
本文为您整合了使用Proxima CE过程中的常见问题。
Proxima CE用的是哪里的资源?
用户所在MaxCompute Project下的资源。
输入表中的vector可以直接使用MaxCompute的Binary类型吗?
目前不支持,Proxima CE当前版本构建索引的处理方法是将doc表中的vector列转换成索引,doc表中的vector列默认只支持STRING类型,暂不支持BINARY类型。但是Proxima CE对BINARY类型的输入也做了一些优化,提供了-binary_to_int命令行参数,即假设分割符为半角逗号,:
- 如果-binary_to_int值为false,用户的输入类似于
1,1,1,1,1,1,….。 - 如果-binary_to_int值为true,用户的输入类似于
12345,13423,13325,….。
从N个0/1值转换为了N/32个整数,能对生成的索引起到压缩空间的作用。
如何设置行列值(-column_num和-row_num)?
Proxima CE属于分布式离线向量处理引擎,当前主要依托MaxCompute平台的MapReduce(简称MR)来处理超大规模数据。在build过程,需要分列(column),将doc划分到每个列上构建索引;在seek过程中,需要分行(row),将query划分到每个行上检索。通过分行分列来处理超大规模的数据。
对于使用者而言:
- 列(column)影响build阶段,列越多,每列索引大小降低,单列构建检索速度提高,加速build阶段,但使用的集群机器资源变多。
- 行(row)影响seek阶段,行越多,每行检索的query变少,单行检索速度提升,加速seek阶段,同样使用的集群机器资源变多。
因此对于行列的划分需要考虑以下限制:
- 默认集群的资源限制。需要联系用户所在MaxCompute Project对应的Project Owner了解。
- MapReduce的实例限制。目前MaxCompute MR的reduce任务限制99999个实例,实例个数在build阶段个数为
column_num,在seek阶段个数为column_num * row_num。因此需要保证column_num * row_num<99999。
考虑到上述架构以及相关限制,我们通常推荐用户使用默认的行列数配置。即不需要指定,Proxima CE会根据用户输入的相关参数计算出默认的行列数,具体的计算方式请参考多类目检索。
当然系统计算出的行列是保障正常运行的资源要求,即当用户需要加速时,可以增加行列,或者当集群资源不够时,可以减少行列,这些都需要根据自己所在MaxCompute Project的情况具体分析,包括下述如何加速任务的运行速度?均是提供一个通用的原则与思路。
如何加速任务的运行速度?
- 多类目情况下,任务整体分成两部分,一部分是单类目doc个数小于100万(默认阈值,可配置)的类目,另一部分是单类目doc个数大于100万的类目,所有小于100万的类目会一起用线性的方法进行检索,要加快这部分的速度,可以设置如下两个命令行参数 -category_row_num和-category_col_num。对于大类目部分的加速,可以通过设置这两个参数-row_num和-column_num。大体上的原则是增大列数和增加行数,这是由于增大列数,每列索引大小降低,单列检索速度提高;增大行数,每行 query 数量减少,同一批的检索速度提升,但是相应的资源的消耗就增加,具体需要结合业务与资源情况进行分析。详情请参考多类目检索。
- 非多类目情况下,可以通过设置-row_num和-column_num参数,提高任务整体的并发度。
为什么有query没有达到指定的topn?
在确认输入数据和系统运行没有问题之外,那么可能就是原始输入doc表的数据问题,Proxima CE默认采用的是hnsw算法构建索引,可能出现了构图不连通的极端情况,导致检索召回结果数量不够。解决方法:
- 可以通过降低recall 。该方法解决不彻底,如果是底层算法构图不连通,那么无论减少多少也可能不会得到200个,另外如果有,为特例case降低召回率对其他向量召回的效果也有影响,需要自行评估。
- 改变构造索引算法。例如采用HC方式构图,可通过-algo_model命令行参数指定。
- 补全topk。对于proxima2.4以上的版本,如果指定为HnswSearcher的hnsw的图算法,通过添加参数
{"proxima.hnsw.searcher.force_padding_result_enable" : True}补全search结果到指定的topk,对极端case的相似性的效果有一定影响,需要根据具体业务自行评估影响是否可接受。
Proxima CE可以设置cosine(余弦)距离吗?
Proxima CE支持cosine距离,且对内积的支持有优化,详情参考内积和余弦距离。
为什么提交的Proxima CE任务执行缓慢?
Proxima CE的主体是运行在MaxCompute MapReduce job,在任务正常编译运行的情况下,可能是MaxCompute调度和资源的问题,您可以通过申请链接或搜索(钉钉群号:11782920)加入MaxCompute开发者社区钉群联系MaxCompute技术支持团队获取支持。
创建临时表异常是什么问题?
