
本文介绍资源函数的语法规则,包括参数解释、函数示例等。
函数列表
重要 使用如下资源函数时,必须配置高级预览才能拉取到目标数据。如何配置高级预览,请参见高级预览。
| 函数 | 说明 |
|---|---|
| res_local | 从当前数据加工任务中拉取高级参数配置信息。
支持和其他函数组合使用。相关示例,请参见使用RDS内网地址访问RDS MySQL数据库。 |
| res_rds_mysql | 从RDS MySQL数据库中拉取数据库表内容或SQL执行结果,支持定期更新数据。
支持和其他函数组合使用。相关示例,请参见使用RDS内网地址访问RDS MySQL数据库。 |
| res_log_logstore_pull | 从另一个Logstore中拉取数据,支持持续拉取数据。
支持和其他函数组合使用。相关示例,请参见从其他Logstore获取数据进行数据富化。 |
| res_oss_file | 从OSS中获取特定Bucket下的文件内容,支持定期更新数据。
支持和其他函数组合使用。相关示例,请参见从OSS获取CSV文件进行数据富化。 |
res_local
使用res_local函数从当前数据加工任务中拉取高级参数配置信息。
-
函数格式
res_local(param, default=None, type="auto") -
参数说明
名称 类型 是否必填 说明 param String 是 对应高级参数配置中的Key。 default String 否 当param参数的值不存在时,返回该参数的值,默认值为None。 type String 否 数据输出时的数据格式。 - auto(默认值):将原始值转化为JSON格式。如果转换失败则返回原始值。
- JSON:将原始值转化为JSON格式。如果转换失败则返回default参数的值。
- raw:返回原始值。
-
返回结果
根据参数配置,返回JSON格式数据或者原始值。
- 成功示例
原始值 返回值 返回值类型 1 1 整数 1.2 1.2 浮点 true True 布尔 false False 布尔 “123” 123 字符串 null None None [“v1”, “v2”, “v3”] [“v1”, “v2”, “v3”] 列表 [“v1”, 3, 4.0] [“v1”, 3, 4.0] 列表 {“v1”: 100, “v2”: “good”} {“v1”: 100, “v2”: “good”} 列表 {“v1”: {“v11”: 100, “v2”: 200}, “v3”: “good”} {“v1”: {“v11”: 100, “v2”: 200}, “v3”: “good”} 列表 - 失败示例 如下形式的原始值转换JSON失败,则返回字符串。
原始值 返回值 说明 (1,2,3) “(1,2,3)” 不支持元组,需使用列表形式。 True “True” 只支持true、false(小写)这两种布尔类型。 {1: 2, 3: 4} “{1: 2, 3: 4}” 字典的关键字只能是字符串。
- 成功示例
-
函数示例
从高级参数配置中获取信息并赋值给local。高级参数配置中的Key为endpoint,Value为hangzhou。
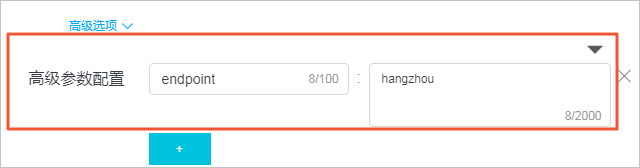

- 原始日志
content: 1 - 加工规则
e_set("local", res_local('endpoint')) - 加工结果
content: 1 local: hangzhou
- 原始日志
-
更多参考
支持和其他函数组合使用。相关示例,请参见使用RDS内网地址访问RDS MySQL数据库。
res_rds_mysql
使用res_rds_mysql函数从RDS MySQL数据库中拉取数据库表内容或SQL执行结果。日志服务加工功能提供如下3种拉取模式:重要
- 使用res_rds_mysql函数从RDS MySQL数据库中拉取数据时,需先在RDS MySQL中配置白名单为
0.0.0.0,使所有IP地址都可访问,但是这种方式会增加数据库的风险。如果您需要设置指定的日志服务IP地址,可以提工单进行配置。 - 日志服务支持使用RDS公网地址或内网地址访问RDS MySQL数据库。使用内网访问时,必须配置高级参数 。具体操作,请参见使用RDS内网地址访问RDS MySQL数据库。
- 普通拉取模式
在首次执行任务时,日志服务拉取全量数据,后续不再拉取数据。如果您数据库中的数据无更新,可选择普通拉取模式。
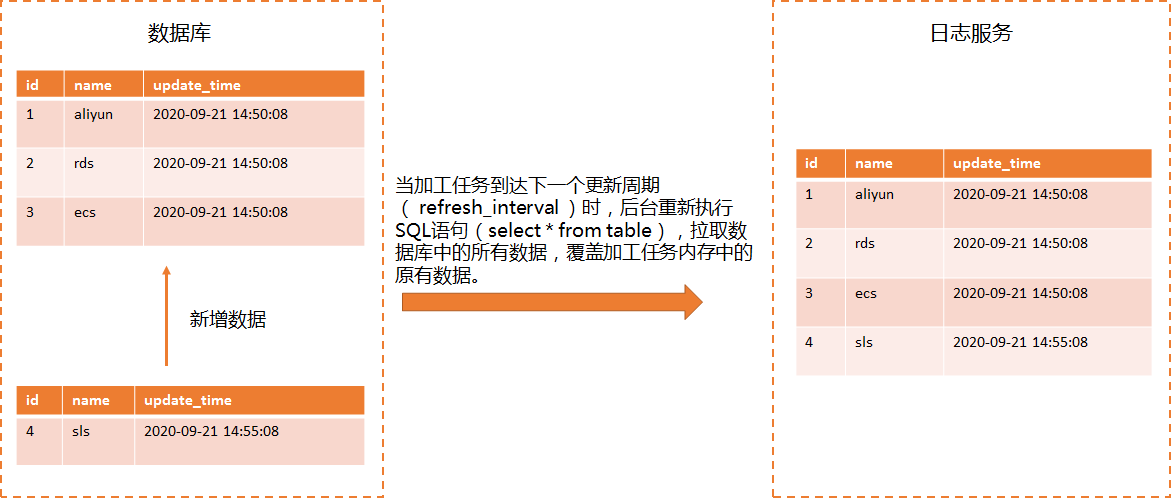
