
RDS PostgreSQL支持pgvector插件,提供了一个新的数据类型,能够方便快捷地对高维向量进行检索,是一款功能强大的向量相似度匹配搜索插件。
背景
RDS PostgreSQL支持pgvector插件,能够存储向量类型数据,并实现向量相似度匹配,为AI产品提供底层数据支持。
pgvector主要提供如下能力:
-
支持数据类型vector,能够对向量数据存储以及查询。
-
支持精确和近似最近邻搜索(ANN,Approximate Nearest Neighbor),其距离或相似度度量方法包括欧氏距离(L2)、余弦相似度(Cosine)以及内积运算(Inner Product)。索引构建支持HNSW索引、并行索引IVFFlat、向量的逐元素乘法、L1距离函数以及求和聚合。
-
最大支持创建16000维度的向量,最大支持对2000维度的向量建立索引。
相关概念及实现原理
嵌入
嵌入(embedding)是指将高维数据映射为低维表示的过程。在机器学习和自然语言处理中,嵌入通常用于将离散的符号或对象表示为连续的向量空间中的点。
在自然语言处理中,词嵌入(word embedding)是一种常见的技术,它将单词映射到实数向量,以便计算机可以更好地理解和处理文本。通过词嵌入,单词之间的语义和语法关系可以在向量空间中得到反映。
说明
您可以前往如下常见的嵌入工具/库官方文档了解更多内容:
-
Word2Vec
-
fastText
-
BERT
实现原理
-
嵌入可以将文本、图像、音视频等信息在多个维度上抽象,转化为向量数据。
-
pgvector提供vector数据类型,使RDS PostgreSQL数据库具备了存储向量数据的能力。
-
pgvector可以对存储的向量数据进行精确搜索以及近似最近邻搜索。
假设需要将苹果、香蕉、猫三个对象存储到数据库中,并使用pgvector计算相似度,实现步骤如下:
-
先使用嵌入,将苹果、香蕉、猫三个对象转化为向量,假设以二维嵌入为例,结果如下:
苹果:embedding[1,1] 香蕉:embedding[1.2,0.8] 猫:embedding[6,0.4] -
将嵌入转化的向量数据存储到数据库中。如何将二维向量数据存储到数据库中,具体请参见使用示例。
在二维平面中,三个对象分布如下:


对于苹果和香蕉,都属于水果,因此在二维坐标视图中二者的距离更接近,而香蕉与猫属于两个完全不同的物种,因此距离较远。
可以对水果的属性进一步细化,比如水果的颜色,产地,味道等,每一个属性都是一个维度,也就代表了维度越高,对于该信息的分类就更细,也就越有可能搜索出更精确的结果。
应用场景
-
存储向量类型数据。
-
向量相似度匹配搜索。
前提条件
RDS PostgreSQL实例需满足以下要求:
-
实例大版本为PostgreSQL 14或以上。
-
实例内核小版本为20230430或以上。
说明
如需升级实例大版本或内核小版本,请参见升级数据库大版本或升级内核小版本。
插件管理
-
创建插件
CREATE EXTENSION IF NOT EXISTS vector; -
删除插件
DROP EXTENSION vector; -
更新插件
ALTER EXTENSION vector UPDATE [ TO new_version ]说明
new_version配置为pgvector的版本,pgvector的最新版本号及相关特性,请参见pgvector官方文档。
使用示例
