
EasyTransfer旨在帮助自然语言处理(NLP)场景的迁移学习开发者方便快捷地构建迁移学习模型。本文以文本分类为例,为您介绍如何在PAI-DSW中使用EasyTransfer,包括启动训练、评估模型、预测模型及导出并部署模型。
前提条件
已创建PAI-DSW实例,且该实例满足版本限制,详情请参见创建及管理DSW实例和使用限制。
说明
建议创建PAI-DSW实例时选择GPU规格。
背景信息
迁移学习(Transfer Learning)的核心的思想是将一个环境中学到的知识应用到新环境的学习任务中。面向自然语言处理(NLP)场景的迁移学习在工业上拥有大量需求,且不断涌现新的领域,而传统的机器学习需要对每个领域都积累大量训练数据,这将耗费大量的人力和物力。如果能够利用现有的训练数据帮助学习新领域的学习任务,将会大幅度减少标注的人力和物力。为了方便用户快速搭建面向NLP场景的迁移学习模型,PAI团队推出了深度迁移学习框架EasyTransfer。
使用限制
EasyTransfer仅支持如下Python版本和镜像版本:
-
Python版本:Python 2.7或Python 3.4及其以上版本。
-
镜像版本:选择官方镜像tensorflow:1.12PAI-gpu-py36-cu101-ubuntu18.04。
步骤一:准备数据
- 进入PAI-DSW开发环境。
- 登录PAI控制台。
- 在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
- 在页面左上方,选择使用服务的地域。
- 在左侧导航栏,选择模型开发与训练 > 交互式建模(DSW)。
- 可选:在交互式建模(DSW)页面的搜索框,输入实例名称或关键字,搜索实例。
- 单击需要打开的实例操作列下的打开。
-
在PAI-DSW开发环境,单击顶部菜单栏中的Terminal,按照界面操作指引打开Terminal。
-
在Terminal中,使用如下命令下载Demo数据集。
wget http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/tutorial/ez_text_classify/zqkd_sample/train.csv wget http://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/tutorial/ez_text_classify/zqkd_sample/dev.csv说明
此处仅使用少量样本进行演示,您训练自己的新闻分类模型时,需要使用更多的样本进行模型训练。
步骤二:启动训练任务(在当前目录)
使用如下命令,启动训练任务。
easy_transfer_app \
--mode=train \
--modelName=text_classify_bert \
--inputTable="./train.csv,./dev.csv" \
--inputSchema=content:str:1,label:str:1 \
--firstSequence=content \
--labelName=label \
--labelEnumerateValues="教育,三农,娱乐,健康,美文,搞笑,美食,财经,科技,旅游,汽车,时尚,科学,文化,房产,热点,母婴,家居,体育,国际,育儿,宠物,游戏,健身,职场,读书,艺术,动漫" \
--sequenceLength=128 \
--checkpointDir=./classify_models \
--batchSize=64 \
--numEpochs=3 \
--optimizerType=adam \
--learningRate=3e-5 \
--advancedParameters='\
pretrain_model_name_or_path=pai-bert-base-zh \
'命令中的训练参数介绍如下表所示,更多详细的参数解释请参见EasyTransfer用户文档。
|
参数 |
是否必选 |
描述 |
默认值 |
类型 |
|
mode |
是 |
模式,取值包括:
|
无 |
STRING |
|
modelName |
否 |
App模型名称,支持以下模型:
|
text_match_bert |
STRING |
|
inputTable |
是 |
输入的训练表,使用英文逗号(,)分隔。例如 |
无 |
STRING |
|
inputSchema |
是 |
输入文件的列Schema,取值格式为列名:类型:长度。其中:
|
无 |
STRING |
|
firstSequence |
是 |
第一个文本序列在输入格式中对应的列名。 |
无 |
STRING |
|
labelName |
否 |
标签在输入格式中对应的列名。 |
空字符串(”) |
STRING |
|
labelEnumerateValues |
否 |
标签枚举值,支持以下两种格式:
|
空字符串(”) |
STRING |
|
sequenceLength |
否 |
序列整体最大长度,取值范围1~512。 |
128 |
INT |
|
checkpointDir |
是 |
模型存储路径所在目录。例如 |
无 |
STRING |
|
batchSize |
否 |
训练时的批处理大小。如果是多卡训练,则为每个GPU上的批处理大小。 |
32 |
INT |
|
numEpochs |
否 |
训练总Epoch的数量。 |
1 |
INT |
|
optimizerType |
否 |
优化器类型,取值包括:
|
adam |
STRING |
|
learningRate |
否 |
学习率。 |
2e-5 |
FLOAT |
|
advancedParameters |
否 |
其他高级参数,详情请参见下方的高级参数表格。 |
不涉及 |
STRING |
关于高级参数的介绍如下表所示。
|
参数 |
是否必选 |
描述 |
默认值 |
类型 |
|
pretrain_model_name_or_path |
否 |