- 全量更新模式在执行任务过程中,日志服务定期全量拉取一次数据。虽然在全量更新模式下,日志服务会定期拉取数据,及时同步数据库中的数据,但每次都是全量拉取,非常耗时。如果您数据库中的数据量小(数据量=300s),可选择全量更新模式。
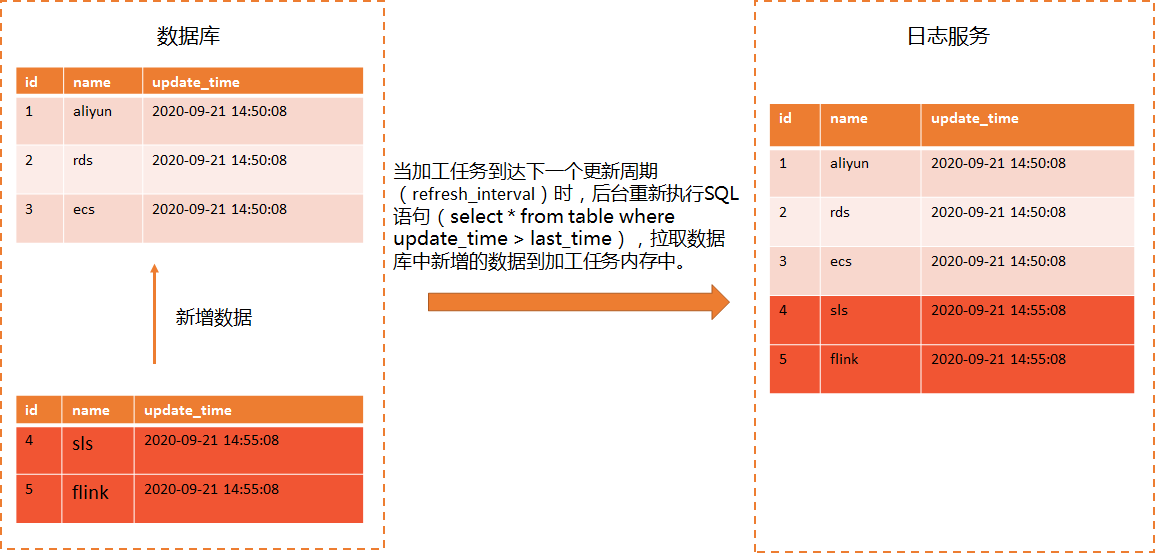
- 增量更新模式在执行任务过程中,日志服务根据数据库中的时间戳字段增量拉取数据,只拉取新增的数据。在增量更新模式下,日志服务每次只拉取新增的数据,效率高。您还可配置refresh_interval为1秒,秒级别同步数据库中的数据,即时性高。如果您数据库中的数据量大、更新频繁、数据实时性要求高,可选择增量更新模式。
-
函数格式
res_rds_mysql(address="待拉取的数据库地址", username="数据库的用户名", password="数据库的密码", database="数据库的名称", table=None, sql=None, fields=None, fetch_include_data=None, fetch_exclude_data=None, refresh_interval=0, base_retry_back_off=1, max_retry_back_off=60, primary_keys=None, use_ssl=false, update_time_key=None, deleted_flag_key=None)说明 日志服务还支持通过res_rds_mysql函数从AnalyticDB MySQL数据库、PolarDB MySQL数据库拉取数据,您只需将加工规则中的数据库地址、数据库用户名、数据库密码、数据库名称替换为对应数据库信息即可。
参数说明
名称 类型 是否必填 说明 address String 是 访问域名或IP地址。当端口号不是3306时,配置为 IP地址:port格式。更多信息,请参见查看内外网地址和端口。username String 是 连接数据库的用户名。 password String 是 连接数据库的密码。 database String 是 待连接的数据库名。 table String 是 待获取的数据库表名。如果您已配置sql参数,则无需配置该参数。 sql String 是 通过以Select开头的SQL语句查询数据。如果您已配置table参数,则无需配置该参数。 fields String List 否 字符串列表或者字符串别名列表。如果不填,则默认使用sql或table参数返回的所有列。例如需要将[“user_id”, “province”, “city”, “name”, “age”]中的name改名为user_name,可以将fields参数配置为[“user_id”, “province”, “city”, (“name”, “user_name”), (“nickname”, “nick_name”), “age”]。 说明 如果同时设置sql、table和fields参数,仅执行sql参数中的SQL语句,table和fields参数配置不生效。 fetch_include_data String 否 配置字段白名单,满足fetch_include_data时保留数据,否则丢弃。 - 不配置或配置为None时,表示关闭字段白名单功能。
- 配置为具体的字段和字段值时,表示保留该字段和字段值所在的日志。
fetch_exclude_data String 否 配置字段黑名单,满足fetch_exclude_data时丢弃数据,否则保留。 - 不配置或配置为None时,表示关闭字段黑名单功能。
- 配置为具体的字段和字段值时,表示丢弃该字段和字段值所在的日志。
说明 如果您同时设置了fetch_include_data和fetch_exclude_data参数,则优先执行fetch_include_data参数,再执行fetch_exclude_data参数。
refresh_interval 数字字符串或数字 否 从RDS MySQL拉取数据的时间间隔,单位:秒。默认值为0,表示仅全量拉取一次。 base_retry_back_off Number 否 拉取数据失败后重新拉取的时间间隔,默认值为1,单位:秒。 max_retry_back_off int 否 拉取数据失败后重试请求的最大时间间隔。默认值为60,单位:秒,建议使用默认值。 primary_keys String/List 否 主键,配置该字段后,将数据库表中的数据以Key:Value字典形式保存到内存中,其中Key为此处设置的primary_keys参数的值,Value为拉取到的数据库表的整行数据。说明 - 当数据库表中的数据量较大时,推荐使用该参数。
- 此处设置的primary_keys参数的值必须存在于从数据库表拉取的字段中。
