
MaxCompute中不同类型计算任务的操作对象(输入、输出)都是表。表设计是否合理将影响存储和计算的性能,进而影响到存储和计算的计费。
声明
本文中介绍的非功能性规范均为建议性规范,产品功能无限制,仅供参考。
表设计主要目标
表设计主要影响
表设计影响的操作有:创建表、导入数据、更新表、删除表及管理表。
其中,导入数据场景按照实时数据采集和离线导入批量数据的方式分为如下三种:
- 导入立即查询与计算。导入后立即查询与计算,需要考虑每次导入的数据量,减少流式小量数据导入。
- 多次导入并定时查询与计算。
- 导入后生成中间表进行计算。
合理的表设计和数据集成周期管理能够降低数据在存储期间的成本。不合理的数据导入及存储(小文件)会影响整体的存储性能、计算性能、运维稳定性。MaxCompute优先按照业务逻辑对批量数据进行计算,例如,按照分区进行计算。
表设计步骤
- 确定所属项目空间,依据业务过程规划表类型,分析数据层次。
- 定义表描述,进行权限定义与Owner定义。
- 依据数据量、数据集成特点定义分区表或非分区表。
- 定义字段或分区字段。
- 创建表和转换表。
- 明确导入数据场景的相关因素(包括批量数据写入、流式数据写入、周期性条式数据插入)。
- 定义表和分区的生命周期。
说明
- 创建完表后,您可以根据业务变化修改表的Schema。例如,设置生命周期RangeClustering。
- 在表设计阶段,需要特别注意区分数据的场景(批量数据写入、流式数据写入、周期性条式数据插入)。
- 合理使用非分区表和分区表。建议采用分区表来设计日志表、事实表和原始采集表等,并按照时间进行分区。
- 注意表和分区的限制条件。
表数据存储规范
- 按数据层规划数据的生命周期:
- 源表ODS层:每天从业务系统同步过来的数据,全部保留,生命周期定义永久保存。当下游数据受损时,可以从ODS恢复数据。若ODS每天同步过来的是全量表,则可以通过全表拉链的方式来压缩存储。
- 数据仓库(基础)层:至少保留一份完整的全量数据(不必像ODS那样存储冗余的全量表)。您可以通过拆表或者做分区来提升性能。
- 数据集市层:数据将被按需保留1~3年。数据集市的数据比较容易生成,所以无需保留久远的历史数据。
- 按数据变更规划数据的保存方式:
- 记录客户属性、产品属性的历史变化情况,以便追溯某个时点的值。
- 在事实表里冗余维表的字段,即把事件发生时的各种维度属性值与该事件绑定起来。使用者无需关联多张表就可以使用数据。此方式仅可应用于数据应用层。
- 任意用拉链表或者日快照的形式,记录维表的变化情况。这使得数据结构变得灵活、易于扩展,数据一致性得到了增强,数据加工者可以更加方便地管理数据。此方式仅可应用于数据基础层。
