
参数服务器PS(Parameter Server)致力于解决大规模的离线及在线训练任务,逻辑回归(Logistic Regression)是经典的二分类算法,广泛应用于广告及搜索场景。PS逻辑回归支持千亿样本、十亿特征的二分类训练任务。
使用限制
PS逻辑回归二分类组件的输入数据需要满足以下要求:
-
PS逻辑回归二分类组件的目标列仅支持数值类型,且0表示负例,1表示正例。如果MaxCompute表数据是STRING类型,则需要进行类型转换。例如,分类目标是Good/Bad字符串,需要转换为1/0。
-
如果数据是KV格式,则特征ID必须为正整数,特征值必须为实数。如果特征ID为字符串类型,则需要使用序列化组件进行序列化。如果特征值为类别型字符串,需要进行特征离散化等特征工程处理。
组件配置
您可以使用以下任意一种方式,配置PS逻辑回归二分类组件参数。
方式一:可视化方式
在Designer(原PAI-Studio)工作流页面配置组件参数。
|
页签 |
参数 |
描述 |
|
字段设置 |
选择特征列 |
输入数据源中,用于训练的特征列。如果输入数据为Dense格式,则支持DOUBLE及BIGINT类型。如果输入数据为Sparse KV格式,则仅支持STRING类型。 |
|
选择标签列 |
输入数据源中,标签列的名称。 |
|
|
是否稀疏格式 |
如果是否稀疏格式为true,则特征ID不能使用0,建议特征从1开始编号。 |
|
|
参数设置 |
L1 weight |
L1正则化系数。该参数值越大,模型非零元素越少。如果过拟合,则增大该参数值。 |
|
L2 weight |
L2正则化系数。该参数值越大,模型参数绝对值越小。如果过拟合,则增大该参数值。 |
|
|
最大迭代次数 |
算法的最大迭代次数,0表示迭代次数无限制。 |
|
|
最小收敛误差 |
优化算法的终止条件,通常取值为10次迭代Loss相对变化率的平均值。该参数值越小,算法执行时间越长。 |
|
|
最大特征ID |
最大的特征ID或特征维度,取值可以大于实际值。该参数值越大,内存占用越大。如果未配置该参数,则系统启动SQL任务自动计算。 |
|
|
执行调优 |
核心数 |
核心数量。 |
|
每个核的内存大小 |
每个核心的内存,单位为MB。 |
方式二:PAI命令方式
使用PAI命令方式,配置该组件参数。您可以使用SQL脚本组件进行PAI命令调用,详情请参见SQL脚本。
#训练
PAI -name ps_lr
-project algo_public
-DinputTableName="lm_test_input"
-DmodelName="logistic_regression_model"
-DlabelColName="label"
-DfeatureColNames="f0,f1,f2,f3,f4,f5"
-Dl1Weight=1.0
-Dl2Weight=0.0
-DmaxIter=100
-Depsilon=1e-6
-DenableSparse=false
#预测
drop table if exists logistic_regression_predict;
PAI -name prediction
-DmodelName="logistic_regression_model"
-DoutputTableName="logistic_regression_predict"
-DinputTableName="lm_test_input"
-DappendColNames=label
-DfeatureColNames="f0,f1,f2,f3,f4,f5"
-DenableSparse=false|
参数名称 |
是否必选 |
参数描述 |
默认值 |
|
inputTableName |
是 |
输入表的表名。 |
无 |
|
featureColNames |
是 |
输入表中,用于训练的特征列。 如果输入数据为Dense格式,则支持DOUBLE及BIGINT类型。如果输入数据为Sparse KV格式,则仅支持STRING类型。 |
无 |
|
labelColName |
是 |
输入表的标签列名,支持DOUBLE及BIGINT类型。 |
无 |
|
inputTablePartitions |
否 |
输入表中,参与训练的分区。系统支持的格式包括:
说明 指定多个分区时,分区间使用英文逗号(,)分隔。 |
全表 |
|
modelName |
是 |
输出的模型名。输出的模型默认存储为OfflineModel格式。如果enableModelIo为false,则输出模型存储到MaxCompute表。 |
无 |
|
enableModelIo |
否 |
输出的模型是否存储为OfflineModel格式,取值范围为{true,false}。如果enableModelIo为false,则输出模型存储到MaxCompute表。 |
true |
|
l1Weight |
否 |
L1正则化系数。该参数值越大,模型非零元素越少。如果过拟合,则增大该参数值。 |
1.0 |
|
l2Weight |
否 |
L2正则化系数。该参数值越大,模型参数绝对值越小。如果过拟合,则增大该参数值。 |
