qwen_pred.txt \ 0 \ 1.0 \ 1.2其中运行run_text_generation_megatron_qwen.sh脚本输入的启动参数说明如下:
参数
描述
ENV=$1
运行环境:
-
dlc
-
dsw
MEGATRON_PATCH_PATH=$2
设置Megatron Patch的代码路径。
CHECKPOINT_PATH=$3
模型训练阶段的模型保存路径。
重要
该路径需要替换为您自己的模型路径。
MODEL_SIZE=$4
模型结构参数量级:7B、14B或72B。
TP=$5
模型并行度。
重要
-
该参数配置为1,可以使用单卡进行推理。
-
该参数值大于1,则需要使用相应的卡数进行推理。
BS=$6
每卡推理一次迭代样本数:1、4、8。
SEQ_LEN=$7
序列长度:256、512、1024。
PAD_LEN=$8
PAD长度:需要将文本拼接的长度。
EXTRA_VOCAB_SIZE=${9}
模型转换时增加的token数量:
-
Qwen-7B:85。
-
Qwen-14B:213。
-
Qwen-72B:213。
PR=${10}
推理采用的精度:fp16、bf16。
TOP_K=${11}
采样策略中选择排在前面的候选词数量(0-n): 0、5、10、20。
INPUT_SEQ_LEN=${12}
输入序列长度:512。
OUTPUT_SEQ_LEN=${13}
输出序列长度:256。
INPUT_FILE=${14}
需要推理的文本文件:pred_input.jsonl,每行为一个样本。
OUTPUT_FILE=${15}
推理输出的文件:qwen_pred.txt。
TOP_P=${16}
采样策略中选择排在前面的候选词百分比(0,1):0、0.85、0.95。
说明
TOP_K和TOP_P必须有一个为0。
TEMPERATURE=${17}
采样策略中温度惩罚:1-n。
REPETITION_PENALTY=${18}
避免生成时产生大量重复,可以设置为(1-2)。默认为1.2。
-
步骤五:模型格式转换
离线推理完成后,如果模型效果符合您的预期,您可以将训练获得的Megatron格式的模型转换为Huggingface格式,具体操作步骤如下。后续您可以使用转换后的Huggingface格式的模型进行服务在线部署。
-
在Terminal中执行以下命令,将训练生成的Megatron格式的模型转换为Huggingface格式的模型。
export WORK_DIR=/mnt/workspace cd /mnt/workspace/Pai-Megatron-Patch/toolkits/model_checkpoints_convertor/qwen sh model_convertor.sh \ ../../../Megatron-LM-main \ ${WORK_DIR}/output_megatron_qwen/checkpoint/${路径}/iter_******* \ /mnt/workspace/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1/ \ 1 \ 1 \ qwen-7b \ 0 \ true其中运行model_convertor.sh脚本需要传入的参数说明如下:
参数
描述
MEGATRON_PATH=$1
设置开源Megatron的代码路径。
SOURCE_CKPT_PATH=$2
配置为训练获得的Megatron格式的模型路径,具体到
iter_*。例如:${WORK_DIR}/output_megatron_qwen/checkpoint/dsw-pretrain-megatron-qwen-7B-lr-1e-5-bs-1-seqlen-2048-pr-bf16-tp-1-pp-1-ac-sel-do-true-sp-false-tt--wt-/iter_*******。重要
-
请替换为您自己的模型路径。
-
如果使用预训练模型进行转换,需要删除模型路径下所有的distrib_optim.pt文件。
TARGET_CKPT_PATH=$3
转换为Huggingface格式的模型后保存的路径。
TP=$4
张量切片数量,与训练保持一致。
PP=$5
流水切片数量,与训练保持一致。
MN=$6
模型名称:qwen-7b、qwen-14b或qwen-72b。
EXTRA_VOCAB_SIZE=$7
额外词表大小。
mg2hf=$8
是否为Megatron格式转Huggingface格式。
-
-
将开源Huggingface模型文件夹路径
/mnt/workspace/qwen-ckpts/qwen-7b-hf下的.json、.py和.tiktoken类型的文件,拷贝至/mnt/workspace/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1目录下,以保证模型可以正常使用。重要
请注意,无需复制pytorch_model.bin.index.json文件。
离线推理Huggingface格式的模型
您可以使用HuggingFace&DeepSpeed格式的推理链路,对转换后的Huggingface格式的模型文件进行离线推理。以Qwen-7B模型为例,在Terminal中的任意目录下创建infer.py文件,文件内容如下。执行infer.py文件进行模型离线推理,根据推理结果来评估模型效果。
#!/usr/bin/env python
#encoding=utf-8
from transformers import AutoTokenizer, LlamaTokenizer
from transformers import LlamaForCausalLM
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = '/mnt/workspace/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1'
print(checkpoint)
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(checkpoint,device_map="auto", trust_remote_code=True)
prompts= '写一个快速排序算法'
p = f"Human:{prompts}"
print(p)
