
数据转tfrecord算法组件可以将标注生成的数据转换成tfrecord格式,从而用于图像类模型训练。本文介绍数据转tfrecord算法组件的配置方法及使用示例。
前提条件
已开通OSS并完成授权,详情请参见开通OSS服务和云产品依赖与授权:Designer。
使用限制
仅Designer提供该算法组件。
算法简介
在分布式集群数据加速方案中,通过把输入数据转为tfrecord,供给下游的图像分类、图像检测、OCR或图像自监督模型训练组件。
数据转tfrecord算法组件位于组件库音视觉算法文件夹下的视频预处理子文件夹,支持上亿规模的图像存储。
可视化配置组件
-
输入桩
输入桩
限制数据类型
建议上游组件
是否必选
标注数据
OSS
读OSS数据
是
-
组件参数
页签
参数
是否必选
描述
默认值
字段设置
转换配置文件路径
否
该参数暂时无用。
不指定该参数
输出tfrecord路径
是
输出tfrecord的路径。
无
输出tfrecord前缀
是
输出文件前缀。最终输出的两个数据文件的路径为:
-
输出tfrecord路径/输出tfrecord前缀_train_xxx.tfrecord -
输出tfrecord路径/输出tfrecord前缀_test_xxx.tfrecord
无
参数设置
转换数据用于何种模型训练
是
该组件转换后的数据可用于以下模型训练:
-
CLASSIFICATION:分类
-
DETECTION:目标检测
-
SEGMENTATION:语义分割
-
POLYGON_SEGMENTATION:多边形语义分割
-
INSTANCE_SEGMENTATION:实例分割
-
TEXT_END2END:端到端文字识别
-
TEXT_DETECTION:文字检测
-
TEXT_RECOGNITION:文字识别
无
类别列表文件路径
是
类别列表文件的OSS路径。
类别列表文件内容的每行格式为
类别名(即标注结果文件中的label标签名),或者类别名:映射类别名。文件类型为list或txt,例如oss://ev-dlc-sh.oss-cn-shanghai-internal.aliyuncs.com/data/iTAG/cls_class.list,其中cls_class.list表示文件列表文件。无
测试数据分割比例
否
测试数据分割比例。设置为0,则所有数据转换为训练数据,默认值0.1表示10%数据作为验证集。
0.1
图片最大边限制
否
如果设置了图片最大边限制,大图片将被Resize后存入tfrecord,从而节省存储、提高数据读取速度。
不指定该参数
测试图片最大边限制
否
如果设置了该参数,则测试图片中的大图片将被Resize后存入tfrecord,从而节省存储、提高数据读取速度。
不指定该参数
默认类别名称
否
在class_list中未找到的类别均会映射到该名称。
不指定该参数
错误类别名称
否
含有该类别的物体和Box将会被过滤,不参与训练。
不指定该参数
忽略类别名称
否
仅用于检测模型,含有该类别的Box会在训练中被忽略。
不指定该参数
转换类名称
否
转换类名,支持以下取值:
-
PAI标注格式:PAI标注平台产生的标注文件格式
-
亲测标注格式:亲测平台产生的标注文件格式
-
自监督标注格式:平台定义的图片自监督训练所需格式
PAI标注格式
分隔符
否
用于标记内容的分隔符。
不指定该参数
图片编码方式
否
tfrecord中图片的编码方式。常用图像编码方式如下所示:
-
jpg
-
png
-
bmp
jpg
字符映射替换文件
否
当转换数据用于何种模型训练取值为TEXT_END2END或TEXT_DETECTION时,您可以指定字符映射替换文件参数。例如
oss://ev-dlc-sh.oss-cn-shanghai-internal.aliyuncs.com/data/replace.csv。字符映射替换文件是CSV文件,包含original和replaced两列,original列的字符将被replaced列的内容替换。
不指定该参数
字符到id映射文件路径
否
当转换数据用于何种模型训练取值为TEXT_END2END或TEXT_DETECTION时,您可以指定字符到id映射文件路径参数。
字符到ID映射文件的每一行是一个字符,第k行的字符ID为k-1。
不指定该参数
执行调优
读取并发数
是
并发读取数。
10
写tfrecord并发数
是
并发写tfrecord的线程数。
1
每个tfrecord保存图片数
是
每个tfrecord保存的图片数目。
1000
单机或分布式(MaxCompute/DLC)
否
组件运行的引擎,您可以结合实际情况选择。系统支持以下计算引擎:
-
单机MaxCompute
当运行引擎为单机MaxCompute时,您还需要配置是否使用GPU,取值100表示1张GPU卡。如果不使用GPU,则需要将是否使用GPU配置为0。
-
分布式MaxCompute
当运行引擎为分布式MaxCompute时,您还需要配置以下参数:
-
worker个数:并发的worker数量。
-
CPU Core个数:每个Worker的CPU数目,取值100表示1核。
-
memory大小:每个Worker的内存大小,单位为MB。
-
-
单机DLC
当运行引擎为单机DLC时,您还需要配置以下参数:
-
是否使用GPU:取值100表示1张GPU卡。如果不使用GPU,则需要将是否使用GPU配置为0。
-
CPU机型选择:选择运行的CPU规格。
-
gpu机型选择:选择运行的GPU规格。
-
-
分布式DLC
当运行引擎为分布式DLC时,您还需要配置以下参数:
-
是否使用GPU:取值100表示1张GPU卡。
-
worker个数:并发的worker数量。
-
CPU机型选择:选择运行的CPU规格。
-
gpu机型选择:选择运行的GPU规格。
-
单机MaxCompute
-
-
输出桩
输出桩(从左到右)
数据类型
建议下游组件
训练数据
OSS路径。该路径是您在字段设置页签的输出tfrecord路径参数配置的OSS路径,训练数据和评估数据均输出在该路径下。
图像类训练组件(例如,(旧)图像分类训练、(旧)图像检测训练、图像分割训练、图像自监督训练或端到端的文字识别训练)。
评估数据
图像类训练组件(自监督训练组件除外,因为自监督模型训练不需要评估数据)。
计算引擎
数据转tfrecord算法组件支持MaxCompute和DLC引擎。您可以在执行调优页签的单机或分布式(MaxCompute/DLC)参数配置运行引擎。
示例
您可以使用数据转tfrecord算法组件构建如下工作流。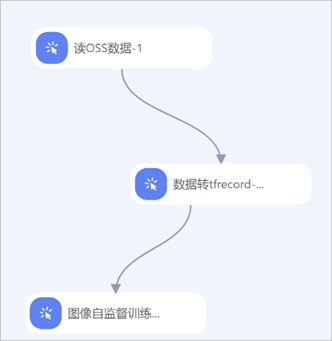
 由于本文提供的简单示例中数据转tfrecord算法组件下游组件为图像组监督训练组件,因此您需要注意数据转tfrecord算法组件以下参数配置,其他参数使用默认值或根据实际情况进行配置,详情请参见上文的组件参数:
由于本文提供的简单示例中数据转tfrecord算法组件下游组件为图像组监督训练组件,因此您需要注意数据转tfrecord算法组件以下参数配置,其他参数使用默认值或根据实际情况进行配置,详情请参见上文的组件参数:
-
配置转换数据用于何种模型训练为CLASSIFICATION。
-
配置转换类名称为自监督标注格式。
-
配置测试数据分割比例为0。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/163330.html