0 |
|
maxIter |
否 |
算法的最大迭代次数。 |
100 |
|
epsilon |
否 |
算法终止条件。 |
1.0e-06 |
|
modelSize |
否 |
最大的特征ID或特征维度,取值可以大于实际值。该参数值越大,内存占用越大。如果未配置该参数,则系统启动SQL任务自动计算。 |
0 |
|
enableSparse |
否 |
输入数据是否为稀疏格式,取值范围为{true,false}。 |
false |
|
itemDelimiter |
否 |
输入表数据为稀疏格式时,KV对之间的分隔符。 |
英文逗号(,) |
|
kvDelimiter |
否 |
输入表数据为稀疏格式时,key和value之间的分隔符。 |
英文冒号(:) |
|
coreNum |
否 |
核心数量。 |
系统自动分配 |
|
memSizePerCore |
否 |
单个核心使用的内存数,单位为MB。 |
系统自动分配 |
示例
-
使用SQL语句,生成训练数据(以Dense格式数据为例)。
drop table if exists lm_test_input; create table lm_test_input as select * from ( select 0.72 as f0, 0.42 as f1, 0.55 as f2, -0.09 as f3, 1.79 as f4, -1.2 as f5, 0 as label from dual union all select 1.23 as f0, -0.33 as f1, -1.55 as f2, 0.92 as f3, -0.04 as f4, -0.1 as f5, 1 as label from dual union all select -0.2 as f0, -0.55 as f1, -1.28 as f2, 0.48 as f3, -1.7 as f4, 1.13 as f5, 1 as label from dual union all select 1.24 as f0, -0.68 as f1, 1.82 as f2, 1.57 as f3, 1.18 as f4, 0.2 as f5, 0 as label from dual union all select -0.85 as f0, 0.19 as f1, -0.06 as f2, -0.55 as f3, 0.31 as f4, 0.08 as f5, 1 as label from dual union all select 0.58 as f0, -1.39 as f1, 0.05 as f2, 2.18 as f3, -0.02 as f4, 1.71 as f5, 0 as label from dual union all select -0.48 as f0, 0.79 as f1, 2.52 as f2, -1.19 as f3, 0.9 as f4, -1.04 as f5, 1 as label from dual union all select 1.02 as f0, -0.88 as f1, 0.82 as f2, 1.82 as f3, 1.55 as f4, 0.53 as f5, 0 as label from dual union all select 1.19 as f0, -1.18 as f1, -1.1 as f2, 2.26 as f3, 1.22 as f4, 0.92 as f5, 0 as label from dual union all select -2.78 as f0, 2.33 as f1, 1.18 as f2, -4.5 as f3, -1.31 as f4, -1.8 as f5, 1 as label from dual ) tmp;生成的训练数据如下。
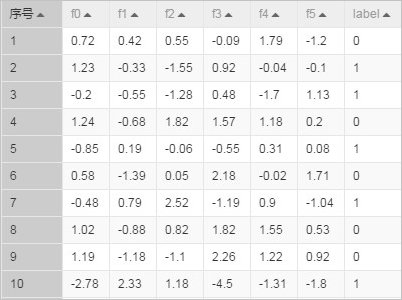

-
构建如下实验,详情请参见算法建模。
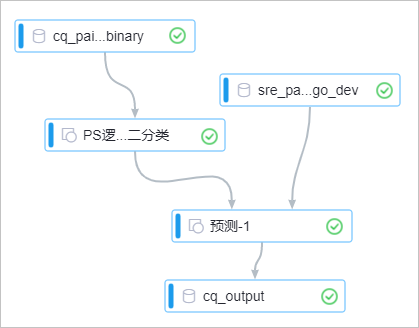
-
配置PS逻辑回归二分类组件的参数(配置如下表格中的参数,其余参数使用默认值)。
页签
参数
描述
字段设置
选择特征列
选择f0、f1、f2、f3、f4及f5列。
选择标签列
选择label列。
执行调优
核心数
输入3。
每个核的内存大小
输入1024。
-
配置预测组件的参数(配置如下表格中的参数,其余参数使用默认值)。
页签
参数
描述
字段设置
特征列
选择f0、f1、f2、f3、f4及f5列。
原样输出列
选择f0、f1、f2、f3、f4、f5及label列。
-
运行实验,查看预测结果。
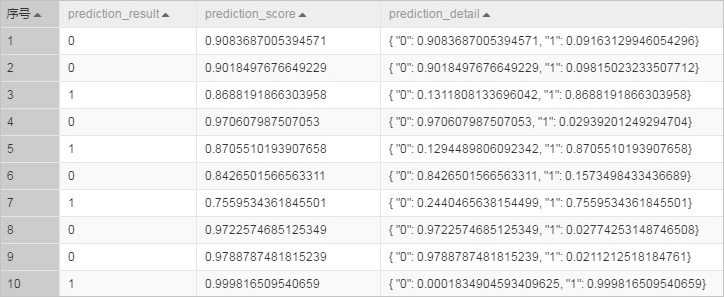 其中prediction_detail列的1表示正例,0表示负例。
其中prediction_detail列的1表示正例,0表示负例。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/162746.html