数据导入通道与表设计
通道类型有以下几种:
- DataHub
规划写入的分区与写入流量之间的关系。数据达到64 MB会执行1次Commit。
- 数据集成或DataX
规划写入表分区的频率。数据达到64 MB会执行1次Commit,以免Commit空目录。
- DTS
规划写入的表存量分区与增量分区的关系。设置Commit频率。
- 客户端(Run SQL or Tunnel upload)
需要避免高频小数据量文件的插入或者上传。
- SDK
SDK执行INSERT INTO语句,数据上传至表或者分区后,使用MERGE语句整理小文件。
说明
- MaxCompute导入数据的通道只能是Tunnel SDK或执行INSERT INTO语句,请避免流式插入数据。
- 以上各通道本身均由自身逻辑进行流式数据写入、批量数据写入和周期调度写入。
- 当使用数据通道写入表或分区时,需将1次写入的数据量控制在合理范围,例如,64 MB以上。
分区设计与存储逻辑
一张表里有很多个一级分区,每个一级分区都会按时间存储二级分区,每个二级分区都会存储所有的列,如下图所示。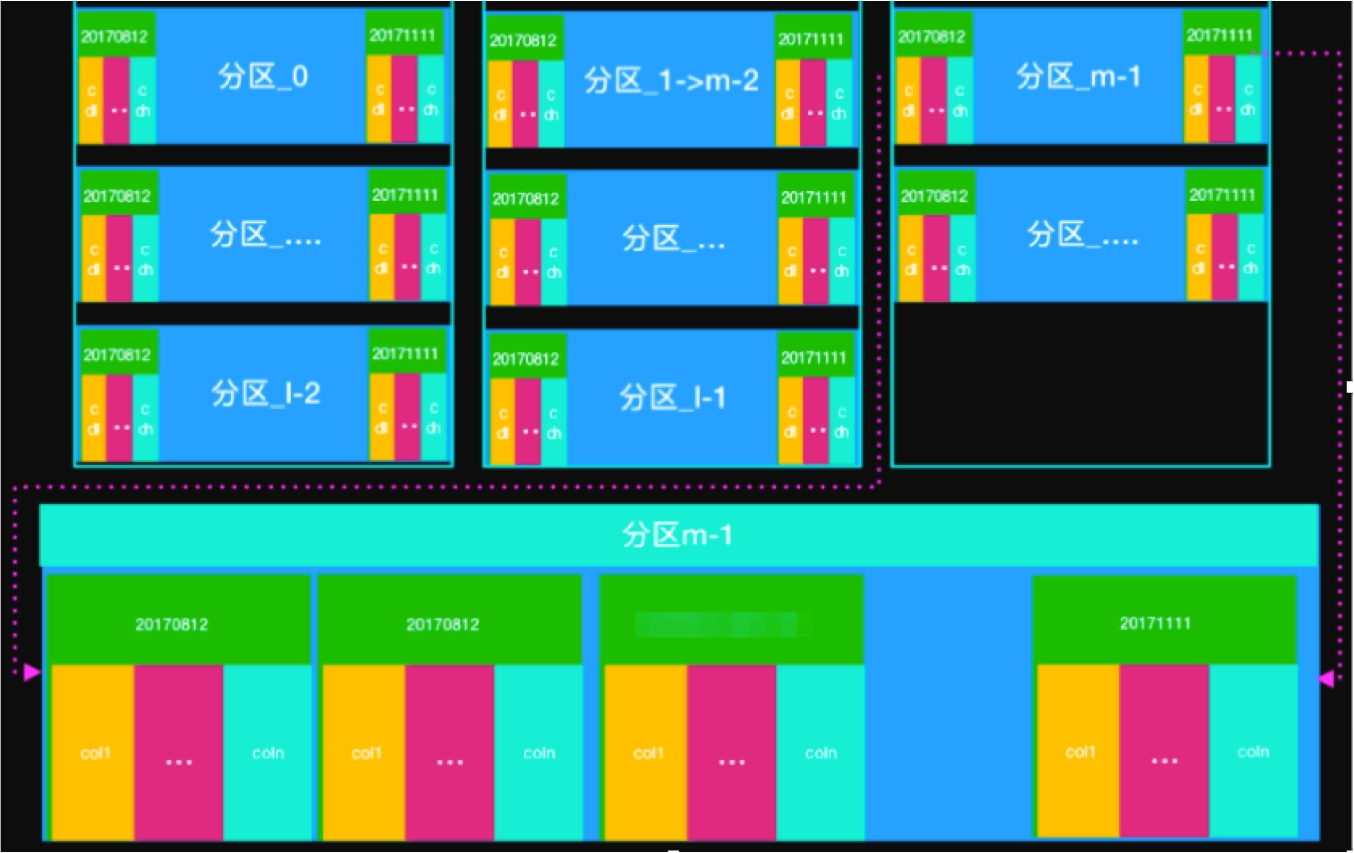
 分区设计需要注意:
分区设计需要注意:
- 设置分区的数量上限。
- 避免每个分区中只存少量数据。
- 以方便数据查询和计算为前提设置分区列。
- 避免每个分区中出现多次数据写入。
表和分区设计的基本规则
- 所有的表和字段名要使用统一的命名规范。命名要求如下:
- 能区分该表的业务类型。
- 能区分该表是事实表、维度表、日志表或极限存储表。
- 能区分该表的实体信息。
- 不同表中具有相同业务含义的字段要定义成统一的数据类型,避免不必要的类型转换。
- 分区设计及使用规则如下:
- 支持新增分区,不支持新增分区字段。
- 单表支持的分区数量上限为6万个。
- 对于多级分区的表,如果想添加新的分区,则必须指明全部的分区值。
- 不支持修改分区列的列名,只能修改分区列对应的值。修改多级分区的一个或者多个分区值时,多级分区的每一级的分区值都必须写上。
分区设计
在计算的时候可以使用分区裁剪是分区的优势。分区设计需要关注如下内容:
- 分区字段和普通字段选择
通过分区字段,您可以划分数据扫描范围,更加方便地管理数据。
您可以在创建表时设置普通字段和分区字段。普通字段可以被理解为数据文件的数据,而分区字段可以被理解为文件系统的目录。表的存储空间主要是普通字段占用的空间。设置分区字段时,您可以从数据管理和数据扫描方面考虑,来选择对应的字段。不具备规律、类型数量大于10000且不经常作为查询条件的字段,应该被设置成普通字段。