use_ssl Boolean 否 是否使用SSL协议进行安全连接。默认值为false,表示不使用SSL协议。 说明 如果RDS MySQL开启SSL,则使用该参数使用SSL通道进行连接,但是不校验服务端的CA证书。目前不支持使用服务端生成的CA证书进行连接。 update_time_key String 否 用于增量获取数据。如果不配置此参数,则执行全量更新。例如update_time_key=”update_time”,其中update_time为MySQL数据库中数据更新的时间字段,该时间字段支持如下数据类型:Datetime、Timestamp、Int、Float、Decimal。需保证该时间字段的值随时间递增。说明 数据加工基于该时间字段做数据筛选,实现增量更新。请确保已在数据表中对该字段做索引,否则将进行全表扫描。如果不配置该时间字段的索引,将会报错无法进行增量更新。 deleted_flag_key String 否 在增量获取数据时,用于丢弃不需要加工的数据。例如update_time_key=”key”,key字段的值出现如下任意情况则被解析为该数据已被删除: - Boolean类型:true
- Datetime、Timestamp类型:非空
- Char、Varchar类型:1、true、t、yes、y
- Int类型:非零
说明
- deleted_flag_key参数必须和update_time_key参数一起使用。
- 如果配置了update_time_key参数,但未配置deleted_flag_key,则增量更新时不会丢弃已拉取的数据。
connector String 否 远程数据连接器。可选值为mysql、pgsql。默认值为mysql。 -
返回结果
返回多列表格,其字段由fields参数定义。
-
错误处理
如果拉取过程出错则会抛出异常,此时数据加工任务不会停止,而是按照base_retry_back_off参数对应的时间间隔进行重试。假设首次重试的时间间隔为1s,如果重试失败,下次重试的时间间隔为上一次的2倍,以此类推,直到达到max_retry_back_off参数值。如果依然失败,则后续将一直按照max_retry_back_off参数对应的时间间隔进行重试。如果重试成功,则重试间隔会恢复到初始值。
-
函数示例
- 全量更新
- 示例1:拉取test_db数据库中的test_table表数据,每隔300秒重新拉取一次表数据。
res_rds_mysql( address="rm-uf6wjk5****.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, ) - 示例2:不拉取test_table表中status字段值为delete的数据。
res_rds_mysql( address="rm-uf6wjk5****.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_exclude_data="'status':'delete'", ) - 示例3:仅拉取test_table表中status字段值为exit的数据。
res_rds_mysql( address="rm-uf6wjk5****.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_include_data="'status':'exit'", ) - 示例4:拉取test_table表中status字段值为exit的数据,并且该数据不包含name字段值为aliyun的数据。
res_rds_mysql( address="rm-uf6wjk5****.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", refresh_interval=300, fetch_include_data="'status':'exit'", fetch_exclude_data="'name':'aliyun'", ) - 示例5:使用pgsql连接器连接阿里云Hologres数据库,并拉取test_table表中的数据。
res_rds_mysql( address="hgpostcn-cn-****-cn-hangzhou.hologres.aliyuncs.com:80", username="test_username", password="****", database="aliyun", table="test_table", connector="pgsql", ) - 示例6:使用主键模式拉取数据。
