
Caffe是一个开源的深度学习框架。本文为您介绍如何在机器学习中使用Caffe进行数据训练。
格式转换
目前Caffe组件不支持自定义格式的训练数据,需要通过格式转换组件进行转换方可使用。
格式转换组件的输入桩连接读OSS数据组件。
-
读OSS数据组件
设置OSS数据路径。OSS的训练数据file_list(例如bucket.hz.aliyun.com/train_img/train_file_list.txt )格式如下:
bucket/ilsvrc12_val/ILSVRC2012_val_00029021.JPEG 817 bucket/ilsvrc12_val/ILSVRC2012_val_00021046.JPEG 913 bucket/ilsvrc12_val/ILSVRC2012_val_00041166.JPEG 486 bucket/ilsvrc12_val/ILSVRC2012_val_00029527.JPEG 327 bucket/ilsvrc12_val/ILSVRC2012_val_00042825.JPEG 138 -
格式转换组件组件
设置输出OSS目录等参数。例如bucket_name.oss-cn-hangzhou-zmf.aliyuncs.com/ilsvrc12_val_convert ,组件会输出转换后的data_file_list.txt和对应的数据文件。data_file_list格式如下:
bucket/ilsvrc12_val_convert/train_data_00_01 bucket/ilsvrc12_val_convert/train_data_00_02-
可视化组件设置
-
图片列表文件OSS路径:图片列表文件存放在OSS中的路径。
-
文件前缀:默认为data。
-
resize_height:默认为256。
-
resize_width:默认为256。
-
编码类型:选项,可选JPG,PNG,RAW。
-
输出OSS目录:文件输出到OSS的目录。
-
shuffle:勾选。
-
gray:是否灰度,默认不勾选。
-
image mean:是否需要产生图片mean文件,默认不勾选。
-
-
PAI命令
PAI -name convert_image_oss2oss -project algo_public_dev -Darn=acs:ram::160712891654****:role/test-1 -DossImageList=bucket_name.oss-cn-hangzhou-zmf.aliyuncs.com/image_list.txt -DossOutputDir=bucket_name.oss-cn-hangzhou-zmf.aliyuncs.com/your/dir -DencodeType=jpg -Dshuffle=true -DdataFilePrefix=train -DresizeHeight=256 -DresizeWidth=256 -DisGray=false -DimageMeanFile=false参数名称
参数描述
取值范围
是否必选,默认值/行为
ossHost
对应的OSS Host地址
例如
oss-test.aliyun-inc.com可选,默认值为
oss-cn-hangzhou-zmf.aliyuncs.com,即对内OSS使用的Host。arn
OSS Bucket默认Role对应的ARN
例如
