
GPU监控2.0基于NVIDIA DCGM构建功能强大的GPU监控体系。本文介绍如何开启集群GPU监控。
前提条件
-
已创建托管GPU集群或专有GPU集群。具体操作,请参见创建GPU集群或创建专有GPU集群。
-
已开通ARMS。具体操作,请参见开通ARMS。
背景信息
对运维人员来说,实现对Kubernetes的大规模GPU设备可监测能力至关重要。通过监测GPU相关指标能够了解整个集群的GPU使用情况、健康状态、工作负载性能等,从而实现对异常问题的快速诊断、优化GPU资源的分配、提升资源利用率等。除运维人员以外,其他人员(例如数据科学家、AI算法工程师等)也能通过相关监控指标了解业务的GPU使用情况,以便进行容量规划和任务调度。
GPU监控1.0版本基于NVML(NVIDIA Management Library)库获取GPU指标,并通过Prometheus和Grafana将指标透传给用户,便于用户监控集群GPU资源的使用情况。但是,随着新一代NVIDIA GPU的发行,内部构造更加复杂,用户的使用场景也更加多样,GPU监控1.0对GPU的监控指标已经不能完全满足用户的需求。
新一代NVIDIA支持使用数据中心GPU管理器DCGM(Data Center GPU Manager)来管理大规模集群中的GPU,GPU监控2.0基于NVIDIA DCGM构建功能更强大的GPU监控体系。DCGM提供了种类丰富的GPU监控指标,有如下功能特性:
-
GPU行为监控
-
GPU配置管理
-
GPU Policy管理
-
GPU健康诊断
-
GPU级别统计和线程级别统计
-
NVSwitch配置和监控
使用限制
-
节点NVIDIA GPU驱动版本≥418.87.01。如果您需要进行GPU Profiling,则节点NVIDIA GPU驱动版本≥450.80.02。关于GPU Profiling的更多信息,请参见Feature Overview。
-
节点的NVIDIA GPU驱动版本不能为5XX系列(驱动版本以5开头,例如:510.47.03)。
说明
-
目前使用的DCGM版本为2.3.6,该版本的DCGM在5XX系列的NVIDIA GPU驱动上工作存在一些问题,具体请参见dcgm-exporter collects metrics incorrectly?。