如下仅是对pgvector的简单使用示例,更多使用方法,请参见pgvector官方文档。
-
创建一个存储vector类型的表(items),用于存储embeddings。
CREATE TABLE items ( id bigserial PRIMARY KEY, item text, embedding vector(2) );说明
上述示例中,以二维为例,pgvector最大支持创建16000维度的向量。
-
将向量数据插入表中。
INSERT INTO items (item, embedding) VALUES ('苹果', '[1, 1]'), ('香蕉', '[1.2, 0.8]'), ('猫', '[6, 0.4]'); -
使用余弦相似度操作符
计算香蕉与苹果、猫之间的相似度。SELECT item, 1 - (embedding '[1.2, 0.8]') AS cosine_similarity FROM items ORDER BY cosine_similarity DESC;说明
-
在上述示例中,使用公式
cosine_similarity = 1 - cosine_distance进行计算,距离越近,相似度越高。 -
您也可以使用欧氏距离操作符
或内积运算操作符计算相似度。
结果示例:
item | cosine_similarity ------+-------------------- 香蕉 | 1 苹果 | 0.980580680748848 猫 | 0.867105556566985在上述结果中:
-
香蕉结果为1,表示完全匹配。
-
苹果的结果为0.98,表示苹果与香蕉高度相似。
-
猫的结果为0.86,表示猫与香蕉相似度较低。
说明
您可以在实际业务中设置一个合适的相似度阈值,将相似度较低的结果直接排除。
-
-
为了提高相似度的查询效率,pgvector支持为向量数据建立索引,执行如下语句,为embedding字段建立索引。
CREATE INDEX ON items USING ivfflat (embedding vector_cosine_ops) WITH (lists = 100);各参数说明如下:
参数/取值
说明
items
添加索引的表名。
embedding
添加索引的列名。
vector_cosine_ops
向量索引方法中指定的访问方法。
-
余弦相似性搜索,使用
vector_cosine_ops。 -
欧氏距离,使用
vector_l2_ops。 -
内积相似性,使用
vector_ip_ops。
lists = 100
lists参数表示将数据集分成的列表数,该值越大,表示数据集被分割得越多,每个子集的大小相对较小,索引查询速度越快。但随着lists值的增加,查询的召回率可能会下降。
说明
-
召回率是指在信息检索或分类任务中,正确检索或分类的样本数量与所有相关样本数量之比。召回率衡量了系统能够找到所有相关样本的能力,它是一个重要的评估指标。
-
构建索引需要的内存较多,当lists参数值超过2000时,会直接报错
ERROR: memory required is xxx MB, maintenance_work_mem is xxx MB,您需要设置更大的maintenance_work_mem才能为向量数据建立索引,该值设置过大实例会有很高的OOM风险。设置方法,请参见设置实例参数。 -
