
您需要在完成准备工作后创建DLC任务,本文介绍使用公共资源组或专有资源组时,如何创建DLC任务。
前提条件
已完成准备工作:
-
准备资源组
-
(可选)准备数据集
-
(可选)准备代码集
-
(可选)准备镜像
背景信息
关于创建任务的最佳实践,请参见快速提交单机PyTorch迁移学习任务。
操作步骤
-
进入新建任务页面。
-
登录PAI控制台。
-
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
-
在工作空间页面的左侧导航栏选择模型开发与训练 > 分布式训练(DLC),在分布式训练任务页面中单击新建任务,进入新建任务页面。
-
-
在新建任务页面,配置如下训练任务的参数。
-
基本信息配置。
参数
描述
资源组
选择公共资源组或已购买的专有资源组。选择专有资源组后,您可以看到将使用的资源组的资源用量/总量。。
说明
-
公共资源组:完成DLC授权后,即为您准备好公共资源组,无需您手动添加资源组等操作。
目前公共资源组支持运行的资源上限为GPU 2卡、CPU 8核。如果您在训练任务时使用的公共资源超出上限,请联系您的商务经理来提升资源上限。
-
专有资源组:您需要先创建专有资源组,并为专有资源组购买计算资源,详情请参见新建及管理通用计算资源。
优先级
当资源类型选择专有资源组时,支持配置该参数。
同时运行的任务执行优先级,取值范围为[1,9],取值为1表示优先级最低。
节点镜像
工作节点的镜像。当前支持选择使用不同类型的镜像:
-
社区镜像:由社区提供的标准镜像,不同的镜像的详情请参见社区镜像版本详情。
-
PAI平台镜像:由阿里云PAI产品提供的多种官方镜像,支持不同的资源类型、Python版本及深度学习框架TensorFlow和PyTorch,镜像列表请参见公共镜像列表。
-
用户自定义镜像:可选择使用您添加到PAI的自定义的镜像,选择前,您需要先将自定义镜像添加到PAI中,操作详情请参见查看并添加镜像。
-
镜像地址:支持配置您的自定义镜像、社区镜像及PAI平台镜像地址。您需要在配置框中配置公网环境下可访问的Docker Registry Image URL。
如果您配置的是私有镜像地址,您需要单击输入,并配置镜像仓库用户名和镜像仓库密码,为私有镜像仓库授权。
任务类型
支持以下类型:
-
Tensorflow
-
PyTorch
-
XGBoost
-
OneFlow
-
ElasticBatch
数据集配置
指定任务运行过程中,任务数据的存储位置。
如果您提交的训练任务需要更大的存储空间,可以配置数据集。
此处需配置为前期已准备好的数据集,数据集配置方式请参见(可选)准备数据集。
重要
如果配置了CPFS类型的数据集,则需要配置专有网络,且选择的专有网络需要与CPFS一致。否则,提交的DLC训练任务会运行异常,表现为已出队。
代码配置
指定任务代码文件的存储位置(代码仓库信息)。此处需配置为此前已准备好的代码配置,配置方式请参见(可选)准备代码集。
说明
由于DLC会将代码下载至指定工作路径,所以您需要有代码仓库的访问权限。
执行命令
本任务需要执行的命令。支持Shell命令。例如,使用
python -c "print('Hello World')"运行Python。说明
-
如果配置了数据集,则训练结果默认输出到数据集挂载目录。
-
如果您在执行命令中通过配置启动参数来指定了输出路径,则训练结果输出到指定路径中。
三方库配置
支持以下两种方式配置第三方库:
-
三方库列表:直接在下方文本框中输入三方库。
-
requirements.txt文件目录:将第三方库写入requirements.txt文件中,在下方文本框中指定该requirements.txt文件的路径。
高级配置
当任务类型为PyTorch类型的任务时,支持通过高级配置提高训练灵活性,或满足一些特定的训练场景。
-
配置要求:
-
需配置为逗号分隔的一组字符串形式,其中每个字符串为
key=value的形式。 -
其中key为当前支持的高级参数,value需配置为对应参数的取值。
-
当前支持的高级参数列表及取值说明请参见附录:高级参数列表。
-
-
典型场景与配置示例:
-
场景:
利用高级配置参数实现worker间网络互通,从而实现更为灵活的训练方法。例如利用额外开放的端口,启动如Ray之类的框架,配合PyTorch进行更高级的分布式训练。
-
配置示例:
createSvcForAllWorkers=true,customPortNumPerWorker=100后续可通过
JOB_NAME和CUSTOM_PORTS环境变量获取到域名和可用端口号,即可拉起、连接到Ray之类的框架。
-
容错监控
打开容错监控开关,系统提供作业检测和控制能力,可以及时检测出训练任务算法层面的报错,从而规避错误,提升GPU利用率。比如:额外参数配置为–enable-job-hang-detection=true –job-hang-interval=3600表示开启log hang检测,配置检测时长为3600秒。更详细的配置说明,请参见基于AIMaster的容错监控。