-
您可以通过SSH登录GPU节点,执行
nvidia-smi命令,查看安装的GPU驱动版本。更多信息,请参见通过SSH连接ACK专有集群的Master节点。
-
-
不支持对NVIDIA MIG进行监控。
注意事项
当前DCGM可能会存在内存泄漏的问题,已通过为Exporter所在的Pod设置resources.limits来规避这个问题。当内存使用达到Limits限制时,Exporter会重启(一般一个月左右重启一次),重启后正常上报指标,在重启后的几分钟内,Grafana可能会出现某些指标的显示异常(例如节点数突然变多),之后恢复正常。问题详情请参见The DCGM has a memory leak?。
费用说明
在ACK集群中使用ack-gpu-exporter组件时,默认情况下它产生的阿里云Prometheus监控指标被视为基础指标,并且是免费的。然而,如果您需要调整监控数据的存储时长,即保留监控数据的时间超过阿里云为基础监控服务设定的默认保留期限,这可能会产生额外的费用。关于阿里云Prometheus的自定义收费策略,请参见计费概述。
操作步骤
-
开启阿里云Prometheus监控。
请确保ack-arms-prometheus组件版本≥1.1.7、GPU组件≥v2。
说明
-
查看或升级ack-arms-prometheus:在容器服务管理控制台的集群详情左侧栏单击运维管理 > 组件管理,在页面右侧搜索arms,在ack-arms-prometheus卡片中查看或升级版本。
-
查看或升级GPU组件:在容器服务管理控制台的集群详情左侧栏单击运维管理 > Prometheus监控,在页面右上方单击跳转到Prometheus服务,在大盘列表查看或升级GPU相关的监控大盘版本。
-
-
验证阿里云Prometheus的GPU监控能力。
-
部署tensorflow-benchmark应用。
-
使用以下YAML内容,创建tensorflow-benchmark.yaml文件。