使用主键模式时,将primary_keys参数的值作为Key拉取出来,拉取的表数据在内存中的存放形式为{“10001”:{“userid”:”10001″,”city_name”:”beijing”,”city_number”:”12345″}},效率高,适用于大数据量。不使用主键模式时,以遍历方式逐行匹配表数据,拉取的表数据在内存中的存放形式为[{“userid”:”10001″,”city_name”:”beijing”,”city_number”:”12345″}],效率较低,但占用内存小,适合于小数据量。
- 数据库表
userid city_name city_number 10001 beijing 12345 - 原始日志
#数据1 userid:10001 gdp:1000 #数据2 userid:10002 gdp:800 - 加工规则
e_table_map( res_rds_mysql( address="rm-uf6wjk5****.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_keys="userid", ), "userid", ["city_name", "city_number"], ) - 加工结果
#数据1 userid:10001 gdp:1000 city_name: beijing city_number:12345 #数据2 userid:10002 gdp:800
- 数据库表
- 示例1:拉取test_db数据库中的test_table表数据,每隔300秒重新拉取一次表数据。
- 增量更新
- 示例1:使用增量更新模式拉取数据说明 使用增量更新模式拉取数据,必须符合如下条件:
- 数据库表中必须有唯一主键并且有一个时间字段,例如示例中的item_id和update_time。
- 使用增量更新模式拉取数据时,必须在函数中设置primary_keys、refresh_interval和update_time_key这三个参数。
- 数据库表
item_id item_name price 1001 橘子 10 1002 苹果 12 1003 芒果 16 - 原始日志
#数据1 item_id: 1001 total: 100 #数据2 item_id: 1002 total: 200 #数据3 item_id: 1003 total: 300 - 加工规则
e_table_map( res_rds_mysql( address="rm-uf6wjk5****.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_key="item_id", refresh_interval=1, update_time_key="update_time", ), "item_id", ["item_name", "price"], ) - 加工结果
# 数据1 item_id: 1001 total: 100 item_name: 橘子 price:10 # 数据2 item_id: 1002 total: 200 item_name: 苹果 price:12 # 数据3 item_id: 1003 total: 300 item_name: 芒果 price:16
- 示例2:在增量模式中,使用deleted_flag_key参数实现历史数据丢弃功能。
- 数据库表
item_id item_name price update_time Is_deleted 1001 橘子 10 1603856138 False 1002 苹果 12 1603856140 False 1003 芒果 16 1603856150 False - 原始日志
# 数据1 item_id: 1001 total: 100 # 数据2 item_id: 1002 total: 200 # 数据3 item_id: 1003 total: 300 - 加工规则
e_table_map( res_rds_mysql( address="rm-uf6wjk5****.mysql.rds.aliyuncs.com", username="test_username", password="****", database="test_db", table="test_table", primary_key="item_id", refresh_interval=1, update_time_key="update_time", deleted_flag_key="is_deleted", ), "item_id", ["item_name", "price"], ) - 加工结果
