
Triton Server是一个适用于深度学习与机器学习模型的推理服务引擎,支持将TensorRT、TensorFlow、PyTorch或ONNX等多种AI框架的模型部署为在线推理服务,并支持多模型管理、自定义backend等功能。文本为您介绍如何通过镜像部署的方式部署Triton Server模型服务。
部署服务:单模型
-
在OSS Bucket中创建模型存储目录,并根据模型存储目录格式要求配置模型文件与配置文件。
每个模型目录下都至少包含一个模型版本目录和一个模型配置文件:
-
模型版本目录:包含模型文件,且必须以数字命名,作为模型版本号,数字越大版本越新。
-
模型配置文件:用于提供模型的基础信息,通常命名为
config.pbtxt。
假设模型存储目录在
oss://examplebucket/models/triton/路径下,模型存储目录的格式如下:triton └──resnet50_pt ├── 1 │ └── model.pt ├── 2 │ └── model.pt ├── 3 │ └── model.pt └── config.pbtxt其中:config.pbtxt 为配置文件,文件内容示例如下:
name: "resnet50_pt" platform: "pytorch_libtorch" max_batch_size: 128 input [ { name: "INPUT__0" data_type: TYPE_FP32 dims: [ 3, -1, -1 ] } ] output [ { name: "OUTPUT__0" data_type: TYPE_FP32 dims: [ 1000 ] } ] # 使用GPU推理 # instance_group [ # { # kind: KIND_GPU # } # ] # 模型版本配置 # version_policy: { all { }} # version_policy: { latest: { num_versions: 2}} # version_policy: { specific: { versions: [1,3]}}其中关键配置说明如下:
参数
是否必选
描述
name
否
默认为模型存储目录名。如果指定了名称,也必须与模型存储目录名称保持一致。
platfrom/backend
是
platform与backend至少配置一项:
-
platform:用于指定模型框架。常用的模型框架包含:tensorrt_plan、onnxruntime_onnx、pytorch_libtorch、tensorflow_savedmodel、tensorflow_graphdef等。
-
backend:用于指定模型框架或使用Python代码自定义推理逻辑。
-
可指定的模型框架与platform完全一样,只是设置的名称不同,框架包含:tensorrt、onnxruntime、pytorch、tensorflow等。
-
使用Python代码自定义推理逻辑,具体操作,请参见部署服务:使用backend。
-
max_batch_size
是
用于指定模型请求批处理的最大数量,若不开启批处理功能,则将该项设置为0。
input
是
用于指定以下属性:
-
name:输入数据的名称。
-
data_type:数据类型。
-
dims:维度。
output
是
用于指定以下属性:
-
name:输入数据的名称。
-
data_type:数据类型。
-
dims:维度。
instance_group
否
当资源配置中有GPU资源时,默认使用GPU进行模型推理,否则默认使用CPU。您也可以通过配置instance_group参数,来显式指定模型推理使用的资源,配置格式如下:
instance_group [ { kind: KIND_GPU } ]其中kind可配置为KIND_GPU或KIND_CPU。
version_policy
否
用于指定模型版本,配置示例如下:
version_policy: { all { }} version_policy: { latest: { num_versions: 2}} version_policy: { specific: { versions: [1,3]}}-
不配置该参数:默认加载版本号最大的模型版本。示例中resnet50_pt模型会加载模型版本3。
-
all{}:表示加载该模型所有版本。示例中resnet50_pt会加载模型版本1、2和3。
-
latest{num_versions:}:例如配置为
num_versions: 2,示例中resnet50_pt会加载最新的2个模型版本,即版本2和3。 -
specific{versions:[]}:表示加载指定版本。示例中resnet50_pt会加载模型版本1和3。
-
-
在PAI-EAS模型在线服务页面部署Triton Server服务。其中关键参数配置如下,更多详细内容,请参见服务部署:控制台。
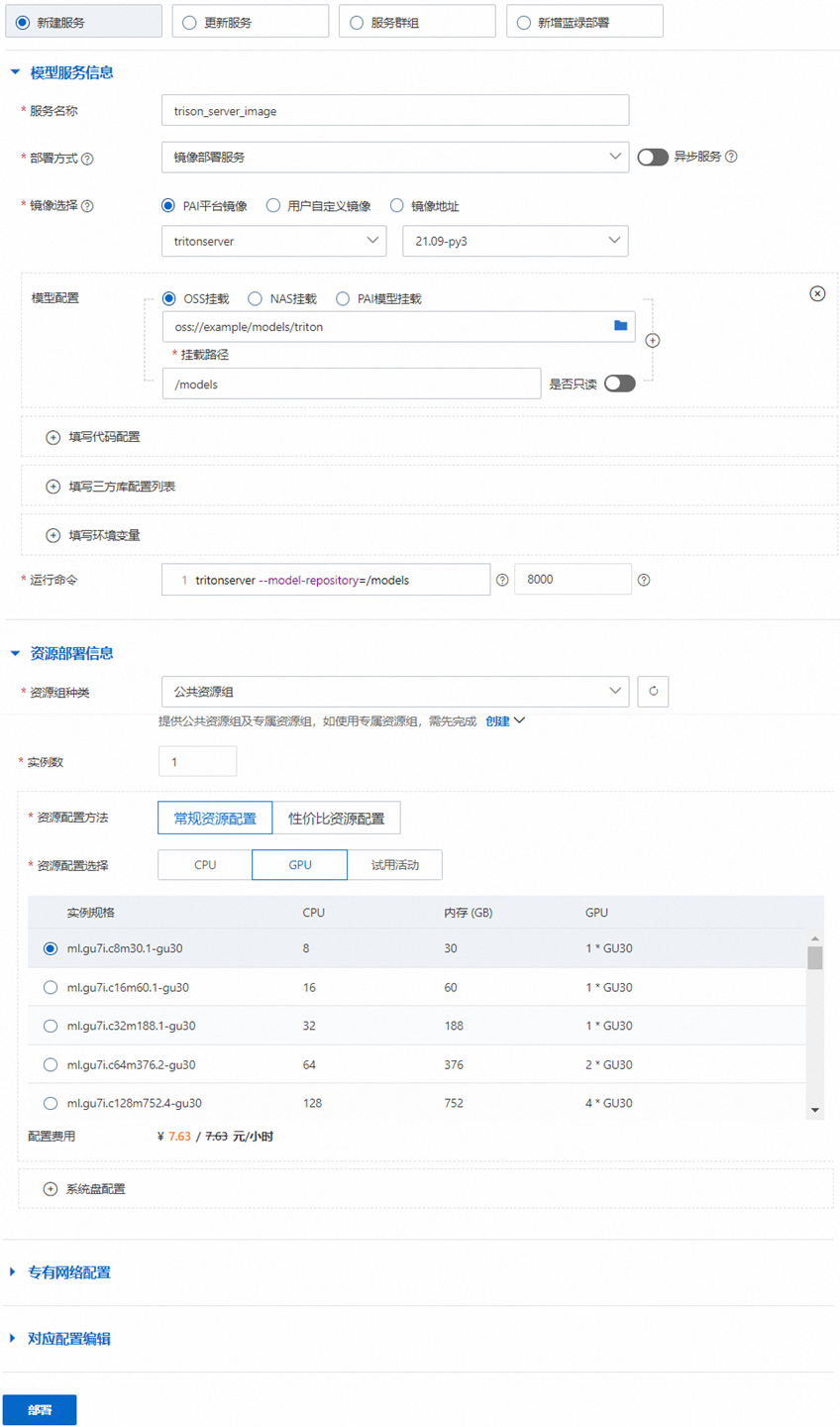

参数
描述
部署方式
选择镜像部署服务。
镜像选择
在PAI平台镜像列表中选择tritonserver和对应的镜像版本。
填写模型配置
单击填写模型配置,进行模型配置。
