
TensorFlow Serving是一个适用于深度学习模型的推理服务引擎,支持将Tensorflow标准的SavedModel格式的模型部署为在线服务,并支持模型热更新与模型版本管理等功能。本文为您介绍如何使用镜像部署的方式部署Tensorflow Serving模型服务。
部署服务
部署单模型服务
-
在OSS Bucket中创建模型存储目录。
TensorFlow Serving模型的存储目录要求以如下目录结构存储模型:
-
模型版本目录:每个模型至少包含一个模型版本目录,且必须以数字命名,作为模型版本号,数字越大版本号越新。
-
模型文件:模型版本目录下存放导出的SavedModel格式的模型文件,服务会自动加载最大模型版本号目录下的模型文件。
假设模型存储目录在
oss://examplebucket/models/tf_serving/路径下,模型存储目录的格式如下:tf_serving └── mnist └──1 ├── saved_model.pb └── variables ├── variables.data-00000-of-00001 └── variables.index -
-
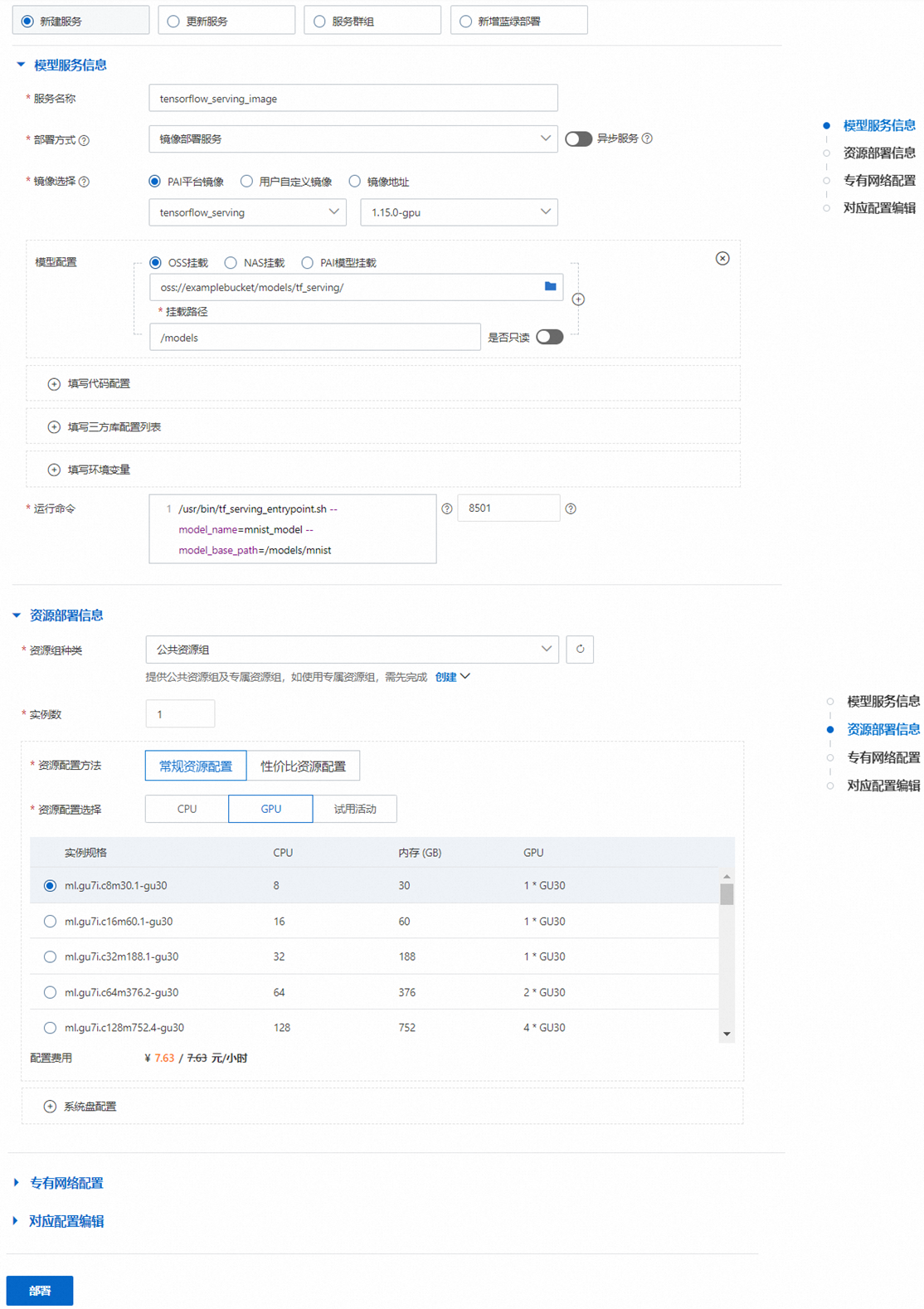
在EAS模型在线服务页面部署TensorFlow Serving服务。其中关键参数配置如下,更多详细内容,请参见服务部署:控制台。

参数
描述
部署方式
选择镜像部署服务。
镜像选择
在PAI平台镜像列表中选择tensorflow_serving和对应的镜像版本。
说明
如果服务需要使用GPU,则镜像版本必须选择x.xx.x-gpu。
填写模型配置
单击填写模型配置,进行模型配置。
-
模型配置选择OSS挂载,将OSS路径配置为步骤1中模型存储目录所在的OSS Bucket目录,例如:
oss://examplebucket/models/tf_serving/。 -
挂载路径:配置为
/models。
运行命令
tensorflow_serving的启动参数,其中:
-
–model_name:用于指定模型名称。如果不配置,默认名称为model。
-
–model_base_path:用于指定模型存储目录在实例中的路径。如果不配置,默认路径为
/models/model。
例如:
/usr/bin/tf_serving_entrypoint.sh --model_name=mnist_model --model_base_path=/models/mnist。支持配置以下端口号:
-
8501:支持HTTP请求,在8501端口启动HTTP或REST服务。
-
8500:支持gRPC请求,在8500端口启动gRPC服务,同时您需要在对应配置编辑中添加以下配置。
"metadata": { "enable_http2": true }, "networking": { "path": "/" }
服务部署配置示例参数如下:
{ "metadata": { "name": "tensorflow_server_image", "instance": 1, }, "cloud": { "computing": { "instance_type": "ml.gu7i.c8m30.1-gu30", "instances": null } }, "storage": [ { "oss": { "path": "oss://examplebucket/models/tf_serving/", "readOnly": false }, "properties": { "resource_type": "model" }, "mount_path": "/models" } ], "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/tensorflow_serving:1.15.0", "script": "/usr/bin/tf_serving_entrypoint.sh --model_name=mnist_model --model_base_path=/models/mnist", "port": 8501 } ] } -