使用res_rds_mysq函数已拉取数据表中的3条数据到日志服务内存中,与源logstore中的数据进行富化匹配。此时您希望丢弃1001这条数据,不再加工该数据,则您可以在数据表1001这条数据中,将Is_deleted字段值更新为true。更新后,在下一次加工内存维表更新时,1001这条数据将在维表中消失。
# 数据2 item_id: 1002 total: 200 item_name: 苹果 price:12 # 数据3 item_id: 1003 total: 300 item_name: 芒果 price:1
- 数据库表
- 示例1:使用增量更新模式拉取数据说明 使用增量更新模式拉取数据,必须符合如下条件:
- 全量更新
-
更多参考
支持和其他函数组合使用。相关示例,请参见使用RDS内网地址访问RDS MySQL数据库。
res_log_logstore_pull
使用res_log_logstore_pull函数从另一个Logstore中拉取数据。
-
函数格式
res_log_logstore_pull(endpoint, ak_id, ak_secret, project, logstore, fields, from_time="begin", to_time=None, fetch_include_data=None, fetch_exclude_data=None, primary_keys=None, fetch_interval=2, delete_data=None, base_retry_back_off=1, max_retry_back_off=60, ttl=None, role_arn=None) -
参数说明
名称 类型 是否必填 说明 endpoint String 是 访问域名。更多信息,请参见服务入口。默认为HTTPS格式,也支持HTTP格式。特殊情况下,需使用非80、非443端口。 ak_id String 是 阿里云账号的AccessKey ID。为了数据安全,建议在高级参数配置中配置。关于如何配置高级参数,请参见创建数据加工任务。 ak_secret String 是 阿里云账号的AccessKey Secret。为了数据安全,建议在高级参数配置中配置。关于如何配置高级参数,请参见创建数据加工任务。 project String 是 待拉取数据的Project名称。 logstore String 是 待拉取数据的Logstore名称。 fields String List 是 字符串列表或者字符串别名列表。日志中不包含某个字段时,该字段的值为空。例如需要将[“user_id”, “province”, “city”, “name”, “age”]的name改名为user_name时,可以配置为[“user_id”, “province”, “city”, (“name”, “user_name”), (“nickname”, “nick_name”), “age”]。 from_time String 否 首次开始拉取日志的服务器时间,默认值为begin,表示会从第一条数据开始拉取。支持如下时间格式: - Unix时间戳。
- 时间字符串。
- 特定字符串,例如begin、end。
- 表达式:dt_类函数返回的时间。例如dt_totimestamp(dt_truncate(dt_today(tz=”Asia/Shanghai”), day=op_neg(-1))),表示昨天拉取日志的开始时间,如果当前时间是2019-5-5 10:10:10 8:00,则上述表达式表示时间2019-5-4 10:10:10 8:00。
to_time String 否 首次结束读取日志的服务器时间。默认值为None,表示持续到当前的最后一条日志。支持如下时间格式: - Unix时间戳。
- 时间字符串。
- 特定字符串。例如begin、end。
- 表达式:dt_类函数返回的时间。
不配置或者配置为None表示持续拉取最新的日志。
说明 如果填入的是一个未来时间,只会将该Logstore所有数据拉取完毕,并不会开启持续拉取任务。
fetch_include_data String 否 配置字段白名单,满足fetch_include_data时保留数据,否则丢弃。 - 不配置或配置为None时,表示关闭字段白名单功能。
- 配置为具体的字段和字段值时,表示保留该字段和字段值所在的日志。
fetch_exclude_data String 否 配置字段黑名单,满足fetch_exclude_data时丢弃数据,否则保留。 - 不配置或配置为None时,表示关闭字段黑名单功能。
- 配置为具体的字段和字段值时,表示丢弃该字段和字段值所在的日志。