acs:ram::XXXXXXXXXXXXXXXX:role/ossaccessroleforodps,中间xxx代表生成的rolearn的16位数字必选
ossImageList
图片文件列表
例如
bucket_name/image_list.txt必选
ossOutputDir
输出OSS目录
例如
bucket_name/your/dir必选
encodeType
编码类型
如JPG,PNG,RAW
可选,默认值为JPG
shuffle
是否shuffle数据
Bool值
可选,默认值为true
dataFilePrefix
数据文件前缀
String类型,如train或val
必选
resizeHeight
图像resize的height
int类型,用户自定义
可选,默认值为256
resizeWidth
图像resize的width
int类型,用户自定义
可选,默认值为256
isGray
图像是否为灰度图
Bool值
可选,默认值为false
imageMeanFile
是否需要生成imagemean文件
Bool值
可选,默认值为false
-
Caffe组件
Caffe是一个清晰、可读性高、快速的深度学习框架,详情请参见Caffe官网。您可以通过以下任意一种方式,配置Caffe组件参数:
-
可视化方式
页签
参数
描述
参数设置
Solver OSS路径
数据在OSS上的存放路径。
限制作业运行时长
勾选后,可以输入作业计划运行的最大时长。取值1~168。单位小时。
执行调优
GPU卡数
GPU卡的个数。默认值为1。
-
PAI命令方式
PAI -name pluto_train_oss -project algo_public_dev -DossHost=oss-cn-hangzhou-zmf.aliyuncs.com -Darn=acs:ram::160712891654****:role/test-1 -DsolverPrototxtFile=bucket_name.oss-cn-hangzhou-zmf.aliyuncs.com/solver.prototxt -DgpuRequired=1参数名称
是否必选
描述
默认值
ossHost
否
对应的OSS Host地址。
oss-cn-hangzhou-zmf.aliyuncs.comarn
是
OSS Bucket默认Role对应的ARN。例如
acs:ram::XXXXXXXXXXXXXXXX:role/ossaccessroleforodps其中xxx代表生成的rolearn的16位数字。无
solverPrototxtFile
是
solver文件在OSS中的路径,以Bucket名称开头。
无
gpuRequired
否
GPU卡的个数。
1
solver由于并行化的修改,同开源Caffe略有不同,需要注意以下几点:
-
net:net的文件位置是OSS路径。
-
type:type类型是ParallelSGD,为一个字符串。
-
model_average_iter_interval:1多卡下表示同步的频率,1表示每轮都同步一次。
-
snapshot_prefix:模型输出到OSS的目录。
net: "bucket/alexnet/train_val.prototxt"
test_iter: 1000
test_interval: 1000
base_lr: 0.01
lr_policy: "step"
gamma: 0.1
stepsize: 100000