-
模型配置选择OSS挂载,将OSS路径配置为步骤1中模型存储目录所在的OSS Bucket目录,例如:
oss://example/models/triton/。 -
挂载路径:配置为
/models。
运行命令
tritonserver的启动参数,其中
--model-repository用于指定模型仓库路径。例如:tritonserver --model-repository=/models。端口号配置为8000,以映射tritonserver镜像在8000端口启动的HTTP服务端口。
服务部署配置示例参数如下:
{ "metadata": { "name": "trison_server_image", "instance": 1 }, "cloud": { "computing": { "instance_type": "ml.gu7i.c8m30.1-gu30", "instances": null } }, "storage": [ { "oss": { "path": "oss://example/models/triton/", "readOnly": false }, "properties": { "resource_type": "model" }, "mount_path": "/models" } ], "containers": [ { "image": "eas-registry-vpc.cn-shanghai.cr.aliyuncs.com/pai-eas/tritonserver:21.09-py3", "script": "tritonserver --model-repository=/models", "port": 8000 } ] } -
部署服务:多模型
EAS部署多模型服务的方式与部署单模型服务相同,您只需创建多个模型存储目录即可,服务会加载所有的模型,并部署在同一个服务中。例如:多个模型存储目录结构如下所示,其他参数配置详情请参见部署服务:单模型。
triton
├── resnet50_pt
| ├── 1
| │ └── model.pt
| └── config.pbtxt
├── densenet_onnx
| ├── 1
| │ └── model.onnx
| └── config.pbtxt
└── mnist_savedmodel
├── 1
│ └── model.savedmodel
│ ├── saved_model.pb
| └── variables
| ├── variables.data-00000-of-00001
| └── variables.index
└── config.pbtxt部署服务:使用backend
backend是模型推理计算的具体实现部分,它既可以调用现有的模型框架(如TensorRT、ONNX Runtime、PyTorch、TensorFlow等),也可以自定义模型推理逻辑(如模型预处理、后处理)。
backend支持 C++、Python两种语言,与C++相比, Python使用起来更加灵活方便,因此以下内容主要介绍Python backend的使用方式。
-
更新模型目录结构
以Pytorch为例,使用Python backend自定义模型的计算逻辑,模型目录结构示例如下:
resnet50_pt ├── 1 │ ├── model.pt │ └── model.py └── config.pbtxt与常规的模型目录结构相比,backend需要在模型版本目录下新增一个model.py文件,用于自定义模型的推理逻辑,并且配置文件config.pbtxt内容也需要做相应修改。
-
自定义推理逻辑
model.py文件需要定义名为TritonPythonModel的类,并实现initialize、execute、finalize三个关键的接口函数。该文件内容示例如下:
import json import os import torch from torch.utils.dlpack import from_dlpack, to_dlpack import triton_python_backend_utils as pb_utils class TritonPythonModel: """必须以 "TritonPythonModel" 为类名""" def initialize(self, args): """ 初始化函数,可选实现,在加载模型时被调用一次,可用于初始化与模型属性、模型配置相关的信息 Parameters ---------- args : 字典类型,其中 keys 和 values 都为 string 类型,具体包括: * model_config: JSON 格式模型配置信息 * model_instance_kind: 设备型号 * model_instance_device_id: 设备 ID * model_repository: 模型仓库路径 * model_version: 模型版本 * model_name: 模型名 """ # 将 JSON字符串类型的模型配置文件转为 JSON类型 self.model_config = model_config = json.loads(args["model_config"]) # 