您需要通过调整lists参数的值,在查询速度和召回率之间进行权衡,以满足具体应用场景的需求。
-
-
您可以使用如下两种方式之一来设置ivfflat.probes参数,指定在索引中搜索的列表数量,通过增加ivfflat.probes的值,将搜索更多的列表,可以提高查询结果的召回率,即找到更多相关的结果。
-
会话级别
SET ivfflat.probes = 10; -
事务级别
BEGIN; SET LOCAL ivfflat.probes = 10; SELECT ... COMMIT;
ivfflat.probes的值越大,查询结果的召回率越高,但是查询的速度会降低,根据具体的应用需求和数据集的特性,lists和ivfflat.probes的值可能需要进行调整以获得最佳的查询性能和召回率。
说明
如果ivfflat.probes的值与创建索引时指定的lists值相等时,查询将会忽略向量索引并进行全表扫描。在这种情况下,索引不会被使用,而是直接对整个表进行搜索,可能会降低查询性能。
-
性能数据
为向量数据设置索引时,需要根据实际业务数据量及应用场景,在查询速度和召回率之间进行权衡,您可以参考如下测试结果进行性能调优。
以下基于RDS PostgreSQL实例,分别展示向量数据以及索引在不同数据量下占用的存储空间情况,以及在设置不同的lists值以及probes值对查询效率以及召回率的影响。
测试数据准备
-
创建测试数据库。
CREATE DATABASE testdb; -
安装插件。
CREATE EXTENSION IF NOT EXISTS vector; -
生成固定长度的随机向量作为测试数据。
CREATE OR REPLACE FUNCTION random_array(dim integer) RETURNS DOUBLE PRECISION[] AS $$ SELECT array_agg(random()) FROM generate_series(1, dim); $$ LANGUAGE SQL VOLATILE COST 1; -
创建一个存储1536维向量的表。
CREATE TABLE vtest(id BIGINT, v VECTOR(1536)); -
向表中插入数据。
INSERT INTO vtest SELECT i, random_array(1536)::VECTOR(1536) FROM generate_series(1, 100000) AS i; -
建立索引。
CREATE INDEX ON vtest USING ivfflat(v vector_cosine_ops) WITH(lists = 100);
测试步骤
为避免网络延迟等因素对测试数据的影响,推荐使用内网连接地址,本示例是在与RDS PostgreSQL同地域、同VPC下的ECS中进行测试。
-
使用一个随机向量,与vtest表中的数据进行相似度比对,获取比对结果中最相似的50条记录。
您需要创建一个sql文件,然后写入如下内容,用于后续压测时使用。
WITH tmp AS ( SELECT random_array(1536)::VECTOR(1536) AS vec ) SELECT id FROM vtest ORDER BY v (SELECT vec FROM tmp) LIMIT FLOOR(RANDOM() * 50); -
使用pgbench进行压测。