说明 如果您同时设置了fetch_include_data和fetch_exclude_data参数,则优先执行fetch_include_data参数,再执行fetch_exclude_data参数。
primary_keys 字符串列表 否 维护表格时的主键字段列表。如果fields参数中对主键字段进行修改,这里应使用修改后的字段名,将修改后的字段作为主键字段。 说明 - primary_keys参数只支持单个字符串,且必须存在于fields参数配置的字段中。
- 待拉取数据的目标Logstore中只能有一个Shard。
fetch_interval Int 否 开启持续拉取任务时,每次拉取请求的时间间隔,默认值为2,单位:秒。该值必须大于或者等于1。 delete_data String 否 对满足条件且配置了 primary_keys的数据,在表格中进行删除操作。更多信息,请参见查询字符串语法。base_retry_back_off Number 否 拉取数据失败后重新拉取的时间间隔,默认值为1,单位:秒。 max_retry_back_off Int 否 拉取数据失败后,重试请求的最大时间间隔,默认值为60,单位:秒。建议使用默认值。 ttl Int 否 开启持续拉取任务时,拉取日志产生时间开始ttl时间内的日志,单位为秒。默认值为None,表示拉取全部时间的日志。 role_arn String 否 RAM角色的ARN,该角色必须拥有读Logstore数据的权限。在RAM控制台,您可以在该角色的基本信息中查看,例如 acs:ram::1379******44:role/role-a。 如何获取ARN,请参见查看RAM角色。 -
返回结果
返回多列表格。
-
错误处理
如果拉取过程出错则会抛出异常,此时数据加工任务不会停止,而是按照base_retry_back_off参数对应的时间间隔进行重试。假设首次重试的时间间隔为1秒,如果重试失败,下次重试的时间间隔为上一次的2倍,以此类推,直到达到max_retry_back_off参数值。如果依然失败,则后续将一直按照max_retry_back_off参数对应的时间间隔进行重试。如果重试成功,则重试间隔会恢复到初始值。
-
函数示例
- 拉取test_project下test_logstore中的数据,并且仅拉取日志中key1、key2两个字段对应的数据,指定时间范围为从日志开始写入到结束,仅拉取一次。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time="end", ) - 拉取test_project下test_logstore中的数据,并且仅拉取日志中key1、key2两个字段对应的数据,指定时间范围为从日志开始写入到结束,设置为持续拉取,时间间隔为30秒。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, ) - 设置黑名单,不拉取包含key1:value1的数据。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, fetch_exclude_data="key1:value1", ) - 设置白名单,仅拉取包含key1:value1的数据。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LT****Gw", "ab****uu", "test_project", "test_logstore", ["key1", "key2"], from_time="begin", to_time=None, fetch_interval=30, fetch_include_data="key1:value1", ) - 拉取test_project下test_logstore中的数据,并且仅拉取日志中key1、key2两个字段对应的数据,指定时间范围为日志产生时间开始的40000000秒。
res_log_logstore_pull( "cn-hangzhou.log.aliyuncs.com", "LTAI*****Cajvr", "qO0Tp*****jJ9", "test_project", "test_logstore", fields=["key1","key2"], ttl="40000000" ) - 拉取project-test1下test-logstore中的数据,并且仅拉取日志中key1、key2两个字段对应的数据,使用SLR服务角色授权,指定时间范围为从日志开始写入到结束,仅拉取一次。