获取模型配置文件中的属性 output_config = pb_utils.get_output_config_by_name(model_config, "OUTPUT__0") # 将 Triton types 转为 numpy types self.output_dtype = pb_utils.triton_string_to_numpy(output_config["data_type"]) # 获取模型仓库的路径 self.model_directory = os.path.dirname(os.path.realpath(__file__)) # 获取模型推理使用的设备,本例中使用 GPU self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print("device: ", self.device) model_path = os.path.join(self.model_directory, "model.pt") if not os.path.exists(model_path): raise pb_utils.TritonModelException("Cannot find the pytorch model") # 通过.to(self.device)将 pytorch 模型加载到 GPU 上 self.model = torch.jit.load(model_path).to(self.device) print("Initialized...") def execute(self, requests): """ 模型执行函数,必须实现;每次请求推理都会调用该函数,若设置了 batch 参数,还需由用户自行实现批处理功能 Parameters ---------- requests : pb_utils.InferenceRequest 类型的请求列表 Returns ------- pb_utils.InferenceResponse 类型的返回列表. 列表长度必须与请求列表一致 """ output_dtype = self.output_dtype responses = [] # 遍历 request 列表,并为每个请求都创建对应的 response for request in requests: # 获取输入 tensor input_tensor = pb_utils.get_input_tensor_by_name(request, "INPUT__0") # 将 Triton tensor 转换为 Torch tensor pytorch_tensor = from_dlpack(input_tensor.to_dlpack()) if pytorch_tensor.shape[2] > 1000 or pytorch_tensor.shape[3] > 1000: responses.append( pb_utils.InferenceResponse( output_tensors=[], error=pb_utils.TritonError( "Image shape should not be larger than 1000" ), ) ) continue # 在 GPU 上进行推理计算 prediction = self.model(pytorch_tensor.to(self.device)) # 将 Torch output tensor 转换为 Triton tensor out_tensor = pb_utils.Tensor.from_dlpack("OUTPUT__0", to_dlpack(prediction)) inference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor]) responses.append(inference_response) return responses def finalize(self): """ 模型卸载时调用,可选实现,可用于模型清理工作 """ print("Cleaning up...")重要
-
如果使用GPU进行推理计算,此时在模型配置文件config.pbtxt中指定
instance_group.kind为GPU的方式无效,需要通过model.to(torch.device("cuda"))将模型加载到GPU,并在请求计算时调用pytorch_tensor.to(torch.device("cuda"))将模型输入Tensor分配到GPU。您只需要在部署服务时配置GPU资源,即可使用GPU进行推理计算。 -
如果使用批处理功能,此时在模型配置文件config.pbtxt中设置max_batch_size参数的方式无效,您需要自行在execute函数中实现请求批处理的逻辑。
-
request与response必须一一对应,每一个request都要返回一个对应的response。
-
-
更新配置文件
配置文件config.pbtxt内容示例如下:
name: "resnet50_pt" backend: "python" max_batch_size: 128 input [ { name: "INPUT__0" data_type: TYPE_FP32 dims: [ 3, -1, -1 ] } ] output [ { name: "OUTPUT__0" data_type: TYPE_FP32 dims: [ 1000 ] } ] parameters: { key: "FORCE_CPU_ONLY_INPUT_TENSORS" value: {string_value: "no"} }其中关键参数说明如下,其余配置与之前保持一致即可。
-
backend:需指定为python。
-
parameters:可选配置,当模型推理使用GPU时,可将FORCE_CPU_ONLY_INPUT_TENSORS参数设置为no,来避免推理计算时输入Tensor在CPU与GPU之间来回拷贝产生不必要的开销。
-
-
-
部署服务。
使用Python backend必须设置共享内存,最后通过如下配置创建模型服务,即可实现自定义模型推理逻辑。关于如何使用客户端创建模型服务,请参见服务部署:EASCMD&DSW。
{ "metadata": { "name": "triton_server_test", "instance": 1, }, "cloud": { "computing": { "instance_type": "ml.gu7i.c8m30.1-gu30", "instances": null } }, "containers": [ { "command": "tritonserver --model-repository=/models", "image": "eas-registry-vpc..cr.aliyuncs.com/pai-eas/tritonserver:23.02-py3", "port": 8000, "prepare": { "pythonRequirements": [ "torch==2.0.1" ] } } ], "storage": [ { "mount_path": "/models", "oss": { "path": "oss://oss-test/models/triton_backend/" } }, { "empty_dir": { "medium": "memory", // 配置共享内存为1 GB。 "size_limit": 1 }, "mount_path": "/dev/shm" } ] }其中:
-
name:需要自定义模型服务名称。
-
storage.oss.path:更新为您的模型存储目录所在的OSS Bucket路径。
-
containers.image:将替换为当前地域,例如:华东2(上海)为cn-shanghai。
-
调用服务:发送服务请求
您可以通过客户端发送HTTP请求来使用模型服务,Python代码示例如下:
import numpy as np
import tritonclient.http as httpclient
# url 为 EAS服务部署后生成的访问地址
url = '1859257******.cn-hangzhou.pai-eas.aliyuncs.com/api/predict/triton_server_test'
triton_client = httpclient.InferenceServerClient(url=url)
image = np.ones((1,3,224,224))
image = image.astype(np.float32)
inputs = []
inputs.append(httpclient.InferInput('INPUT__0', image.shape, "FP32"))
inputs[0].set_data_from_numpy(image, binary_data=False)
outputs = []
outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False)) # 获取 1000 维的向量
# 指定模型名称、请求Token、输入输出
results = triton_client.infer(
model_name="",
model_version="",
inputs=inputs,
outputs=outputs,
headers={"Authorization": ""},
)
output_data0 = results.as_numpy('OUTPUT__0')
print(output_data0.shape)
print(output_data0)其中关键参数配置如下:
|
参数 |
描述 |
|
url |
配置服务访问地址,服务访问地址需要省略 |
|
model_name |
配置模型目录名称,例如resnet50_pt。 |
|
model_version |
配置实际的模型版本号,每次只能对一个模型版本发送请求。 |
|
headers |
将替换为服务Token,您可以在公网地址调用页签查看Token。 |
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/161995.html