如下命令需要在命令行窗口执行,请确保已安装PostgreSQL客户端(本示例以15.1为例),pgbench是在PostgreSQL上运行基准测试的简单程序。该命令的更多用法,请参见PostgreSQL官方文档。
pgbench -f ./test.sql -c6 -T60 -P5 -U testuser -h pgm-bp****.pg.rds.aliyuncs.com -p 5432 -d testdb各参数及说明如下:
参数/取值
说明
-f ./test.sql
指定测试脚本文件的路径和文件名。
./test.sql仅为示例,您需要根据实际情况修改路径及文件名。-c6
设置并发客户端数。-c表示指定并发客户端数,6表示本示例指定了6个并发客户端来执行测试。
-T60
设置测试时间。-T表示指定测试的运行时间,60表示本示例指定测试将运行60秒。
-P5
设置脚本参数。表示本示例中每5秒显示一次进程报告。
-U testuser
指定数据库用户。testuser需要替换为您的数据库用户名。
-h pgm-bp****.pg.rds.aliyuncs.com
指定RDS PostgreSQL实例的内网连接地址。
-p 5432
指定RDS PostgreSQL实例的内网端口。
-d testdb
指定连接的数据库,本示例以testdb为例。
测试结果
向量数据、索引数据占用的存储空间以及TPS与数据量之间的测试结果
|
数据量(单位:万行) |
table size(单位:MB) |
index size(单位:MB) |
Latency(单位:ms) |
TPS(单位:个) |
|
10 |
796 |
782 |
15.7 |
380 |
|
30 |
2388 |
2345 |
63 |
94 |
|
50 |
3979 |
3907 |
74 |
80 |
|
80 |
6367 |
6251 |
90 |
66 |
|
100 |
7958 |
7813 |
105 |
56 |
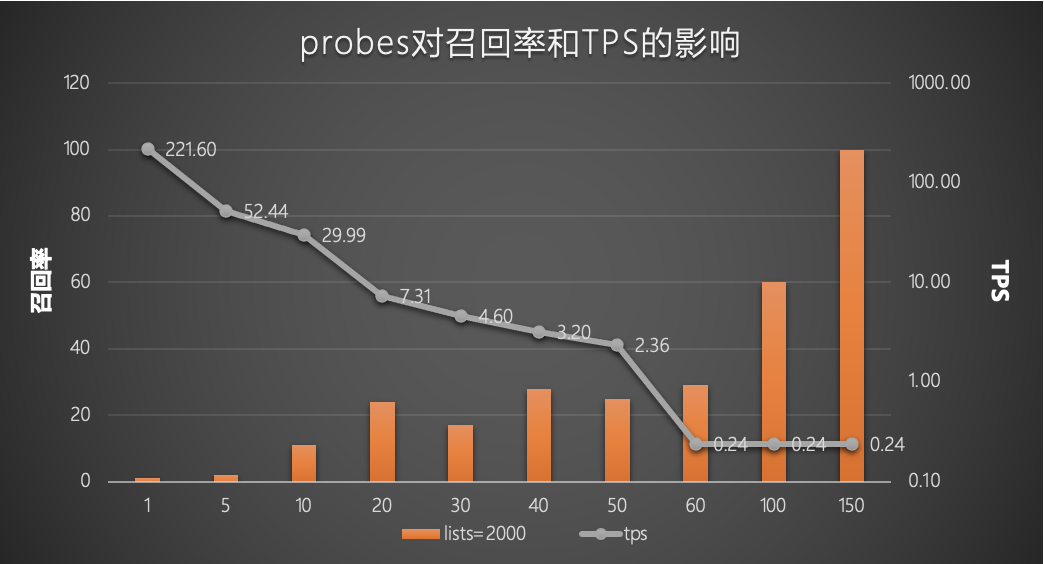
lists固定时probes对查询效率以及召回率的影响
当lists固定为2000,表中数据量为100万行时,probes越大召回率越高,TPS越低。
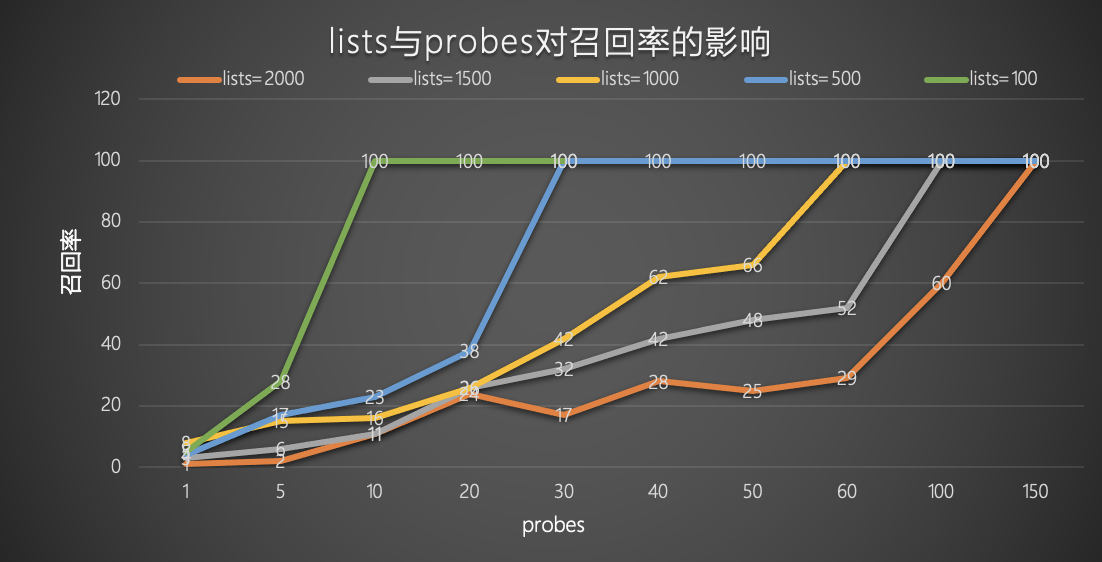
probes固定时lists对查询效率以及召回率的影响
当probes固定为20,表中数据量为100万行时,lists越大,召回率越低,TPS越高

测试结论
-
lists的值对索引占用的存储空间影响微乎其微,和表中的数据量有直接的关系。
-
lists和probes对查询效率以及召回率起着相反的作用,因此合理地设置这两个值可以在查询效率以及召回率上达到一个平衡。
根据表中行数(rows)的不同,建议设置的lists和probes值如下:
-
小于等于100万行:
lists = rows / 1000、probes = lists / 10 -
大于100万行:
lists = sqrt(rows)、probes = sqrt(lists)说明
sqrt表示开方运算。
-
最佳实践
基于RDS PostgreSQL构建由LLM驱动的专属ChatBot
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:https://www.yunxiaoer.com/155238.html