
本工作流以广告CTR预测场景为例,为您介绍如何使用PAI提供的数据挖掘组件进行离线调度。
背景信息
本工作流流程如下:
- 通过历史数据,在阿里云机器学习平台上进行模型训练。
- 通过大数据开发套件对模型进行调度。
- 每天凌晨对广告投放进行CTR预测,甄选出符合标准的广告进行推送。
本工作流数据集是通过Random算法随机生成的,因此不对工作流结果进行评估,仅介绍如何构建工作流及大数据开发套件调度。
数据集
本工作流训练数据集包括2016年09月19日和2016年09月20日的历史数据,针对2016年09月21日的数据进行预测,使用MaxCompute分区表。数据集的具体字段如下。
| 字段名 | 类型 | 描述 |
|---|---|---|
| id | STRING | 广告的唯一标识。 |
| age | DOUBLE | 广告投放人群的年龄。 |
| sex | DOUBLE | 广告投放人群的性别。1表示男性,0表示女性。 |
| duration | DOUBLE | 广告在界面的停留时长,单位为秒。 |
| place | DOUBLE | 广告投放位置,按照投放位置从上到下的顺序依次为0~4。 |
| ctr | DOUBLE | 广告CTR。如果广告点击量除以展现量的结果大于0.03,则该参数取值为1,反之为0。 |
| dt | STRING | 年月日,格式为YYYYMMDD。 |
本工作流数据表ad的示例如下。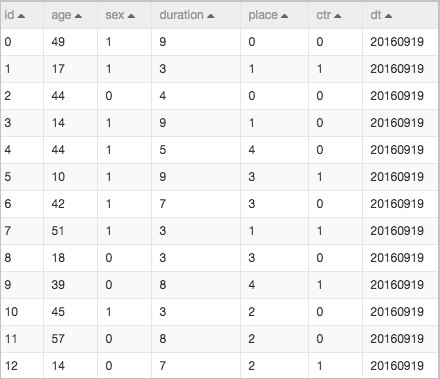

步骤一:创建工作流
- 新建自定义工作流,并进入工作流,详情请参见新建自定义工作流。
- 构建工作流的流程。
- 在左侧组件列表,将源/目标下的读数据表组件向画布中拖入两个,并分别重命名为ad-1和ad-2。
- 在左侧组件列表,将数据预处理下的归一化组件向画布中拖入两个。
- 在左侧组件列表,将机器学习 > 二分类下的逻辑回归二分类组件拖入画布中。
- 在左侧组件列表,将机器学习下的预测组件拖入画布中。
- 在左侧组件列表,将源/目标下的写数据表组件拖入画布中,并重命名为ad_result-1。
- 将以上组件拼接为如下工作流。
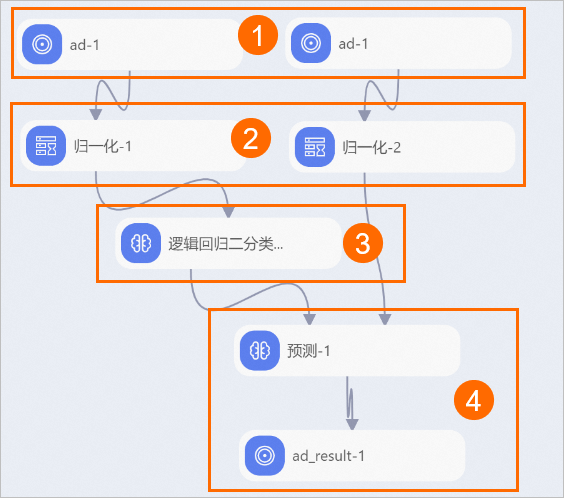
序号 描述 ① 数据源导入。 ② 数据预处理。 ③ 模型训练。 ④ 预测。
- 配置组件参数。
- 分别单击画布中的ad-2(训练数据源)和ad-1(预测数据源)组件,在右侧面板,配置工作流数据源。
页签 参数 描述 表选择 表名 输入ad。 分区 选中分区复选框。 参数 配置为 dt=@@{yyyyMMdd},确定预测数据为每天的增量数据。 字段信息 源表字段信息 配置表选择后,系统会自动同步该数据表的源表字段信息,无需手动配置。 - 单击画布中的逻辑回归二分类组件,在右侧面板,配置参数(仅配置如下参数,其他参数使用默认值即可)。
页签 参数 描述 字段设置 训练特征列 选择age、sex、duration及place列。 目标列 选择ctr列。 - 单击画布中的预测组件,在右侧面板,配置参数(仅配置如下参数,其他参数使用默认值即可)。
页签 参数 描述 字段设置 特征列 选择age、sex、duration及place列。 原样输出列 选择ctr列。
- 分别单击画布中的ad-2(训练数据源)和ad-1(预测数据源)组件,在右侧面板,配置工作流数据源。
- 单击画布左上方的运行。
- 工作流运行结束后,右键单击画布中的ad_result-1,在快捷菜单,单击查看数据即可查看预测生成的结果表,如下图所示。
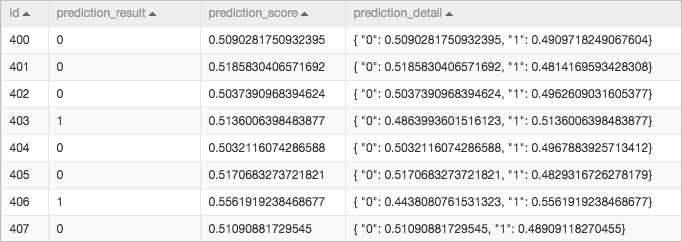 其中prediction_result表示每个广告ID是否被点击(1表示被点击,0表示未被点击),prediction_score表示对应被点击的概率。
其中prediction_result表示每个广告ID是否被点击(1表示被点击,0表示未被点击),prediction_score表示对应被点击的概率。
步骤二:离线调度
- 使用DataWorks创建、配置并提交PAI任务,详情请参见机器学习(PAI)节点。配置调度任务时,将具体时间配置为每日凌晨0点进行训练和推送信息,详情请参见时间属性配置说明。
- 在提交任务页面,单击右上方的运维,即可进入运维中心查看任务日志,详情请参见查看并管理周期任务。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/161652.html