该情况通常伴随invalid table name: xxx.yyy报错,主要原因是输出表命名出现问题。
对于Proxima CE的输入输出表,其命名需要符合MaxCompute的命名规定,注意名称中不能带点号.,该符号为MaxCompute的特殊字符,会导致后续流程错误。通常发生在创建output表为xxx.output_table_name的情况。
多个任务同时执行会有问题吗?
目前Proxima CE不支持相同输入doc的多个任务同时执行,因为多个任务同时执行会导致索引的坏写,比如A任务写了某份索引,B任务会覆盖,这样会导致各种问题,常见问题如下:
- 底层OSS Volume Filesystem相关的错误。
- build过程失败,提示
jni write index失败相关的错误。 - seek过程失败,提示
jni load index失败相关的错误。
为什么我运行的离线任务影响在线任务?
一般原因是离线任务和在线任务运行于同一个集群所导致。一般MaxCompute任务是混部集群上执行的,混部集群底层对离线、在线任务是共用的,因此可能出现离线任务占用了较多的集群资源,导致在线任务获取不到相应的资源,出现运行缓慢甚至失败等情况。一般建议:
- 限制离线任务的资源使用。可以限制任务的并发,通过指定Proxima离线任务的行列,也可以在自己的MaxCompute Project控制台加限制,这些都会导致离线任务运行变慢。
- 尽量分离两个任务。可以尝试分时使用集群,或者尝试申请新的资源。
RunLog与Logview是什么含义?有什么区别?
- RunLog技术支持接口人经常使用的运行日志、runLog通常是指在DataWorks节点运行后生成的运行日志下的全部内容。用户可以复制runlog信息发送给接口人定位问题。
 如果使用odpscmd运行脚本,通常也会在客户端生成运行日志,可以复制客户端上的全部日志发送给接口人,也可以将日志重定向到一个日志文件,将文件发送给接口人。
如果使用odpscmd运行脚本,通常也会在客户端生成运行日志,可以复制客户端上的全部日志发送给接口人,也可以将日志重定向到一个日志文件,将文件发送给接口人。 - logview
Logview是一个在MaxCompute Job提交后查看任务和Debug任务的工具,对于Proxima CE来讲,通常指的是在整体任务运行过程中,中间的SQLTask、MapReduce Task等运行时生成的Web日志状态信息,可以帮助用户查看基于MaxCompute运行的SQL、MR、Graph等任务的状态或调试运行出现的问题。详情请参考使用Logview查看作业运行信息。
任务被killed(ERROR: KILLED)怎么办?
这种情况一般出现的日志如下: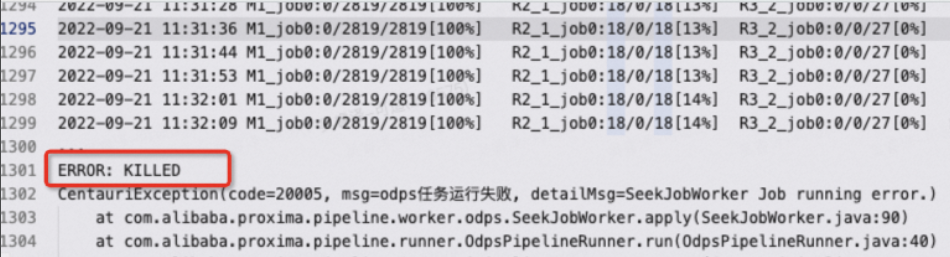 任务被kill有以下几种可能:
任务被kill有以下几种可能:
- 任务运行时间过久,MaxCompute上单个SQL任务默认运行超过24小时会被kill,您可以通过设置以下参数使SQL作业延长至72小时:
set odps.sql.job.max.time.hours=72; - 集群负载过大,资源被某个高优任务长期抢占,系统调度kill。
- 人为kill,可以询问Project Owner是否处理过,或者其他具有Project管理员权限的人是否处理过。
一般任务被kill了可以采用重跑方式,但是在集群负载比较大的时候建议采用以下两种方式。
- 提高任务优先级,通过设置-odps_task_priority参数改变任务优先级。详情请参考可选参数。重要 该操作风险较大,因为这样会抢占其他高优任务的资源,需要联系Project Owner 或者相关负责人,确定当前Project所在集群没有高优的在线或离线任务。
- 等待高优任务资源洪峰过后再执行Proxima CE任务。
为什么-odps_task_priority设置的任务优先级不起作用?
如果您的Project设置了基线优先级,当您设置的优先级高于基线优先级时,所设置的优先级将会失效。基线详情请参考基线管理。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/159898.html