预训练模型。不仅支持EasyTransfer下的所有预训练模型,也支持用户自己的预训练模型OSS地址。 |
pai-bert-base-zh |
STRING |
步骤三:评估模型
训练完成后,您可以使用如下命令测试或评估训练结果。
easy_transfer_app \
--mode=evaluate \
--inputTable=./dev.csv \
--checkpointPath=./classify_models/model.ckpt-64 \
--batchSize=10命令中的参数介绍如下表所示。
|
参数 |
是否必选 |
描述 |
默认值 |
类型 |
|
mode |
是 |
模式,取值包括:
|
无 |
STRING |
|
inputTable |
是 |
输入的评估表,使用英文逗号(,)分隔。例如 重要 评估集的列Schema必须与训练集的保持一致。 |
无 |
STRING |
|
checkpointPath |
是 |
模型CKPT存储路径所在的目录。例如 |
无 |
STRING |
|
batchSize |
否 |
评估时的批处理大小。如果是多卡场景,则为每个GPU上的批处理大小。 |
32 |
INT |
步骤四:预测模型
训练完成后,您可以使用如下命令对文件(可以没有标签)进行预测。
easy_transfer_app \
--mode=predict \
--inputSchema=content:str:1,label:str:1 \
--inputTable=dev.csv \
--outputTable=dev.pred.csv \
--firstSequence=content \
--appendCols=label \
--outputSchema=predictions,probabilities,logits \
--checkpointPath=./classify_models/ \
--batchSize=100命令中的参数介绍如下表所示。
|
参数 |
是否必选 |
描述 |
默认值 |
类型 |
|
mode |
是 |
模式,取值包括:
|
无 |
STRING |
|
inputTable |
是 |
输入的待预测表。例如 |
无 |
STRING |
|
outputTable |
是 |
预测结果的输出表。例如 |
无 |
STRING |
|
inputSchema |
是 |
输入文件的列Schema,取值格式为列名:类型:长度。其中:
|
无 |
STRING |
|
firstSequence |
是 |
第一个文本序列在输入格式中对应的列名。 |
无 |
STRING |
|
appendCols |
否 |
输入表中需要添加到输出表的列。 |
空字符串(”) |
STRING |
|
outputSchema |
否 |
选择输出数据中需要的预测值,多个选择项之间以英文逗号(,)分隔。支持以下三种格式:
|
predictions |
STRING |
|
checkpointPath |
是 |
模型存储路径所在目录。例如 |
无 |
STRING |
|
batchSize |
否 |
训练时的批处理大小。如果是多卡训练,则为每个GPU上的批处理大小。 |
32 |
INT |
步骤五:导出模型并在线部署PAI-EAS服务
-
导出模型。
训练结束后,默认会导出最后一个Checkpoint生成的variables和saved_model.pb文件。如果您需要导出其他Checkpoint的训练结果,则可以使用如下命令。
easy_transfer_app \ --mode=export \ --exportType=app_model \ --checkpointPath=./classify_models/model.ckpt-64 \ --exportDirBase=./export_model \ --batchSize=100命令中的参数介绍如下表所示。
参数
是否必选
描述
默认值
类型
mode
是
模式,取值包括:
-
train:训练
-
evaluate:评估
-
predict:预测
-
export:导出
无
STRING
exportType
是
导出的类型,取值包括:
-
app_model: 导出Finetune模型。
-
ez_bert_feat:导出文本向量化组件所需模型。
无
STRING
checkpointPath
是
模型CKPT存储路径所在的目录。
无
STRING
exportDirBase
是
导出模型的目录。
无
STRING
batchSize
否
评估时的批处理大小。如果是多卡场景,则为每个GPU上的批处理大小。
32
INT
-
-
打包模型文件。
打包输出目录中的variables、saved_model.pb、vocab.txt及定义用户输入的label_mapping文件。例如本文中新闻分类的label_mapping文件为label_mapping.json,该文件中的标签ID必须为INT类型,且顺序与训练时的labelEnumerateValues参数的顺序一致。label_mapping.json的内容示例如下。
{"教育": 0, "三农": 1, ..., "动漫": 27}您也可以从训练指定的checkpointDir目录下找到label_mapping.json文件。
打包得到的文件如下所示。
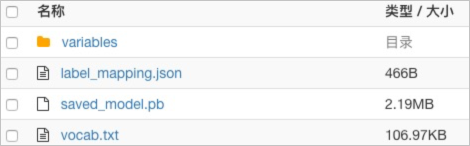

-
上传模型文件至OSS,得到模型的OSS地址。例如
oss://xxx/your_model.zip。 -
部署模型,详情请参见EasyTransfer Processor。
内容没看懂? 不太想学习?想快速解决? 有偿解决: 联系专家
阿里云企业补贴进行中: 马上申请
腾讯云限时活动1折起,即将结束: 马上收藏
同尘科技为腾讯云授权服务中心。
购买腾讯云产品享受折上折,更有现金返利:同意关联,立享优惠
转转请注明出处:http://www.yunxiaoer.com/163780.html