inputs = tokenizer.encode(p, return_tensors="pt").to(model.device)
outputs = model.generate(inputs,max_new_tokens=512)
print(tokenizer.decode(outputs[0]))其中checkpoint替换为转换成Huggingface格式模型文件所在的路径。本案例配置为/mnt/workspace/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1。
代码执行成功后,返回如下结果。
Setting ds_accelerator to cuda (auto detect)
/mnt/workspace/latest/qianwen/qwen-7b-hf
The model is automatically converting to bf16 for faster inference. If you want to disable the automatic precision, please manually add bf16/fp16/fp32=True to "AutoModelForCausalLM.from_pretrained".
Try importing flash-attention for faster inference...
Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:07<00:00, 3.78s/it]
Human:写一个快速排序算法
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:151643 for open-end generation.
Human:写一个快速排序算法的伪代码吧!
Assistant:
好的,以下是快速排序算法的伪代码实现示例,供您参考:
1. 选择一个基准元素 pivot,通常选择第一个元素或者最后一个元素。将小于等于基准元素的元素放在其左边,大于基准元素的元素放在其右边。这个过程称为分区 partition。 2. 对左右两个分区递归地进行快速排序。 3. 当左右两个分区的元素个数为0或1时,排序完成。您可以参考以下链接了解更多关于推理的详细内容:
-
Huggingface通用文本生成教学
-
Belle文本生成示例
-
Qwen文本生成示例
步骤六:部署及调用模型服务
完成离线推理并评估完成模型效果后,您可以将转换为Huggingface格式的模型部署为在线服务,并在实际的生产环境中调用,从而进行推理实践。具体操作步骤如下:
部署模型服务
-
进入PAI-EAS 模型在线服务页面。
-
登录PAI控制台。
-
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
-
在工作空间页面的左侧导航栏选择模型部署>模型在线服务(EAS),进入PAI-EAS 模型在线服务页面。


-
-
在华北6(乌兰察布)地域单击部署服务,并在部署服务页面配置以下关键参数,其他参数取默认配置即可。
参数
描述
服务名称