分区列虽不直接存储数据,但如同文件系统里的目录,可以方便您管理数据。例如,在计算时如果指定具体的分区,则计算过程中只需查询对应分区,从而减少计算输入量。
分区表的分区列级数不能超过6级,即底层存储数据的目录层数不能超过6层。因此应为分区表设置合适的生命周期。当部分数据的生命周期与其它数据不同时,您可以通过细粒度分区实现对部分数据的管理。
- 分区字段定义依据
按优先级高低排序如下:- 分区列的选择应充分考虑时间因素,尽量避免更新存量分区。
- 如果有多个事实表(不包括维度表)进行JOIN,应将作为查询条件的字段置为分区列。
- 选择GROUP BY或DISTINCT包含的列作为分区列。
- 选择值分布均匀的列,而不要选择数据倾斜的列作为分区列。
- 常用SQL语句中如果包含某列的等值或IN的查询条件,则选择该列作为分区列。
select … from table where id=123 and ….;
- 分区个数定义依据
- 时间分区
建议按天或月进行分区。如果按小时进行分区,则二级分区的平均数量不应超过8个。
- 地域分区
如果对省、市、县进行分区,则应考虑进行多级分区。23个省,5个自治区,4个直辖市,2个特别行政区,50个地区(州、盟),661个市(其中直辖市4个、地级市283个、县级市374个),1636个县(自治县、旗、自治旗、特区和林区),按照最细粒度县进行分区后,不应再按照更细粒度的小时进行分区。
- 单分区与多级分区
在单分区下,建议每次写入的数据量不超过64 MB。如果为多级分区,则需保证每个最细粒度级分区下的二级分区数据都遵循单分区个数规则。
- 单表分区
单表分区数(包括下级分区)不能超过6万。
- 时间分区
- 分区数量和数据量建议
- 建议单个分区中的数据量不要太大。
- 应尽量避免分区数据倾斜,避免单个表不同分区的数据量差异超过100万。
- 分区设计时应合理规划分区个数,较细粒度的分区在跨分区扫描时会影响SQL的执行性能。
- 单个分区中数据量较大的情况下,MaxCompute执行任务时会进行分片处理而不影响分区裁剪的优势。
- 单个分区中文件数较多时,会影响MaxCompute Instance数量,造成资源浪费和SQL性能的下降。
- 采用多级分区时,建议先按日期分区,然后按交易类型分区。
- 多种交易类型混合的表,建议您拆表,一种交易类型独立成一张表,然后每张表按日期分区。
- 维度表不进行分区。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/159962.html