display: 20
max_iter: 450000
momentum: 0.9
weight_decay: 0.0005
snapshot: 10000
snapshot_prefix: "bucket/snapshot/alexnet_train"
solver_mode: GPU
type: "ParallelSGD"
model_average_iter_interval: 1train_val中的datalayer需使用BinaryDataLayer,请参考如下示例。
layer {
name: "data"
type: "BinaryData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 227
mean_file: "bucket/imagenet_mean.binaryproto"
}
binary_data_param {
source: "bucket/ilsvrc12_train_binary/data_file_list.txt"
batch_size: 256
num_threads: 10
}
}
layer {
name: "data"
type: "BinaryData"
top: "data"
top: "label"
include {
phase: TEST
}
transform_param {
mirror: false
crop_size: 227
mean_file: "bucket/imagenet_mean.binaryproto"
}
binary_data_param {
source: "bucket/ilsvrc12_val_binary/data_file_list.txt"
batch_size: 50
num_threads: 10
}
}新的data Layer的名称为BinaryData,其中也支持transform param对输入图像数据进行变换,参数和caffe原生参数保持一致。
其中binary_data_param为数据层本身的参数配置,包括以下特殊的参数:
-
source:数据来源,其中路径为OSS中filelist的路径,从bucket名称开始,不包含
oss://。 -
num_threads:读取OSS数据时并发的线程数目,默认值为10。用户可以根据自己的需求进行调整。
示例
利用Caffe实现mnist的数据训练。
-
准备数据源
在Caffe相关下载章节中下载Caffe数据并解压。将数据导入OSS中,本案例路径如下图,请配合代码中的路径理解。

-
运行实验
拖拽Caffe组件拼接成如下图所示的示例。
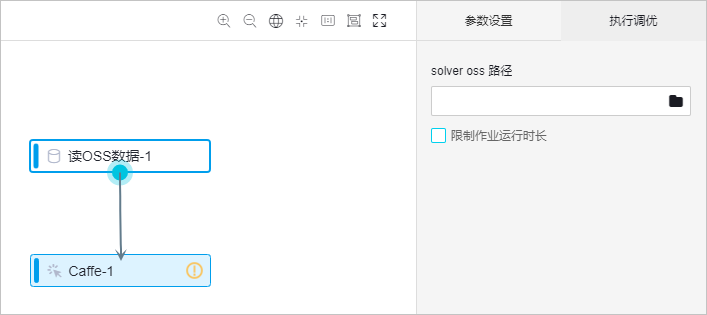
将solver oss路径指向mnist_solver_dnn_binary.prototxt文件,单击运行。
-
查看日志
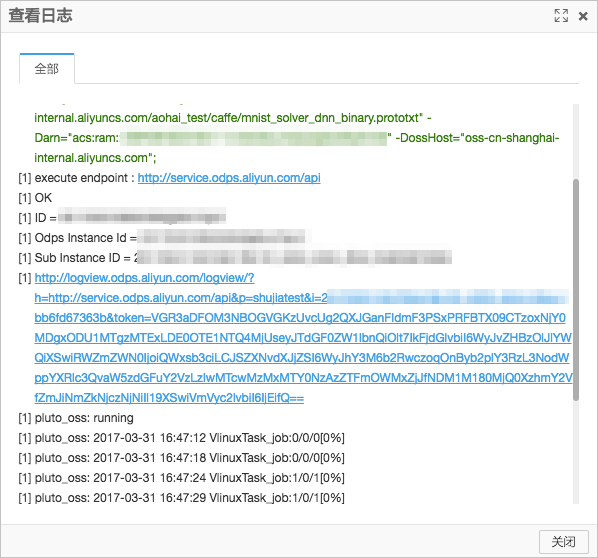
右键单击Caffe组件选择查看日志,如下图所示。
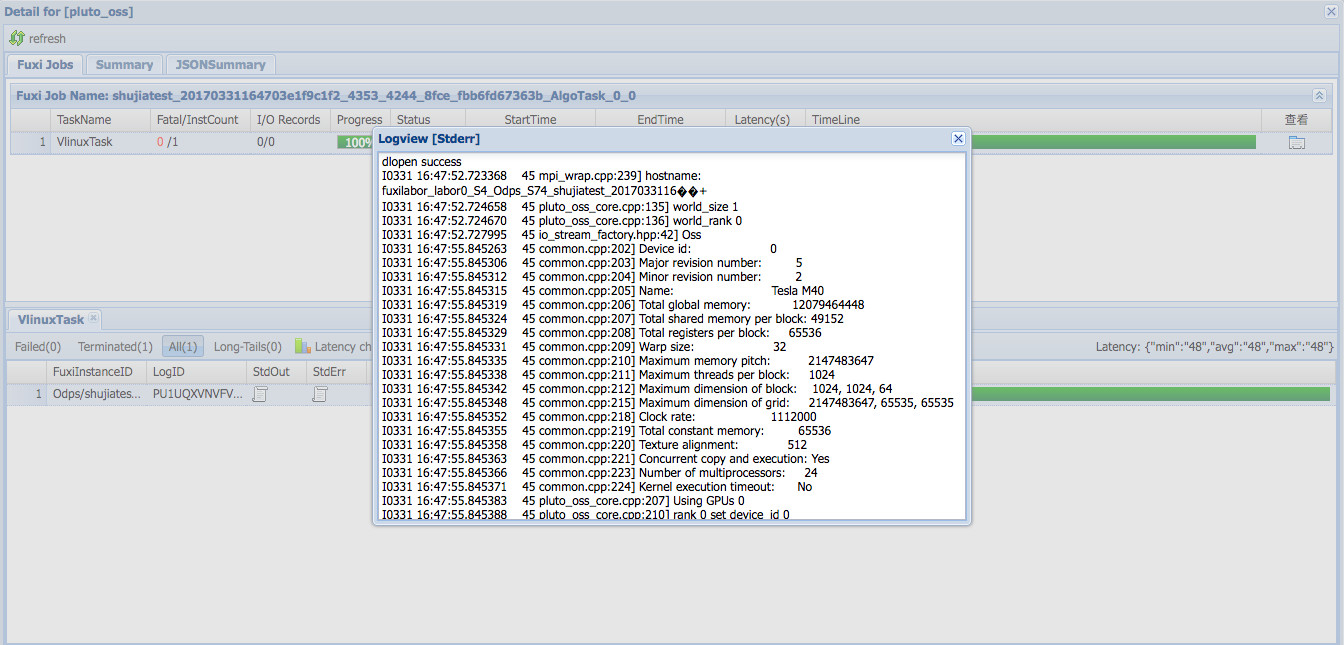
单击logview链接 > ODPS Tasks > VlinuxTask > StdErr,查看训练过程产生的日志,如下图所示。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/162884.html