res_log_logstore_pull( "pub-cn-hangzhou-staging-intranet.log.aliyuncs.com", "", "", "project-test1", "test-logstore", ["key1", "key2"], from_time="2022-7-27 10:10:10 8:00", to_time="2022-7-27 14:30:10 8:00", role_arn="acs:ram::***:role/aliyunserviceroleforslsaudit", ) - 拉取project-test1下test-logstore中的数据,并且仅拉取日志中key1、key2两个字段对应的数据,使用默认角色授权,指定时间范围为从日志开始写入到结束,仅拉取一次。
res_log_logstore_pull( "cn-chengdu.log.aliyuncs.com", "", "", "project-test1", "test-logstore", ["key1", "key2"], from_time="2022-7-21 10:10:10 8:00", to_time="2022-7-21 10:30:10 8:00", role_arn="acs:ram::***:role/aliyunlogetlrole", )
- 拉取test_project下test_logstore中的数据,并且仅拉取日志中key1、key2两个字段对应的数据,指定时间范围为从日志开始写入到结束,仅拉取一次。
-
更多参考
支持和其他函数组合使用。相关示例,请参见从其他Logstore获取数据进行数据富化。
res_oss_file
使用res_oss_file函数从OSS Bucket中获取文件内容,并支持定期刷新。说明 建议日志服务Project和OSS Bucket处于同一地域,使用阿里云内网获取数据。阿里云内网网络稳定且速度快。
-
函数格式
res_oss_file(endpoint, ak_id, ak_key, bucket, file, format='text', change_detect_interval=0, base_retry_back_off=1, max_retry_back_off=60, encoding='utf8', error='ignore') -
参数说明
名称 类型 是否必填 说明 endpoint String 是 OSS服务入口。更多信息,请参见访问域名和数据中心。默认为HTTPS格式,也支持HTTP格式。特殊情况下,需使用非80/443端口。 ak_id String 是 阿里云账号的AccessKey ID。为了数据安全,建议在高级参数配置中配置。关于如何配置高级参数,请参见创建数据加工任务。 ak_key String 是 阿里云账号的AccessKey Secret。为了数据安全,建议在高级参数配置中配置。关于如何配置高级参数,请参见创建数据加工任务。 bucket String 是 目标OSS Bucket名称。 file String 是 目标OSS文件的路径。例如test/data.txt,不能以正斜线(/)开头。 format String 是 文件输出形式。 - Text:以文本形式输出。
- Binary:以字节流形式输出。
change_detect_interval String 否 从OSS拉取文件的时间间隔,单位:秒。拉取时会检查文件是否有更新,如果有更新则刷新。默认为0,表示不刷新,仅在程序启动时拉取一次数据。 base_retry_back_off Number 否 拉取失败后重新拉取文件的时间间隔,默认值为1,单位:秒。 max_retry_back_off int 否 拉取数据失败后,重试请求的最大时间间隔,默认值为60,单位:秒。建议使用默认值。 encoding String 否 编码方式。当format为text时,该参数默认为utf8。 error String 否 设置不同错误的处理方案,该字段仅在编码上报UnicodeError错误消息时有效。取值范围: - ignore表示忽略格式错误的数据,继续进行编码。
- xmlcharrefreplace表示将无法编码的字符替换为适当的XML字符。
更多信息,请参见Error Handlers。
decompress String 否 是否解压获取到的OSS文件。取值范围: - None(默认值):不解压。
- gzip:使用Gzip方式解压。
-
返回结果
返回字节流形式或文本形式的文件数据。
-
错误处理
如果拉取过程出错则会抛出异常,此时数据加工任务不会停止,而是按照base_retry_back_off参数对应的时间间隔进行重试。假设首次重试的时间间隔为1秒,如果重试失败,下次重试的时间间隔为上一次的2倍,以此类推,直到达到max_retry_back_off参数值。如果依然失败,则后续将一直按照max_retry_back_off参数对应的时间间隔进行重试。如果重试成功,则重试间隔会恢复到初始值。