说明
目前,马来西亚(吉隆坡)地域不支持容错监控功能。
专有网络配置
当资源类型选择公共资源组时,支持配置该参数。
选择当前地域可用的专有网络,并选择对应的交换机与安全组。
配置完成后,任务运行的集群将能够直接访问此专有网络内的服务,并使用此处选择的安全组进行安全访问限制。
重要
-
当前运行DLC任务时,需保障任务资源组实例、数据集存储(OSS)在同一地域的VPC网络环境中,且与代码仓库的网络是连通状态。
-
如果数据集配置选择CPFS类型的数据集,需要配置专有网络,且选择的专有网络需要与CPFS一致。否则提交的DLC训练任务会运行异常,表现为已出队。
-
-
任务资源配置。
任务资源配置时,可选择使用标准模式或进阶模式。
-
标准模式:默认用标准模式,此模式下创建的节点为Worker类型的节点。
-
进阶模式:选择进阶模式后,您可以选择添加更多类型的节点,包括Worker节点、PS节点、Chief节点、Evaluator节点、GraphLearn节点。
当资源类型选择公共资源组时,各类节点的配置参数一致,均包含节点数量、节点配置等配置项。
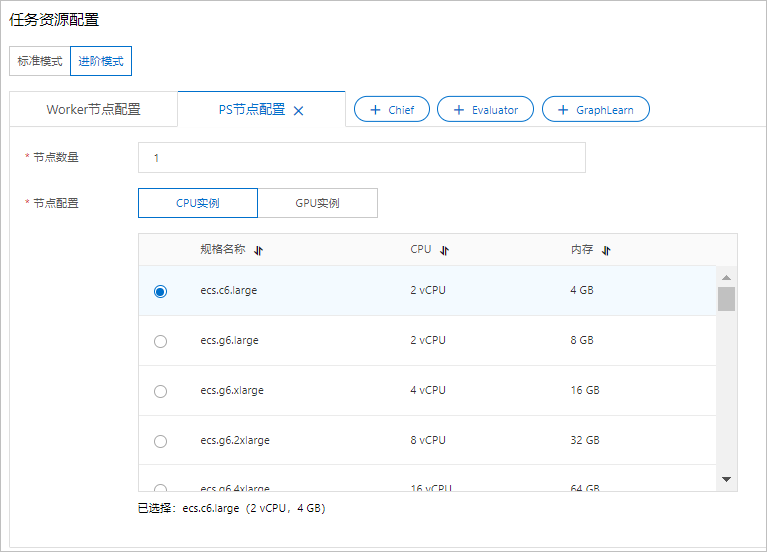

参数
描述
节点数量
当前镜像和规格的节点数量。
节点配置
计算节点的规格,详细的规格列表和费用请参见DLC计费说明。
使用竞价实例
如果您需要使用阿里云的竞价实例,请联系您的商务经理来处理。
运行时间比较短的计算任务、可中断和继续训练的计算任务等,对运行时长和连续性要求不高的任务,建议选择使用竞价实例,可大大节约资源成本。
使用竞价实例低成本运行任务的实践请参见低成本运行任务:使用竞价实例(抢占实例)。
说明
-
竞价实例(抢占式实例)是一种按需实例,相对于按量付费实例,价格有一定的折扣,可为您节约资源成本,详细介绍请参见什么是抢占式实例。
-
阿里云竞价实例的出价模式有使用自动出价和设置您的最高价两种,使用竞价实例运行DLC任务时,使用自动出价这种出价模式,即以实时的市场价格作为实例规格的计费价格。
当资源类型选择专有资源组时,各类节点的配置参数一致,均包含节点数量、CPU(核数)、内存(GB)等配置项。

-
-
配置最长运行时长。
设置任务运行的最长时长,配置完成后,后续任务运行超过最长时长后即返回任务运行停止。
如果保持默认配置,任务运行时长不受该参数限制。
-
-
单击提交。
当界面提示提交成功后,即开始创建运行任务。您可以单击任务名称进入任务详情页面中查看当前任务的执行状态。关于DLC任务执行状态详情,请参见DLC任务执行状态。
对于已提交的任务,您后续也可以直接前往AI资产管理 > 任务页面查看详情,或进行克隆等管理操作。详情请参见创建及管理分布式训练任务。
DLC任务执行状态
目前DLC的任务执行状态顺序为创建中 -> 排队中 -> 已出队 -> 运行中 -> 已成功、已失败或已停止。
-
当任务执行状态为已出队时如何处理?
-
当DLC任务执行状态为已出队时,表示任务已经开始进行资源调度,大约需要等待5分钟,任务执行状态会变为运行中。
-
如果任务长时间处于已出队状态,可能是因为您创建的分布式训练任务配置了CPFS类型的数据集,但没有配置专有网络导致的。您需要重新创建分布式训练任务,配置CPFS类型数据集并配置专有网络,且选择的专有网络需要与CPFS一致。
-
-
当任务执行状态为已失败时如何处理?
您可以在任务详情页面中,将鼠标悬浮到任务执行状态后的
 ,或者查看实例操作日志,来初步定位任务执行失败的原因。
,或者查看实例操作日志,来初步定位任务执行失败的原因。
典型场景
以下为常见场景下的任务配置实践,您可单击对应链接查看详细内容。
-
定时自动提交任务
-
提交任务(通过Python SDK)
-
低成本运行任务:使用竞价实例(抢占实例)
后续步骤
提交运行任务后,您可关注任务运行状态,也可在任务运行后查看任务运行的账单明细,账单明细查看请参见账单明细。
附录:高级参数列表
|
参数(key) |
参数说明 |
参数取值(value) |
|
|
是否允许worker间网络互通。
打开后,每个worker的域名即为worker名,如 |
|
|
|
允许用户定义每个worker上开放的网络端口,可与 若未配置,则默认仅有master上开放23456号端口。因此也请注意在该自定义端口列表中避开23456号端口。 重要 该参数与 |
分号分隔的一组字符串,其中每个字符串为一个端口号,或由短横线连接的一个端口范围,如 |
|
|
允许用户请求为每个worker开放若干个网络端口,可与 若未配置,则默认仅有master上开放23456号端口。DLC会根据参数定义的端口数目,为worker随机分配端口,具体分配的端口号会通过环境变量 重要 该参数与 |
整数(最大为65536) |
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/160781.html