部署多模型服务
Tensorflow Serving支持同时部署多个模型,具体操作步骤如下。
-
在OSS Bucket中创建模型存储目录。
假设模型存储目录在
oss://examplebucket/models/tf_serving/路径下,多个模型存储目录的格式如下:tf_serving ├── model_config.pbtxt │ ├── model1 │ ├── 1 │ │ ├── saved_model.pb │ │ └── variables │ │ ├── variables.data-00000-of-00001 │ │ └── variables.index │ ├── 2 │ │ └── ... │ └── 3 │ └── ... │ ├── model2 │ ├── 1 │ │ └── ... │ └── 2 │ └── ... │ └── model3 ├── 1 │ └── ... ├── 2 │ └── ... └── 3 └── ...其中模型配置文件model_config.pbtxt内容示例如下。
model_config_list { config { name: 'model1' base_path: '/models/model1/' model_platform: 'tensorflow' model_version_policy{ specific { versions: 1 versions: 2 } } version_labels { key: 'stable' value: 1 } version_labels { key: 'canary' value: 2 } } config { name: 'model2' base_path: '/models/model2/' model_platform: 'tensorflow' model_version_policy{ all: {} } } config { name: 'model3' base_path: '/models/model3/' model_platform: 'tensorflow' model_version_policy{ latest { num_versions: 2 } } } }其中关键配置说明如下:
参数
是否必选
描述
name
否
自定义配置模型名称。建议配置该参数,如果不配置模型名称,则model_name为空,后续无法调用该模型服务。
base_path
是
配置模型存储目录在实例中的路径,后续部署服务时用于读取模型文件。例如:挂载目录为
/models,要加载的模型目录为/models/model1,则该参数配置为/models/model1。model_version_policy
否
表示模型版本加载策略。
-
不配置该参数:表示默认加载模型最新版本。
-
all{}:表示加载该模型所有版本。示例中model2模型加载所有版本。
-
latest{num_versions}:示例中model3配置为
num_versions: 2,表示加载最新的2个版本,即版本2和3。 -
specific{}:表示加载指定版本。示例中model1模型加载版本1和2。
version_labels
否
为模型版本配置自定义标签。
说明
标签默认只能分配给已成功加载并启动为服务的模型版本,若想要预先为尚未加载的模型版本分配标签,需要在运行命令中设置启动参数
--allow_version_labels_for_unavailable_models=true。 -
-
部署服务。
EAS部署多模型服务的方式与单模型部署基本相同,只需在运行命令中配置以下参数,其他参数配置及部署方法,请参见单模型服务部署。
运行命令配置示例为:
/usr/bin/tf_serving_entrypoint.sh --model_config_file=/models/model_config.pbtxt --model_config_file_poll_wait_seconds=30 --allow_version_labels_for_unavailable_models=true。参数说明如下:
参数
是否必选
描述
–model_config_file
是
指定模型配置文件。
–model_config_file_poll_wait_seconds
否
如果您希望在服务启动后修改模型配置文件的内容,需要配置轮询模型文件的周期,单位为秒。
示例中配置为30表示每隔30秒读取一次模型配置文件内容。
–allow_version_labels_for_unavailable_models
否
默认为false,如果您想预先为尚未加载的模型版本分配标签,需要将该参数配置为true。
-
更新模型配置文件。
-
(可选)首次更新模型配置文件时,您需要单击服务操作列下的更新服务,在运行命令中增加
--model_config_file_poll_wait_seconds来指定服务定期轮询配置文件。说明
如果您在部署服务时已经在运行命令中配置了
--model_config_file_poll_wait_seconds参数,则可以忽略该步骤。 -
修改模型配置文件,服务会按照model_config_file_poll_wait_seconds启动参数设置的时间定期读取模型配置文件的内容,并根据新配置内容更新服务。
说明
当模型服务读取新的模型配置文件时,只会执行新配置文件中的内容。例如:旧配置文件中包含模型A,而新配置文件将模型A删除并增加了模型B配置,那么服务会卸载模型A并加载模型B。
-
发送服务请求
根据服务部署时运行命令中配置的端口号,分别支持HTTP和gRPC两种请求方式。
-
HTTP请求
端口号配置为8501,服务支持HTTP请求,发送服务请求支持以下两种方式:
通过控制台发送服务请求
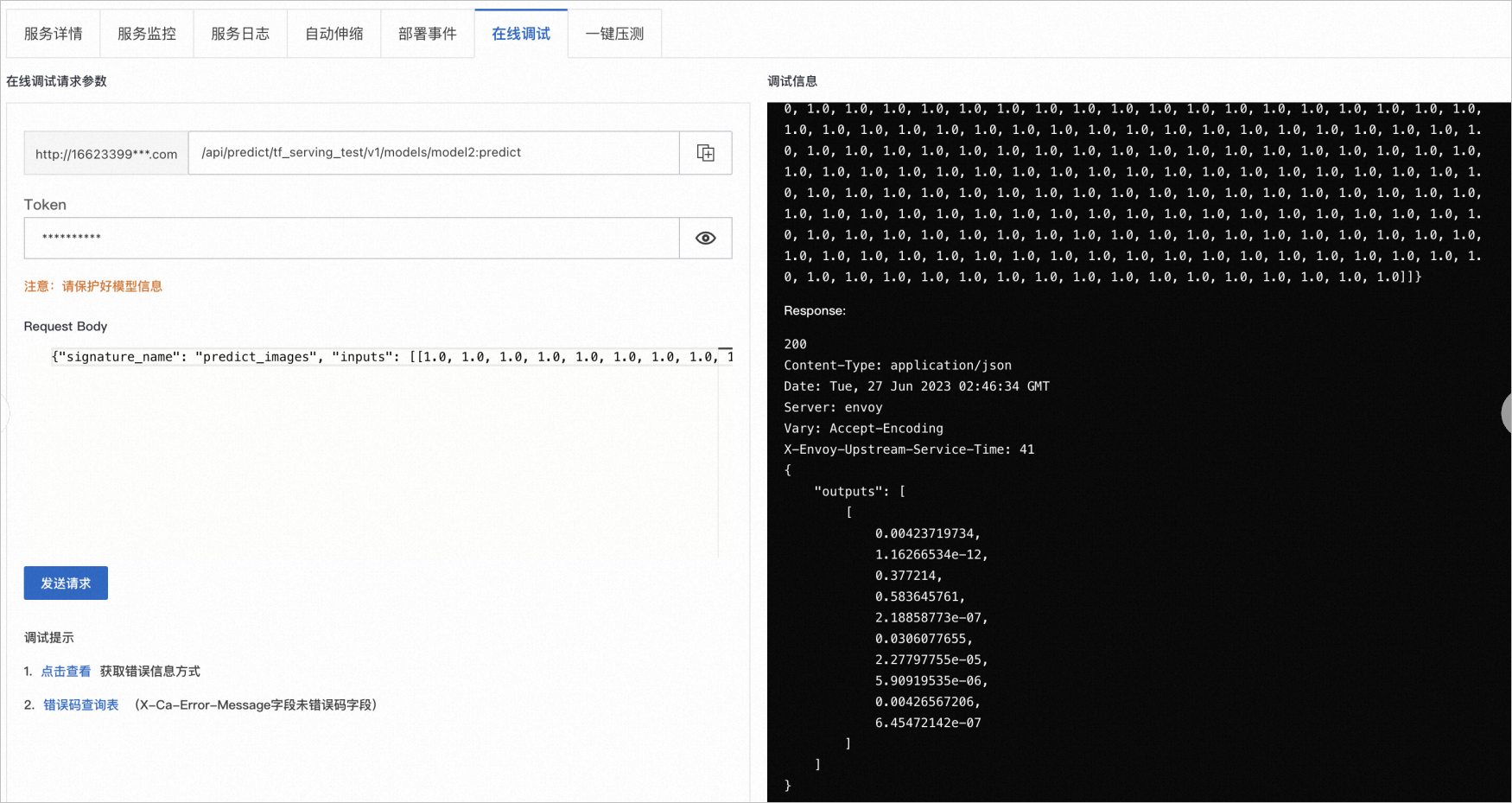
服务部署完成后,单击服务操作列下的在线调试,在该页面发送服务请求。其中关键参数配置如下:
参数
描述
在线调试请求参数
在服务访问地址后增加
/v1/models/:predict,其中:-
:单模型发送HTTP请求时,配置为运行命令中配置的模型名称;多模型发送HTTP请求时,配置为模型配置文件中配置的模型名称。
-
:可选配置,未指定版本号则默认加载版本号最大的模型。您也可以指定模型版本号,格式为:
/v1/models//versions/:predict。
Request Body
配置服务请求数据,例如:
{"signature_name": "predict_images", "inputs": [[1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]]}发送请求后,输出如下类似结果。
通过Python代码发送服务请求
Python代码示例如下:
from urllib import request import json # 服务访问地址,未指定版本号则默认加载版本号最大的模型;您也可以参照下方url参数说明指定模型版本号。 url = '/v1/models/:predict' # 创建HTTP请求。 req = request.Request(url, method="POST") # test-token替换为服务Token。 req.add_header('authorization', '') data = { 'signature_name': 'predict_images', 'inputs': [[1.0] * 784] } # 请求服务。 response = request.urlopen(req, data=json.dumps(data).encode('utf-8')).read() # 查看返回结果。 response = json.loads(response) print(response)其中关键参数配置如下:
参数
描述
url
格式为:
/v1/models/:predict其中:
-
:需要替换为您部署的服务访问地址。您可以在PAI-EAS模型在线服务页面,单击待调用服务服务方式列下的调用信息,在公网地址调用页签查看服务访问地址。
-
:配置方式如下。
-
单模型发送HTTP请求
配置为运行命令中配置的模型名称。
-
多模型发送HTTP请求
配置为模型配置文件中配置的模型名称。
-
-
:可选配置,未指定版本号则默认加载版本号最大的模型。您也可以指定模型版本号,格式为:
/v1/models//versions/:predict。
header
将替换为服务Token。您可以在公网地址调用页签查看Token。
-
-
gRPC请求
端口号配置为8500,并添加gRPC相关配置后,服务支持发送gRPC请求。Python代码示例如下:
import grpc from tensorflow_serving.apis import predict_pb2 from tensorflow_serving.apis import prediction_service_pb2_grpc from tensorflow.core.framework import tensor_shape_pb2 # 服务访问地址。 host = "tf-serving-multi-grpc-test.166233998075****.cn-hangzhou.pai-eas.aliyuncs.com:80" name = "" signature_name = "predict_images" version = # 创建gRPC请求。 shape = tensor_shape_pb2.TensorShapeProto() dim1 = tensor_shape_pb2.TensorShapeProto.Dim(size=1) dim2 = tensor_shape_pb2.TensorShapeProto.Dim(size=784) shape.dim.extend([dim1, dim2]) request = predict_pb2.PredictRequest() request.model_spec.name = name request.model_spec.signature_name = signature_name request.model_spec.version.value = version request.inputs["images"].tensor_shape.CopyFrom(shape) request.inputs["images"].float_val.extend([1.0] * 784) request.inputs["images"].dtype = 1 # 请求服务 channel = grpc.insecure_channel(host) stub = prediction_service_pb2_grpc.PredictionServiceStub(channel) metadata = (("authorization", ""),) response, _ = stub.Predict.with_call(request, metadata=metadata) print(response)其中关键参数配置如下:
参数
描述
host
需要配置为服务访问地址,服务访问地址需要省略
http://并在末尾添加:80。您可以在PAI-EAS模型在线服务页面,单击待调用服务服务方式列下的调用信息,在公网地址调用页签查看服务访问地址。name
-
单模型发送gRPC请求
配置为运行命令中配置的模型名称。
-
多模型发送gRPC请求
配置为模型配置文件中配置的模型名称。
version
配置为模型版本号。每次只能对单个模型版本发送请求。
metadata
配置为服务Token。您可以在公网地址调用页签查看Token。
-
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/164224.html