-
函数示例
- 示例1:从OSS中拉取JSON格式的数据。
- JSON内容
{ "users": [ { "name": "user1", "login_historys": [ { "date": "2019-10-10 0:0:0", "login_ip": "203.0.113.10" }, { "date": "2019-10-10 1:0:0", "login_ip": "203.0.113.10" } ] }, { "name": "user2", "login_historys": [ { "date": "2019-10-11 0:0:0", "login_ip": "203.0.113.20" }, { "date": "2019-10-11 1:0:0", "login_ip": "203.0.113.30" }, { "date": "2019-10-11 1:1:0", "login_ip": "203.0.113.50" } ] } ] } - 原始日志
content: 123 - 加工规则
e_set( "json_parse", json_parse( res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="testjson.json", ) ), ) - 加工结果
content: 123 prjson_parse: '{ "users": [ { "name": "user1", "login_historys": [ { "date": "2019-10-10 0:0:0", "login_ip": "203.0.113.10" }, { "date": "2019-10-10 1:0:0", "login_ip": "203.0.113.10" } ] }, { "name": "user2", "login_historys": [ { "date": "2019-10-11 0:0:0", "login_ip": "203.0.113.20" }, { "date": "2019-10-11 1:0:0", "login_ip": "203.0.113.30" }, { "date": "2019-10-11 1:1:0", "login_ip": "203.0.113.50" } ] } ] }'
- JSON内容
- 示例2:从OSS中拉取文本内容。
- 文本内容
Test bytes - 原始日志
content: 123 - 加工规则
e_set( "test_txt", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="test.txt", ), ) - 加工结果
content: 123 test_txt: Test bytes
- 文本内容
- 示例3:从OSS拉取压缩文件并解压。
- OSS压缩文件内容
Test bytes update 123 - 原始日志
content:123 - 加工规则
e_set( "text", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", ak_id="LT****Gw", ak_key="ab****uu", bucket="log-etl-staging", file="test.txt.gz", format="binary", change_detect_interval=30, decompress="gzip", ), ) - 加工结果
content:123 text: Test bytes update 123
- OSS压缩文件内容
- 示例4:不使用访问密钥访问OSS公共读写文件。
- OSS压缩文件内容
Test bytes - 原始日志
content:123 - 加工规则
e_set( "test_txt", res_oss_file( endpoint="http://oss-cn-hangzhou.aliyuncs.com", bucket="log-etl-staging", file="test.txt", ), ) - 加工结果
content: 123 test_txt: Test bytes
- OSS压缩文件内容
- 示例1:从OSS中拉取JSON格式的数据。
-
更多参考
支持和其他函数组合使用。相关示例,请参见从OSS获取CSV文件进行数据富化。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/164076.html