apiVersion: batch/v1 kind: Job metadata: name: tensorflow-benchmark spec: parallelism: 1 template: metadata: labels: app: tensorflow-benchmark spec: containers: - name: tensorflow-benchmark image: registry.cn-beijing.aliyuncs.com/ai-samples/gpushare-sample:benchmark-tensorflow-2.2.3 command: - bash - run.sh - --num_batches=50000 - --batch_size=8 resources: limits: nvidia.com/gpu: 1 #申请1张GPU卡。 workingDir: /root restartPolicy: Never -
执行以下命令,在GPU节点上部署tensorflow-benchmark应用。
kubectl apply -f tensorflow-benchmark.yaml -
执行以下命令,查看Pod状态。
kubectl get po预期输出:
NAME READY STATUS RESTARTS AGE tensorflow-benchmark-k*** 1/1 Running 0 114s由预取输出得到,当前Pod处于
Running状态。
-
-
查看GPU监控大盘。
-
登录容器服务管理控制台,在左侧导航栏单击集群。
-
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择运维管理 > Prometheus监控。
-
在Prometheus监控页面,单击GPU监控页签,然后单击集群GPU监控-集群维度页签。
从集群监控大盘中可以看到GPU Pod运行在节点cn-beijing.192.168.10.163上。
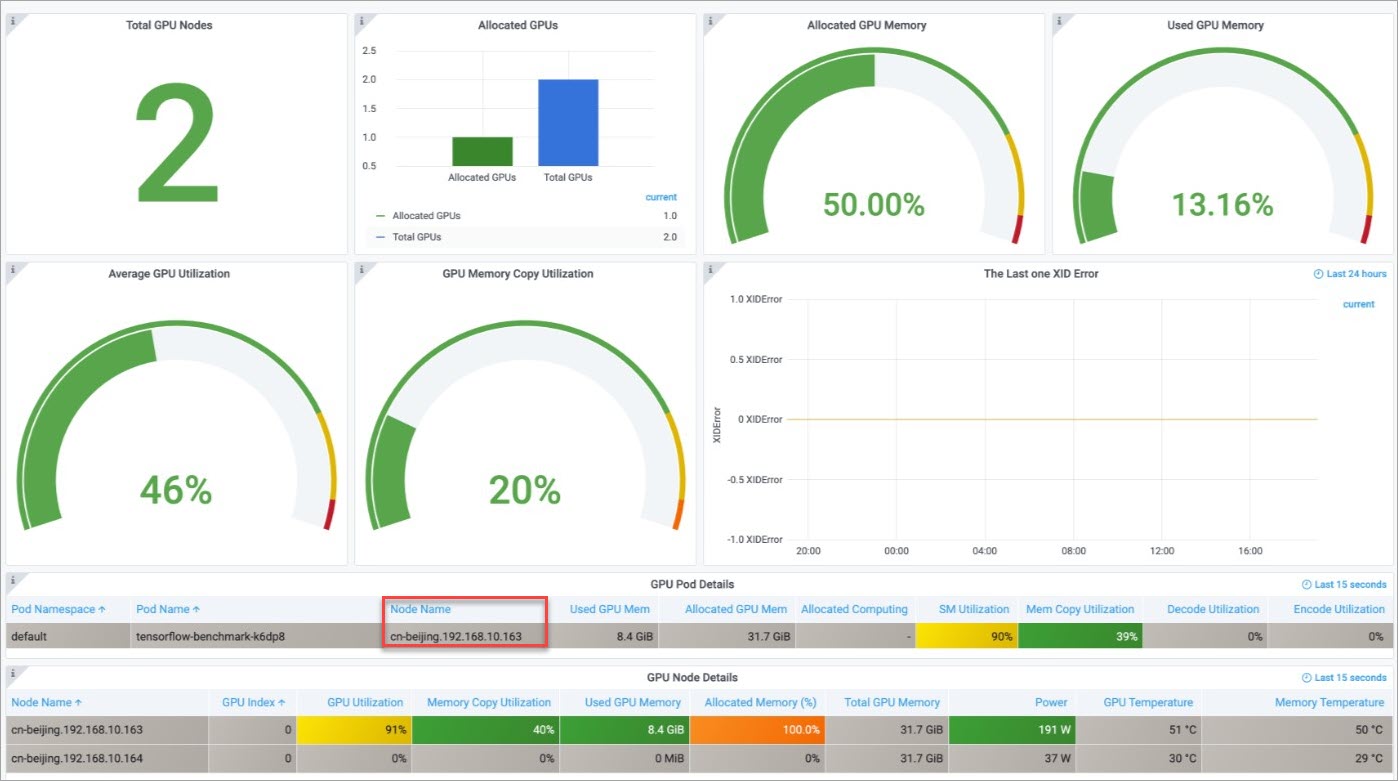

-
单击集群GPU监控-节点维度页签,选择gpu_node为cn-beijing.192.168.10.163,查看该节点的GPU详细信息。
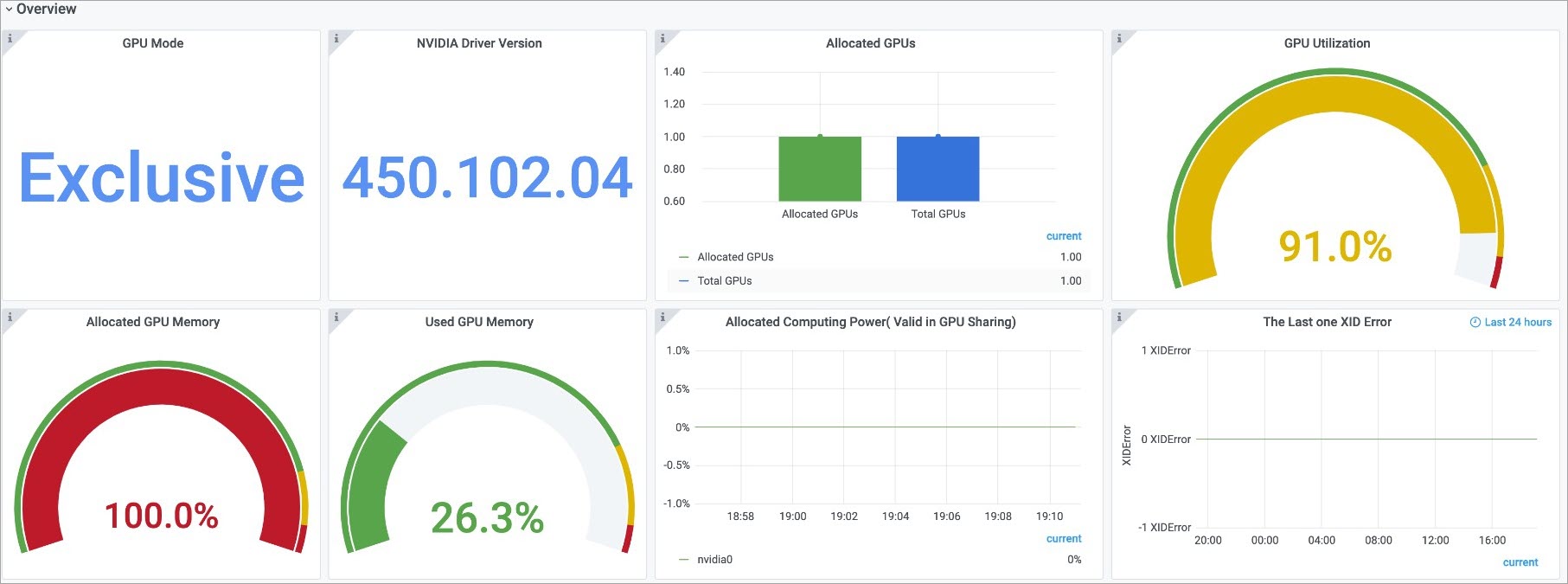
-
-
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/158729.html