
简介
组件介绍
Kuberentes 的调度逻辑为按照 Pod 的 Request 进行调度。节点上的可调度资源会被 Pod 的 Request 量占用,且无法腾挪。原生节点专用调度器是容器服务 TKE 基于 Kubernetes 原生 Kube-scheduler Extender 机制实现的调度器插件,可以虚拟放大节点的容量,用来解决节点资源都被占用,但本身利用率很低的问题。
部署在集群内的 Kubernetes 对象
| Kubernetes 对象名称 | 类型 | 请求资源 | 所属 Namespace |
| crane-scheduler-controller | Deployment | 每个实例 CPU: 200m Memory:200Mi,共计1个实例 | kube-system |
| crane-descheduler | Deployment | 每个实例 CPU: 200m Memory:200Mi,共计1个实例 | kube-system |
| crane-scheduler | Deployment | 每个实例 CPU: 200m Memory:200Mi,共计3个实例 | kube-system |
| crane-scheduler-controller | Service | – | kube-system |
| crane-scheduler | Service | – | kube-system |
| crane-scheduler | ClusterRole | – | kube-system |
| crane-descheduler | ClusterRole | – | kube-system |
| crane-scheduler | ClusterRoleBinding | – | kube-system |
| crane-descheduler | ClusterRoleBinding | – | kube-system |
| crane-scheduler-policy | ConfigMap | – | kube-system |
| crane-descheduler-policy | ConfigMap | – | kube-system |
| ClusterNodeResourcePolicy | CRD | – | – |
| CraneSchedulerConfiguration | CRD | – | – |
| NodeResourcePolicy | CRD | – | – |
| crane-scheduler-controller-mutating-webhook | MutatingWebhookConfiguration | – | – |
应用场景
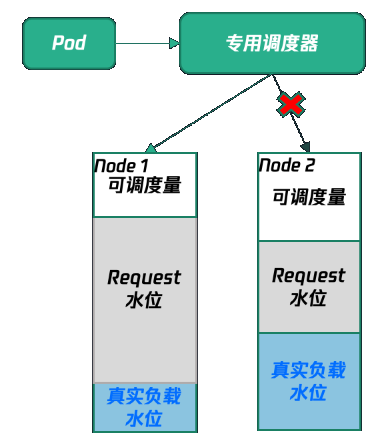
场景1:解决节点装箱率高但利用率低的问题
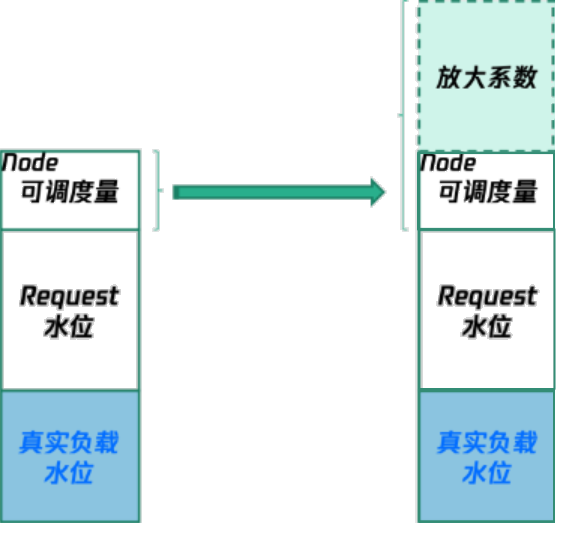
说明:基本概念如下:装箱率:节点上所有 Pod 的 Request 之和除以节点实际的规格。n利用率:节点上所有 Pod 得真实用量之和除以节点实际的规格。Kubernetes 原生调度器是基于 Pod Request 资源进行调度,因此,即使此时节点上的真实用量很低,但节点上所有 Pod 的 Request 之和接近节点实际规格,也无法调度新的 Pod 上来,造成较大的资源浪费。并且,业务通常为了保证自己服务的稳定性,倾向申请过量的资源,即较大的 Request,导致节点资源被占用,无法腾挪。此时节点的装箱率很高,但实际资源利用率较低。此时可以使用原生节点专用调度器,虚拟放大节点的 CPU 和内存的规格,使得节点可调度资源被虚拟放大,可以调度进更多的 Pod。示例图如下所示:n

场景2:节点水位线的设置
节点的水位线设置用于保障节点的稳定性的同时,设置节点的目标利用率:n
调度时的水位控制:设定原生节点目标资源利用率,保障稳定性。Pod 调度时,高于该水位的节点将不被选中。运行时的水位控制:设定当前原生节点目标资源利用率,保障稳定性。节点运行时,高于该水位的节点可能引发驱逐。因为驱逐本身是高危动作,因此注意以下事项:
注意事项
1. 为避免驱逐关键的 Pod,该功能默认不驱逐 Pod。对于可以驱逐的 Pod,用户需要显示给判断 Pod 所属 workload。例如,statefulset、deployment 等对象设置可驱逐 annotation:
descheduler.alpha.kubernetes.io/evictable: 'true'
2. 建议为集群开启事件持久化,以便更好地监控组件异常以及故障定位。驱逐 Pod 时会产生对应事件,可根据 reason 为 “Descheduled” 类型的事件观察 Pod 是否被重复驱逐。3. 驱逐动作对节点的要求:集群需要有3个及以上的低负载原生节点,其中低负载定义是 Node 负载小于运行时的水位控制。4. 节点维度过滤后,开始驱逐 Node 上 Workload,此时为 Workload 级别的过滤,需要工作负载的副本数大于等于2或者是 Workload spec replicas 的一半及以上。5. 在 Pod 维度上,如果 Pod 的负载大于节点的驱逐水位,则不可驱逐,以避免驱逐到其他节点造成其他节点负载过高。
场景3:指定命名空间下的 Pod 在下次调度时只调度到原生节点上
原生节点是由腾讯云 TKE 容器服务团队面向 Kubernetes 环境推出的全新节点类型,依托腾讯云千万核容器运维的技术沉淀,为用户提供原生化、高稳定、快响应的 K8s 节点管理能力。原生节点支持节点规格放大,Request 推荐等能力,因此为了充分利用原生节点的优势,建议您将工作负载调度到原生节点上。在开启原生节点调度器时,您可以选择命名空间,指定命名空间下的 Pod 在下次调度时只调度到原生节点上。注意若此时原生节点资源不足,会导致 Pod Pending。
限制条件
该功能仅支持原生节点,更多请参考 原生节点概述。需要保证 Kubernetes 版本为 v1.22.5-tke.8,v1.20.6-tke.24,v1.18.4-tke.28,v1.16.3-tke.30 及以上。集群版本升级请参考 升级集群。
风险控制
该组件卸载后,只会删除原生节点专用调度器有关调度逻辑,不会对原生 Kube-Scheduler 的调度功能有任何影响。原生节点上存量的 Pod 因为已经调度,不受影响。但原生节点上 kubelet 重启时,可能会引发 Pod 的驱逐,因为此时可能原生节点上 Pod 的 Request 之和可能大于原生真实的规格。当调低放大系数时,原生节点上存量的 Pod 因为已经调度,不受影响。但原生节点上 kubelet 重启时,可能会引发 Pod 的驱逐,因为此时可能原生节点上 Pod 的 Request 之和可能大于原生节点当前放大后的规格。用户看到 Kubernetes 集群中的 Node 资源和对应的 CVM 节点资源不一致。未来可能会发生负载过高、稳定性问题。节点规格放大以后,节点 kubelet 层和资源 QoS 相关模块可能受到影响,例如 kubelet 绑核,原来4核的节点被当做8核调度,Pod 绑核可能受到影响。
节点规格放大原理
用户设定节点规格放大系数以后,后台部署 Crane Resource Controller,该 Controller 会获取该系数,并不断的校验 Node 的系数是否和用户指定的系数一致。详细步骤如下:1. 用户提交 ClusterNodeResourcePolicy CRD,通过 Label Selector 来指定需要放大的节点,Label Selector 选中的节点,将统一采用节点放大的参数。2. Crane Resource Controller 会读取 CRD 中指定的静态超卖参数,为每个节点 Patch Node Annotation,Controller 会不停的将放大系数记录到 Node 的 Annotation 中, Reconcile Loop 保持最终一致性。3. Kubelet 在上报节点资源的时候,请求会被 Controller 的 Webhook 拦截,并将其 Capacity 和 Allocatable 进行虚拟放大,得到新的 Capacity 和 Allocatable。4. 用户调度器就会通过新 Capacity 和 Allocatable 调度,从而调度更多的 Pod。n

容器服务官网1折活动,限时活动,即将结束,速速收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利。同意关联立享优惠
转转请注明出处:https://www.yunxiaoer.com/148171.html