自定义模型服务名称,同地域内唯一。本方案配置为:test_qwen。
部署方式
本方案选择:镜像部署AI-Web应用。
镜像选择
选择镜像地址,在本文框中配置镜像地址
pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/llm-inference:vllm-0.2.1-v4,并选中阅读并同意PAI服务专用协议。模型配置
单击填写模型配置,配置模型地址。
-
选择NAS挂载,并配置以下参数:
-
NAS挂载点:选择创建数据集使用的NAS文件系统和挂载点。
-
NAS源路径:配置为存放在NAS中的转换后的Huggingface格式模型的路径。本方案配置为
/qwen-ckpts/qwen-7b-mg-to-hf-tp1-pp1。 -
挂载路径:指定挂载后的路径,本方案配置为:
/qwen-7b。
-
运行命令
-
运行命令配置为
nohup python -m fastchat.serve.controller > tmp1.log 2>&1 & python -m fastchat.serve.gradio_web_server_pai --model-list-mode reload > tmp2.log 2>&1 & python -m fastchat.serve.vllm_worker --model-path /qwen-7b --tensor-parallel-size 1 --trust-remote-code。其中:
-
–model-path:需要与模型配置中的挂载路径一致。
-
–tensor-parallel-size:模型张量切分的数量,需要根据GPU的卡数进行调整。7b模型在单卡时可以配置为1;72b模型需要配置为2。
-
-
端口号配置为:7860。
资源组种类
本方案选择灵骏智算资源。
Quota选择
选择已创建的灵骏智算资源的资源配额。
实例数
根据模型和选择的资源情况进行配置。以7b模型为例,实例数配置为1,每个实例使用的资源配置为:
-
CPU:16。
-
内存(MB):64000。
-
GPU:1。
VPC
配置好NAS挂载点后,系统将自动匹配与预设的NAS文件系统一致的VPC、交换机和安全组。
交换机
安全组名称
-
-
单击部署。
当服务状态变为运行中时,表明服务部署成功。
调用服务
服务部署成功后,您可以调用服务进行推理实践,具体操作步骤如下:
-
进入PAI-EAS 模型在线服务页面。
-
登录PAI控制台。
-
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
-
在工作空间页面的左侧导航栏选择模型部署>模型在线服务(EAS),进入PAI-EAS 模型在线服务页面。
-
-
在服务列表中,单击目标服务的服务方式列下的查看Web应用。
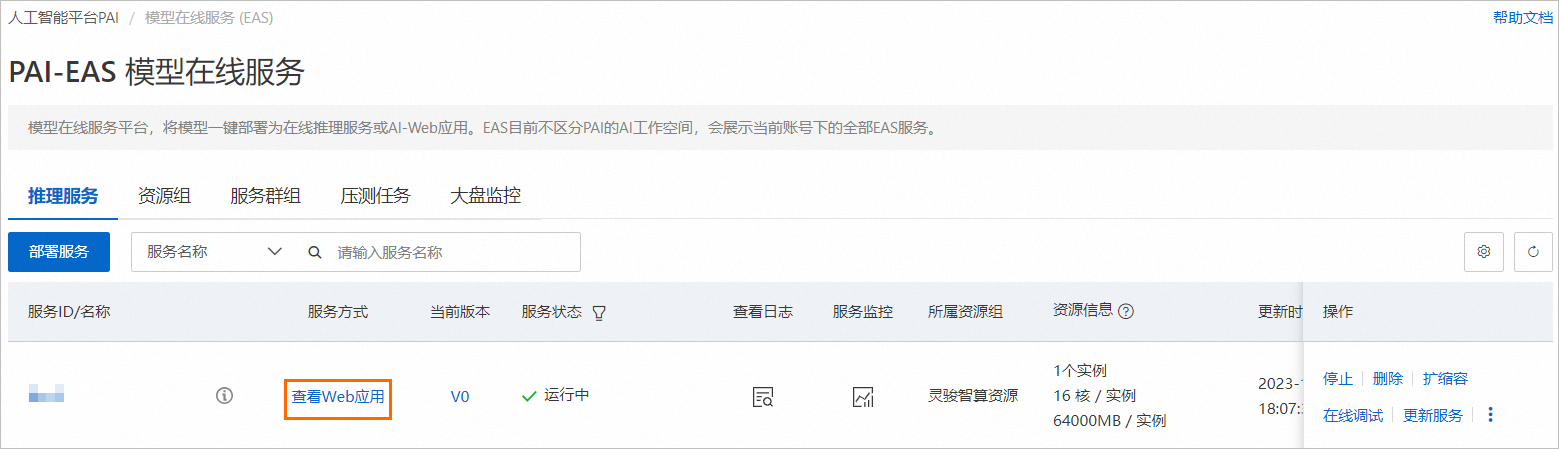
-
在WebUI页面中,进行推理模型推理。
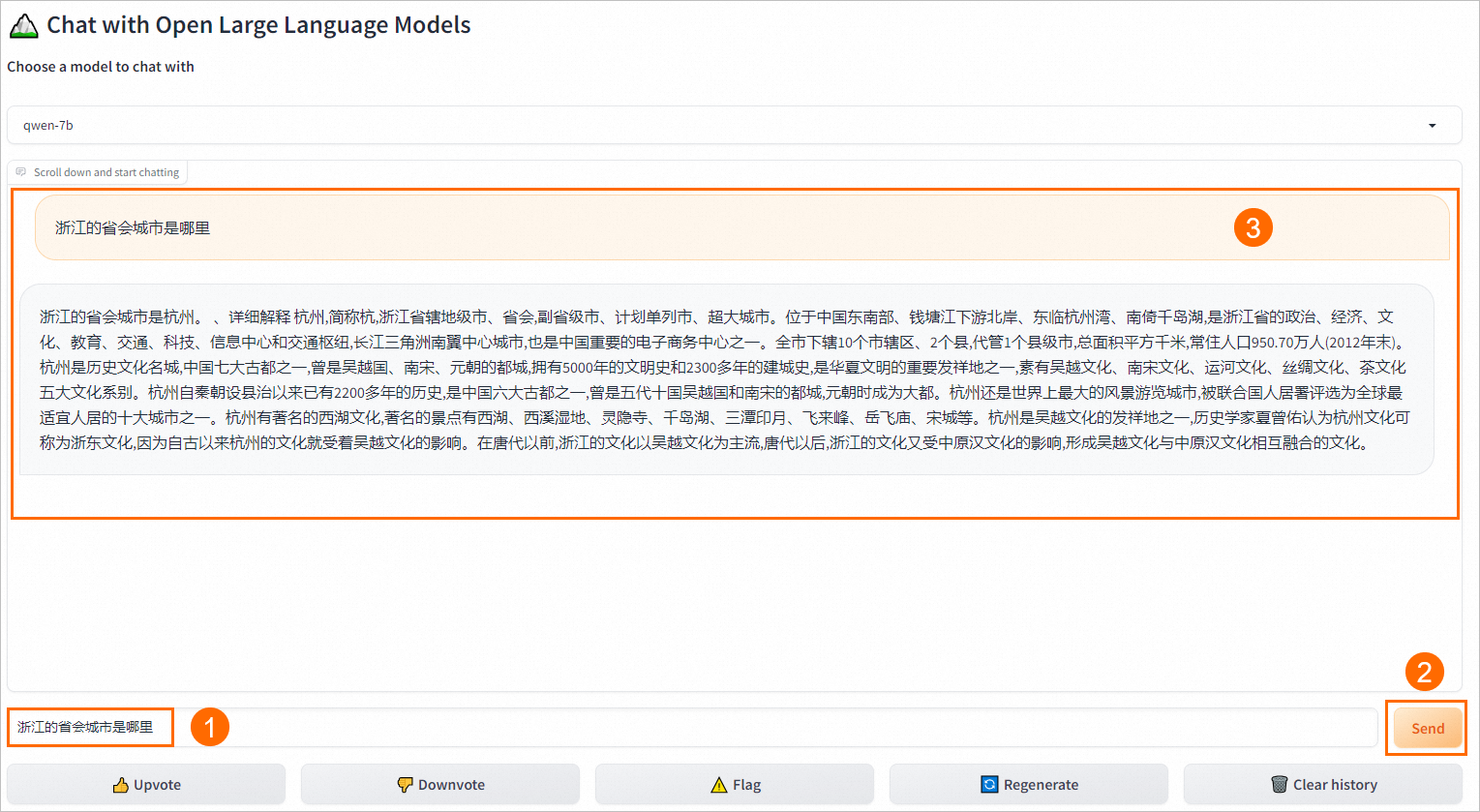
、
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/165266.html